
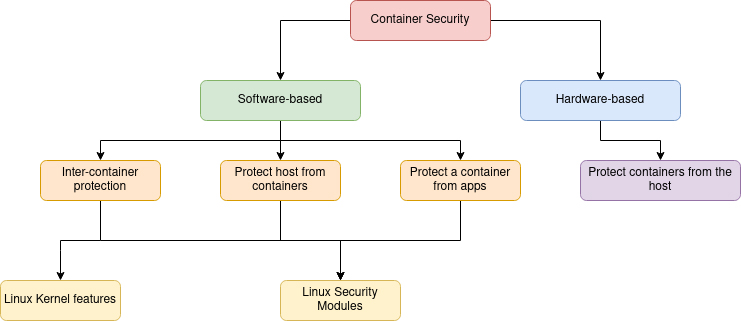
Primer to Container Security

Containers are considered to be a standard way of deploying these microservices to the cloud. Containers are better than virtual machines in almost all ways except security, which may be the main barrier to their widespread adoption.
This article will provide a better understanding of container security and available techniques to secure them.
A Linux container can be defined as a process or a set of processes running in the userspace that is/are isolated from the rest of the system by different kernel tools.
Containers are great alternatives to virtual machines (VMs). Even though containers and virtual machines provide the same isolation benefits, they differ in the way that containers provide operating system virtualization instead of hardware. This makes them lightweight, faster to start, and consumes less memory.
As multiple containers share the same kernel, the solution is less secure than the VMs, where they have their copies of OS, libraries, dedicated resources, and applications. That makes VM excellently secure but because of their high storage size and reduced performance, it creates a limitation on the total number of VMs which can be run simultaneously on a server. Further VMs take a lot of time to boot.
The introduction of microservice architecture has changed the way of developing software. Microservices allow the development of software in small self-contained independent services. This makes the application easier to scale and provides agility.
If a part of the software needs to be rewritten it can easily be done by changing only that part of the code without interrupting any other service, which wasn't possible with the monolithic kernel.
1) Linux Kernel Features
a. Namespaces
Namespaces ensure the isolation of resources for processes running in a container to that of others. They partition the kernel resources for different processes. One set of processes in a separate namespace will see one set of resources while another set of processes will see another. Processes in different see different process IDs, hostnames, user IDs, file names, names for network access, and some interprocess communication. Hence, each file system namespace has its private mount table and root directory.
This isolation can be extended to the child process running within a container. For eg., if there is a PID 1 assigned to a process in a container, the same PID 1 can also be assigned to any other child process using the PID namespace.
Similarly, other namespaces like network, mount, PID, User, UTS, IPC, and time could be applied to isolate different resources in a container.
However, one limitation with namespaces is that some resources are still not namespace-aware. For example devices.
b. Control Groups (CGroups)
They limit and isolate the resource usage like CPU runtime, memory, disk I/O and network among user-defined groups of processes running on a system.
In contrast to namespaces, cgroups limit how many resources can be used, while namespaces control what resources a container can see.
c. Capabilities
Linux implementations distinguish two categories of processes: privileged processes (superuser or root), and unprivileged processes. Privileged processes bypass all kernel permission checks, while unprivileged processes are subject to full permission checking based on the process’s credentials.
But in the case of containers, those binary options can be troublesome because providing the whole container to have full root privilege can be dangerous.
Capabilities turn this dichotomy into fine-grained access control. A set of capabilities can be assigned to the container which could reduce the container’s root operational threats.
d. Secure Computation Mode (Seccomp)
Seccomp can be used to restrict the actions available within the container. It restricts the process to make some particular predefined syscalls from user space to kernel space. If the process attempts any other system calls, it is terminated by the kernel. A large number of syscalls are exposed to every user-space process, with many of them not required. Restricting them reduces the total kernel surface exposed to the application.
seccomp-bpf is an extension to seccomp that allows filtering of system calls using a configurable policy. The combination of restricted and allowed calls are arranged in profiles, and different profiles can be passed to different containers. It provides more fine-grained control than capabilities, giving an attacker a limited number of syscalls from the container during a security compromise.
2) Linux Security Modules (LSMs)
To understand the working of LSMs, let’s take a look at kernel objects.
Kernel Objects
Each kernel object is simply a memory block allocated by the kernel. It keeps the information about the objects in a data structure which can only be accessed by the kernel. The system creates and manipulates several types of kernel objects, these include access token objects, event objects, file objects, file-mapping objects, I/O completion port objects, job objects, mailslot objects, mutex objects, pipe objects, process objects, semaphore objects, thread objects, and waitable timer objects.
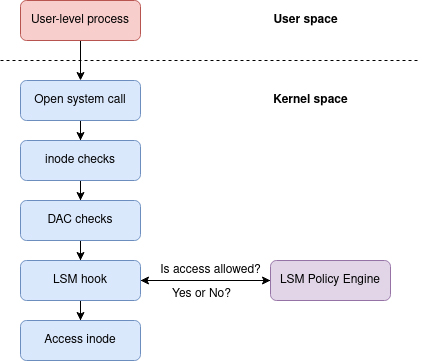
LSMs
LSM interface mediates access to internal kernel objects by placing hooks in the kernel just before their access. It fundamentally answers the question: "May <subject> do <action> to <object>", for example: "May a web server access files in users' home directories?". Types of objects protected include files, inodes, task structures, credentials, and interprocess communication objects. Manipulating these objects represents the primary way processes interact with their environment, and by carefully specifying allowable interactions, a security administrator can make it more difficult for an attacker to exploit a flaw in one program to pivot to other areas of the system.
Linux Security Module (LSM) provides MAC-based controls with minimal changes to the kernel itself. LSM allows modules to mediate access to kernel objects by placing hooks in the kernel code just before the access. The LSM framework provides a mechanism for various security checks to be hooked by new kernel extensions. The name “module” is a bit of a misnomer since these extensions are not loadable kernel modules but selected during build time.
Some commonly used LSMs are:
SELinux (Security Enhanced Linux) - is the default MAC implementation on RedHat-based Linux Distributions. It is known for being powerful and complex. SELinux is attribute-based which means the security identifiers for files are stored in extended file attributes in the file system. SELinux defines access controls for the applications, processes, and files on a system. It uses security policies, which are a set of rules that tell SELinux what can or can’t be accessed, to enforce the access allowed by a policy.
AppArmor - It implements a task-centered policy, with task “profiles” being created and loaded from userspace. Profiles can allow capabilities like network access and raw socket access. AppArmor security policies completely define what system resources individual applications can access, and with what privileges. Tasks on the system that do not have a profile defined run in an unconfined state equivalent to standard Linux DAC permissions.
There are hardware-based container protection mechanisms that protect the containers from other containers and a malicious or compromised host. This article focused on the software-based container security aspect.
It was a brief introduction to container security and was mainly related to Linux containers. If you want to have a more detailed look, please follow the links in the reference section.
Reference:
Container Security: Issues, Challenges, and the Road Ahead
LSM Design: Mediate Access to Kernel Objects

Ankur is a Software Engineer at Accuknox. He is an open-source contributor with experience in systems software engineering and cloud-native technologies. Currently, he is working on eBPF, LSM, and cloud-native security. He loves to talk and write about open-source, cloud security, and operating system. Follow him at @Knownymous1 on Twitter.
Recent Articles






