
BPF For Observability: Getting Started Quickly
How and Why for BPF
BPF is a powerful component in the Linux kernel and the tools that make use of it are vastly varied and numerous. In this article we examine the general usefulness of BPF and guide you on a path towards taking advantage of BPF’s utility and power. One aspect of BPF, like many technologies, is that at first blush it can appear overwhelming. We seek to remove that feeling and to get you started.
What is BPF?
BPF is the name, and no longer an acronym, but it was originally Berkeley Packet Filter and then eBPF for Extended BPF, and now just BPF. BPF is a kernel and user-space observability scheme for Linux.
A description is that BPF is a verified-to-be-safe, fast to switch-to, mechanism, for running code in Linux kernel space to react to events such as function calls, function returns, and trace points in kernel or user space.
To use BPF one runs a program that is translated to instructions that will be run in kernel space. Those instructions may be interpreted or translated to native instructions. For most users it doesn’t matter the exact nature.
While in the kernel, the BPF code can perform actions for events, like, create stack traces, count the events or collect counts into buckets for histograms.
Through this BPF programs provide both fast and immensely powerful and flexible means for deep observability of what is going on in the Linux kernel or in user space. Observability into user space from kernel space is possible, of course, because the kernel can control and observe code executing in user mode.
Running BPF programs amounts to having a user program make BPF system calls which are checked for appropriate privileges and verified to execute within limits. For example, in the Linux kernel version 5.4.44, the BPF system call checks for privilege with:
if (sysctl_unprivileged_bpf_disabled && !capable(CAP_SYS_ADMIN)) return -EPERM;
The BPF system call checks for a sysctl controlled value and for a capability. The sysctl variable can be set to one with the command
sysctl kernel.unprivileged_bpf_disabled=1
but to set it to zero you must reboot and make sure to not have your system configured to set it to one at boot time.
Because BPF is doing the work in kernel space significant time and overhead is saved avoiding context switches and by not necessitating transferring large amounts of data back to user space.
Not all kernel functions can be traced. For example if you were to try funccount-bpfcc '*_copy_to_user' you may get output like:
cannot attach kprobe, Invalid argument Failed to attach BPF program b'trace_count_3' to kprobe b'_copy_to_user'
This is kind of mysterious. If you check the output from dmesg you would see something like:
[686890.989521] trace_kprobe: Could not probe notrace function _copy_to_user
A good reason for preventing a probe is to avoid infinite recursion.
When and where can I use BPF?
BPF programs are verified within the kernel to avoid various risks such as boundless loops. Therefore BPF programs pose less risk, say, compared to an arbitrary Linux loadable kernel module. BPF programs impose less overhead for many observation tasks compared to related tools such as strace or tracing via the tracefs.
BPF tools can refer to functionality in the kernel or user space that are intended to provide stable interfaces – kernel and user space tracepoints BPF tools can also refer to functionality, such as the names of functions or fields that may well not be stable. Thus, BPF programs may not be portable across kernels. In addition, older kernels will not have the functionality and kernels may not be configured to support BPF so BPF is not universally portable or available.
However, distributions appear to regularly support BPF and provide a package of BPF tools for easy installation.
So, as long as you can invoke BPF as a privileged user and that you are running on a recent kernel you should have BPF functionality available. Some of the individual BPF tools, however, may or may not work with your kernel. There are efforts to make BPF programs more portable [2]. One of the natural challenges for tools that use kernel data structures is that the offsets for fields can vary based on kernel version and configuration.
Your Progression Of BPF Sophistication
Using BPF can involve various levels of sophistication. To use BPF to analyze Linux kernel issues may require, for example, significant experience with the kernel. Do you know the names of the kernel functions that may be valuable to observe? Do you know what their arguments are? So, even though running a BPF tool may be simple, knowing what to have the tool observe and how to interpret the results can be quite challenging.
Despite those challenges, let’s consider the following levels of sophistication with using BPF.
