
Parametric Modelling: Killer Apps for Linux Clusters
After nearly 20 years of research and development, there still has not been a wide-scale uptake of parallel computing technology. However, with recent advances in PC-based hardware and networking products, it is now possible to build a parallel computer from industry-standard, commercial, off-the-shelf products. Approaches such as those used in the Beowulf project (see http://beowulf.gsfc.nasa.gov/) advocate the connection of a number of Linux-based workstations, or high-end PCs, with high-speed networking hardware and appropriate software as the basis for a viable parallel computer. These systems support parallel programming using a message-passing methodology. In spite of this, there is still a dearth of good, widespread, parallel applications.
I believe there are two main reasons for the lack of applications. First, rapid changes in hardware architecture and a lack of software standards have made it difficult to develop robust, portable and efficient software. Second, much of the effort in developing a parallel program has been focused on low-level programming issues, such as how to support message passing in a portable manner. Consequently, insufficient attention has been given to high-level parallel programming environments built around niche application domains. Thus, application developers building parallel programs have been forced to consider very low-level issues, which are far removed from their base disciplines such as physics, chemistry and commerce.
In 1994, some of my colleagues and I began a research project called Nimrod, with the goal of producing a parallel problem-solving environment for a particular niche class of application, namely parametric modelling experiments. We were motivated to do the work for this project after experiencing the frustration of trying to perform some large-scale computational-modelling experiments on a distributed computer using the available tools. We were either forced to perform the work manually, or use low-level parallel programming tools like PVM (Parallel Virtual Machine) and batch queueing systems. Neither of these automated methods matched the type of work we wanted to perform, which at the time was modelling air pollution and exploring different control strategies. The project led to the development of a commercial tool called EnFuzion (see http://www.turbolinux.com/), which runs on a variety of UNIX platforms including Linux. It has also led to a number of very successful applications, with demonstrated returns to the researchers involved. Other types of problems can be formulated as parametric experiments, and thus can also take advantage of EnFuzion.
Parametric modelling is concerned with computing a function value with different input parameter values. The results make it possible to explore different parameters and design options. The broad approach has been made very popular by the use of spreadsheet software, in which many different options can be rapidly evaluated and the results displayed. However, rather than simply computing a function value, we are interested in running an executable program, and thus the time required to explore a number of design scenarios may be extensive. For example, a financial model may take on the order of one hour to compute one scenario on a PC. Accordingly, to consider 100 different scenarios requires 100 hours, or over four days of computing time. This type of experiment can be feasible only if a number of computers are used to run different invocations of the program in parallel. For example, 20 machines could solve the same problem in about five hours of elapsed time.
In spite of the obvious advantage to using multiple machines to solve one large parametric experiment, almost no high-level tools are available for supporting multiple executions of the same program over distributed computers. Spreadsheet software is not designed for executing programs concurrently or utilizing distributed computers. It is possible to write a program using low-level parallel programming tools like PVM (see http://www.epm.ornl.gov/pvm/), Message Passing Interface (see http://www.mpi-forum.org/) and Remote Procedure Call (RPC), to support its execution across many machines; however, this approach has a number of disadvantages.
First, the source must be available for the program, and it must be modified to support parallel execution. This is not always possible or desirable for complex commercial software.
Second, all aspects of distributing the task must be built into the application. Application programmers are usually not expert in both their own discipline and parallel programming; in short, it is difficult.
Third, unless fault tolerance is built into the application, the resulting program will not be able to handle failure in the network or in individual machines. Such fault tolerance significantly complicates the application.
Accordingly, it is not surprising that few instances of this approach are used in practice.
The alternative method is to use a remote job distribution system like Platform Computing Load Sharing Facility (see www.platform.com), Network Queueing System (see www.shef.ac.uk/uni/projects/nqs) or Portable Batch Scheduler (see pbs.mrj.com). These systems allow a user to submit jobs to a virtual computer built from many individual machines. While more general than the previous parallel-programming approach, the main disadvantage of remote queueing systems is they are targeted at running jobs, not necessarily performing a parametric study. Thus, you have to build additional software for running generated jobs based on the different parameter values and after aggregating the results. This can expose the user to a number of low-level system issues, such as the management of network queues, location and nature of the underlying machines, availability of shared file systems, the method for transferring data from one machine to another, etc.
EnFuzion belongs somewhere between a user-level tool and a software development environment. EnFuzion has been designed to make it possible to build a fault-tolerant, distributed application for a parametric-modelling experiment in a time on the order of minutes. In many cases, EnFuzion requires no programming; all you do is describe the parameters to the system and give some instruction on how to run the programs. EnFuzion manages the instantiation of your code with different parameter values, sends the files to the remote machines and retrieves them, and finally, it distributes the execution. If a program or system fails, EnFuzion automatically reruns the program on another machine.
Running an EnFuzion experiment requires three phases: preparation, generation and distribution. During preparation, you develop a descriptive file called a plan. A plan contains a description of the parameters, their types and possible values. It also contains commands for sending files to remote machines, retrieving them and running the job. EnFuzion provides a tool called the Preparator which has a wizard for generating standard plan files, as shown in Figure 1. Alternatively, if you are prepared to learn EnFuzion's simple scripting language, it is possible to build a plan using a normal text editor. The plan shown in Figure 1 is typical of a simple experiment and is quite small.

Figure 1. Plan File
The plan file is processed by a tool called the generator, which asks the user to specify the actual values for the parameters. For example, a plan file might specify that a parameter is a range of integers, without giving the start, end or increment values. The generator tool allows the user to fill in these values. It then reports how many independent program executions are required to perform the experiment by taking the cross product of all parameter values. Figure 2 shows a sample generator interaction with a CAD tool, where the clock period parameter is set to values of 75 and 100 nanoseconds and the cost table parameter is varied from 1 to 100. This interaction generated 200 individual executions of the CAD package.
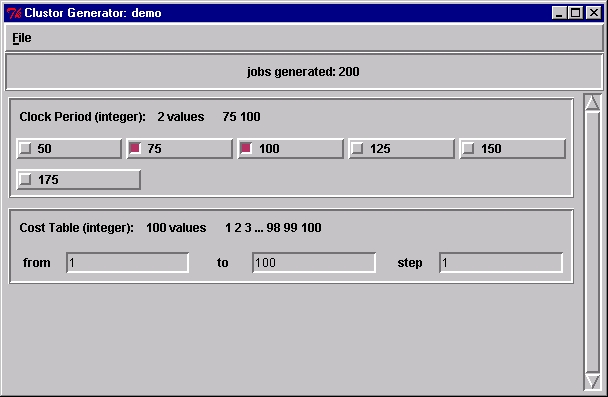
Figure 2. Sample Generator
The generator produces a run file, which contains all the information regarding what parameter values are to be used and how to run the jobs. This file is processed by a tool called the dispatcher, which organizes the actual execution. EnFuzion calls the machine on which you develop your plan the root machine. The work is performed on a number of computational nodes, as shown in Figure 3. Files are sent from the root machine to the computational nodes as required. Output is returned to the root for postprocessing.

Figure 3. Computational Nodes
The dispatcher chooses to send work to machines which are named in a user-supplied file, so every user can have a different list of machines. The dispatcher contacts the nodes and determines whether it is possible to start execution of the tasks. EnFuzion allows you to restrict the number of tasks run by using many different thresholds, such as a maximum number of tasks, the hours a node will be available and the peak load average for the machine. At Monash, we have augmented EnFuzion with a simple scheme using the UNIX command nice. This allows a node to run more tasks than available processors, but long-running jobs are “niced” to allow short ones to have a higher priority than long-running ones. This seems to be a good way of mixing short- and long-running jobs without restricting the job mix artificially.
At Monash University, we have built a cluster of 30 dual-processor Pentium machines running Linux, called the Monash Parametric Modelling Engine (MPME). A single machine acts as the host, and is connected to both the public network and a private 100Mbit network for linking the computational nodes. Figure 4 shows part of this machine.

Figure 4. Monash Parametric Modelling Engine
Each MPME node runs a full Linux Red Hat 5.2 kernel, and the standard GNU tools, such as gcc, gdb, etc. Typically, users log in to the host and use EnFuzion to schedule work on the nodes. We have configured the system to accept up to five jobs per node, even though each node contains only two processors. To control the load on each machine, a script is run which increases the nice level of each process the longer it executes. This means it is possible to mix long- and short-running jobs on the platform. In contrast, when we limited the number of jobs to the number of processors, we found that long-running jobs were monopolizing the nodes and short-running jobs were rarely run.
To date, we have used the MPME to support a wide range of applications. Table 1 shows a list of the applications mounted during 1998 and 1999. Many of these are student projects completed as part of a semester subject. In the sidebar “A Case Study”, one of our postgraduate students, Carlo Kopp, describes use of the cluster to perform his network simulations. The results have been quite dramatic, in this case the additional computational resources allowed him to explore many more design options than he initially thought would be possible.

David Abramson (davida@dgs.monash.edu.au) is the head of the School of Computer Science and Software Engineering at Monash University in Australia. Professor Abramson has been involved in computer architecture and high performance computing research since 1979 and is currently project leader in the Co-operative Research Centre for Distributed Systems Nimrod Project. His current interests are in high performance computer systems design, software engineering tools for programming parallel and distributed supercomputers and stained glass windows.