From simplest to most challenging:
- Using BPF based tools from a package.
- Using BPF tools from other sources such as from Brendan Gregg [7].
- Using bpftrace to write simple scripts, even one-liners.
- Writing BCC tools in Python [3].
- Writing BPF tools in C/C++ [4].
To learn to use BPF tools from a package for your distribution the first step is to make a quick study of what tools are provided. These tools in effect provide the vocabulary for your work and thus you need some understanding of what is available to use to express your needs.
For example, currently I mostly use a Ubuntu 20.04.01 system and for that system the current bpfcc-tools package provides 118 “binaries”, all installed in /usr/sbin. Of these, 1, /usr/sbin/deadlock.c-bpfcc, is actually C source code, 29 are BASH scripts all of which are simple wrappers to invoke one of the utilities (ucalls, uflow, ugc, uobjnew, ustat, or uthreads) which are Python bcc scripts. All of the remaining files are Python scripts themselves. The bpftrace package has 35 programs. With the 88 Python BCC programs, 29 shell wrappers, plus the 35 bpftrace you have 152 utilities with which to become familiar. More than an afternoon of work. But, to be honest, once you start experimenting with these tools you will find them so amazing you will want to spend lots of hours with them.
I, as indubitably will you, find it handy to search for bpftrace or bpfcc programs that are related to what I would like to do. There is a man page, in section 8, for each of the packaged utilities, so, for example when I do ‘man -k "file operations" -s 8’ I get btrfsslower-bpfcc, ext4slower-bpfcc, nfsslower-bpfcc, xfsslower-bpfcc, and zfsslower-bpfcc. Sometimes what is in the man pages, though, is surprising. For example I get no bpfcc-tools or bpftrace commands (but lots of others) if I search the man pages for “network”. But I get 16 bpfcc-tools or bpftrace commands if I search for “tcp”. I get 3 bpfcc programs with the keyword “socket”.
The names of the commands also tend to include the keyword so something like “ls /usr/sbin/*bpfcc | grep $keyword” works pretty well too.
Gregg [1] organizes commands into the categories CPUs, Memory, File Systems, Disk I/O, Networking, and Security but those are not necessarily the best keywords to use.
The Debian FAQ /usr/share/doc/libbpfcc/FAQ.txt is handy to help you troubleshoot problems you may have trying to run the tools.
Using BPF tools from other sourcesImportant repositories for bcc tools and bpftrace tools are [5] https://github.com/iovisor/bcc and [6] https://github.com/iovisor/bpftrace. From Brendan Gregg’s book [1] you can find many additional tools at [7] https://github.com/brendangregg/bpf-perf-tools-book.
The bpf-perf-tools-book repo has about 130 bpftrace tools and 2 Python bcc programs. There are a variety of quite valuable tools there and it's worthwhile to install the tools from this repo and to at least learn about them and choose selected ones for your monitoring or problem investigations.
Unfortunately, there are not many pages in the Gregg book repo and so you will probably want to use Gregg’s book for good explanations. Fortunately, the tools are organized into the chapter, e.g., Ch07_Memory, so you can use that organization to quickly find tools that may be helpful in a given situation.
The bash bpftrace programs, bashfunc.bt, bashfunc2.bt, and bashfunclat.bt depend on a version of Bash built by Brendan Gregg and reference /home/bgregg/Build/bash-4.4.18 so they are not immediately usable.
The BPF tools are commands and like any commands you invoke them on the command line and provide options and arguments. You will likely need to be root when you run the tools because the BPF system call checks for the appropriate capability as shown above.
All of the tools produce text output so you can pipe them into another utility, like sed, awk, sort, etc as usual. But since one of the key advantages of BPF over say perf or ftrace is that the data can be reduced, for example into histograms count, in kernel space, so the post-processing to be done by utilities is designed to be minimal.
Since the tools run until you hit ctrl-c, I often run them with the timeout command, specifying the time in seconds and the signal to send is SIGINT.
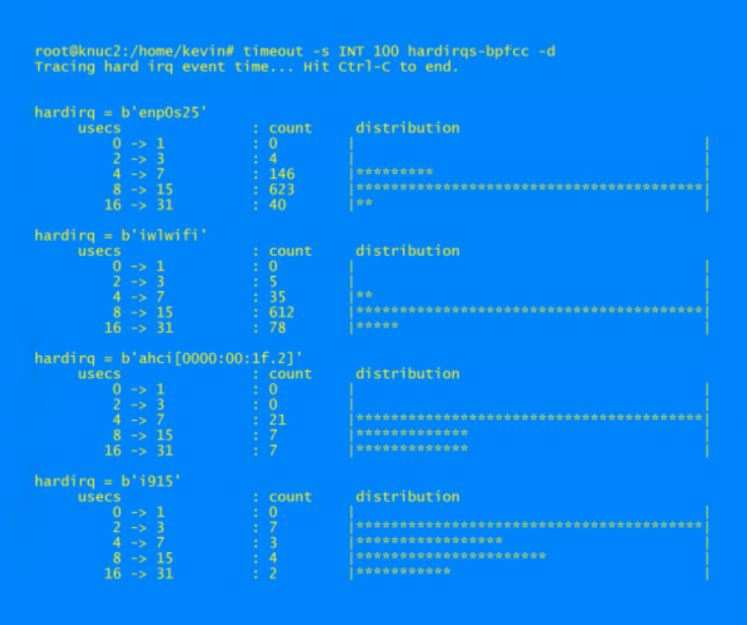
I am sometimes interested in the time spent in interrupt handlers, so the command hardirqs-bpfcc is handy. I run it for example, as so:
timeout -s INT 100 hardirqs-bpfcc -d
An example of the output is:
BPF programs react to events. The kinds of events are kprobes [8], uprobes, kernel tracepoints, user space tracepoints (USDT, User-level Statically Defined Tracing), Dynamic USDT, and Performance Monitoring Counters (e.g, perf with BPF).
Some of the tools, for example funccount-bpfcc are general purpose and have a syntax to specify a probe or tracepoint. Some of the tools use just one of the event types, for example, vfscount-bpfcc (kprobe on vfs functions in the kernel), memleak-bpfcc(uprobe and uretprobe, to probe allocations and frees in user space), and mysqld_qslower-bpfcc (usdt probes for query start and stops).
Tracepoints in the kernel and user space are additions into the source code and represent what is intended to be stable places for monitoring. Probes involve functions that may or not (especially in the kernel) remain stable.
You can use tools to get a list of the available probes, tracepoints, and PMCs. The command tplist-bpfcc will list kernel tracepoints and USDT (user space) probes. The command perf list shows performance monitoring counters (PMCs). The perf infrastructure, and PMCs can be used in BPF programs such as in profile-bpfcc and llcstat-bpfcc.
Requisite KnowledgeThe BPF tools often use and report arcane knowledge. To write or use a tool you may need to be familiar with kernel data structures or functions. Tools such as these can break when kernel functions and data structures change. Data structures can change based not only on kernel version but on kernel configuration.
For example, the tcptracer-bpfcc and udplife.bt tools include the header file from the kernel net/sock.h. There are structs in that file, such as sock_common that have fields that may or may not be present depending upon how the kernel is configured. For example, whether CONFIG_XPS is set or not (it is set, btw, in my Ubuntu kernel).
You should conclude that these tools are both powerful and can require deep knowledge.
Using Examples To HelpAs is common with programming, to write a program, first find another program as similar to the one you want to write as possible and start with that.
The packages come with a wealth of examples. An example for each tool with explanations. You will find the examples along with more documentation in /usr/share/doc/bpfcc-tools and /usr/share/doc/bpftrace. There are also directories in /usr/share/doc for libbpfcc and python3-bpfcc. These are examples of running the tools. When you find a tool that seems similar to what you want to do you can look at the tool in /usr/sbin which will either be Python, bpftrace, or a wrapper in Bash.
You may find llcstat-bpfcc interesting. As do I. This tool reports on CPU cache hits and misses per process and CPU. There are arguments to the program to specify how many seconds to run and sampling rate. A description of the arguments and some explanation are found in /usr/share/doc/bpfcc-tools/examples/doc/llcstat_example.txt.
The program llcstat-bpfcc can serve as an example of how to use perf hardware counters. You can find the values for PerfHWConfig in dist-packages/bcc/__init__.py, perhaps under /usr/lib/python3.
Gregg [1] gives a number of “one-liners” that are great and helpful examples. So you don’t have to write complicated scripts to create custom tools for observing behavior.
The one-liners for BCC use the commands that involve the syntax for specifying a type of an event or sometimes globs to match function names.
For example:
funccount-bpfcc 't:syscalls:*umask*'
Will report the number of times the tracepoints sys_enter_umask and sys_exit_emask where hit. The “t:” means kernel tracepoint. You can get a list of available tracepoints and probes, etc, with “bpftrace -l”.
To report the mask passed to the umask system call, in the kernel, we need to look at the code to get the name of the argument. Then we can do something like:
argdist-bpfcc -i 100 -H 't:syscalls:sys_enter_umask():int:args->mask'
Tools To Get Started With
Here’s a list of eight tools for you to get started with today. After you get bpftrace, BCC, and Brendan Gregg’s BPF programs installed then try these out. I selected these based on the criteria of which tools have wide utility, tools that demonstrate important capabilities, and tools that I find particularly interesting and valuable. Some other tools have wide applicability or other nice features but they may have issues like messy or confusing output. For example, profile-bpfcc has great potential but I find that it doesn’t merge stack traces and has lots of unknowns printed. The tools from Brendan Gregg’s book [7] don’t have many pages but you can read the source to get documentation on what they do and how to use them.
Tools to try today in alphabetical order:
argdist-bpfccThis tool lets you examine parameters to functions. You can count or do a histogram of the values. This is for functions in the kernel, or functions in library functions. This can be for a process or system wide. This program is also a good one to start with because to use it you need to become familiar with kernel and userspace tracepoints or probes. You can find the name of kernel tracepoints as filenames under /sys/kernel/debug/tracing/events. The USDT tracepoints of a library can be found with bpftrace -l ‘usdt:<library path>’, for example bpftrace -l 'usdt:/lib/x86_64-linux-gnu/libc.so.6'. You will see that almost all of the tracepoints in glibc are for memory allocation related functions. You can use probes for other functions.
To use argdist-bpfcc you will use its syntax to specify what function and arg(s) you want. For example, to used argdist-bpfcc via probe in the c library, to print a count of the number of times each value of a mask was passed to the umask function, with an interval between printing of 10 seconds and looping for 50 times do:
argdist-bpfcc -i 10 -n 50 -C 'p:c:umask(u32 mask):u32:mask'
Remember that not all applications use the Standard C Library. For folks analyzing Golang programs, for example, note that Go uses its own library so you would use “go” instead of “c” for the library for standard library functions.
biolatency-bpfccThe biolatency-bpfcc tool will print histograms of latencies for the disk devices. I like to run it like so:
biolatency-bpfcc -D
The -D option will have the tool print separate histograms for each disk device that had I/O during the interval you look at.
The biotop-bpfcc tool, like the well known tool “top”, shows a multi-column, refreshed display of data accumulated since the last refresh. The biotop tool shows disk devices and I/O statistics. If the processes are fleeting then you may want to use the -C option to keep biotop from clearing the screen.
The bpftrace tool is an interpreter for the powerful bpftrace language. Programs that have the suffix “.bt” are bpftrace programs. You can do simple one-line programs on the command line as well. Note that Brendan Gregg’s book [7] has quite a number of bpftrace one-lines in Appendix A. Here’s one that will print a histogram of block sizes. Hit ctrl-c to stop it and have it print the histogram.
bpftrace -e 't:block:block_rq_issue { @bytes = hist(args->bytes); }'
You will find that modifying bpftrace programs is simpler than modifying bpfcc programs. The bpftrace language has its own syntax for specifying the event (usdt, uretprobe, interval, uprobe, kretprobe, tracepoint,kprobe). The most commonly used are tracepoint and kprobe.
For example, the hfaults.bt program performs its work by counting calls to hugetlb_fault() as so:
kprobe:hugetlb_fault
{
@[pid, comm] = count();
}
cachestat-bpfcc
The cachestat-bpfcc program is for tracking disk caching performance. I like to run it with an interval and a number of iterations, plus a timestamp. Like so:
cachestat-bpfcc -T 30 5
You can easily experiment with something like a recursive grep. Run the grep twice back-to-back on a large directory and you hadn’t recently been reading. The first time you should see lots of misses and the second time your hits should be significantly higher. You could also experiment by telling the kernel to flush its caches first. E.g.:
echo 3 >/proc/sys/vm/drop_caches; cachestat-bpfcc -T 10 20filetop-bpfcc
The filetop-bpfcc program is a refreshed top-like program that shows commands and file I/O including filename statistics. You can see a lot of what a recursive grep is reading by running filetop-bpfcc while you are doing a long recursive grep.
funccount-bpfccThe program funccount-bpfcc counts calls to functions in the kernel or user space. The function name can use globbing or with the “-r” option regular expressions. You can specify a particular process using the “-p” option or have library calls be systemwide. You can use tracepoints or probes.
For example to trace all of the functions in the kernel that start with iwl_trans (inside the iwlwifi driver) do:
funccount-bpfcc "iwl_trans*"trace-bpfcc
The trace-bpfcc program is more powerful than just counting function calls. The trace program can print parameters, return values and evaluate expressions to determine whether to display the trace information. The trace command can have a lot of overhead per event so it is best for events that are not frequently occurring. Because trace can use parameters to functions it may need to know the type. Such as what a struct looks like. You can tell trace to include a header file to supply that info.
BPF programs may fail due to various constraints, such as certain functions, as mentioned above, are not traceable. As another example, when I tried to trace like so:
'tcp_select_initial_window(const struct sock *sk, int __space, u32 mss, u32 *rcv_wnd, u32 *window_clamp, int wscale_ok, u8 *rcv_wscale, u32 init_rcv_wnd) "%d", arg2'
I got
error: too many arguments, bcc only supports in-register parameters
But I didn’t need the parameter list so I could just do
'tcp_select_initial_window() "%d", arg2'
Which worked fine.
What to do next
Of course learning to use a tool requires using that tool. Go forth and BPF-iply. The BPF tools are designed to be safe to run even in production environments but perhaps you may want to begin with the programs selected above, on a development system, maybe even your Linux laptop. I suggest a system with a 5.4 or newer kernel.
If you want an objective measure of your BPF knowledge – to convince yourself, or others such as a potential employer, that you have substantial knowledge of BPF and its tools then you may want to take the Performance Measurement and Tuning assessment exam you can find at aardfoss.com. To learn BPF more quickly and with focus you can take training. I teach an open enrollment class on BPF, for example.
Brendan Gregg’s BPF Performance Tools: Linux System and Application Observability [1] is the definitive book for many tools, techniques, and explanations of BPF technology.
References
[1] Gregg, Brendan. BPF Performance Tools: Linux System and Application Observability. Addison-Wesley, 2020.
[3] bcc Python Developer Tutorial
[4] BPF C
[5] BCC git repo
Recent Articles






