
Linux Clustering with Ruby Queue: Small Is Beautiful
My friend Dave Clements always is game for a brainstorming session, especially if I'm buying the coffee. Recently, we met at the usual place and I explained my problem to him over the first cup. My office had a bunch of Linux nodes sitting idle and a stack of work lined up for them, but we had no way to distribute the work to them. Plus, the deadline for project completion loomed over us.
Over the second cup of coffee, I related how I had evaluated several packages, such as openMosix and Sun's Grid Engine, but ultimately had decided against them. It all came down to this: I wanted something leaner than everything I'd seen, something fast and easy, not a giant software system that would require weeks of work to install and configure.
After the third cup of coffee, we had it: Why not simply create an NFS-mounted priority queue and let nodes pull jobs from it as fast as they could? No scheduler, no process migration, no central controller, no kernel mods--simply a collection of compute nodes working as fast as possible to complete a list of tasks. But there was one big question: was accessing an NFS-mounted queue concurrently from many nodes possible to do safely? Armed with my favorite development tools--a brilliant IDE named Vim and the Ruby programming language--I aimed to find out.
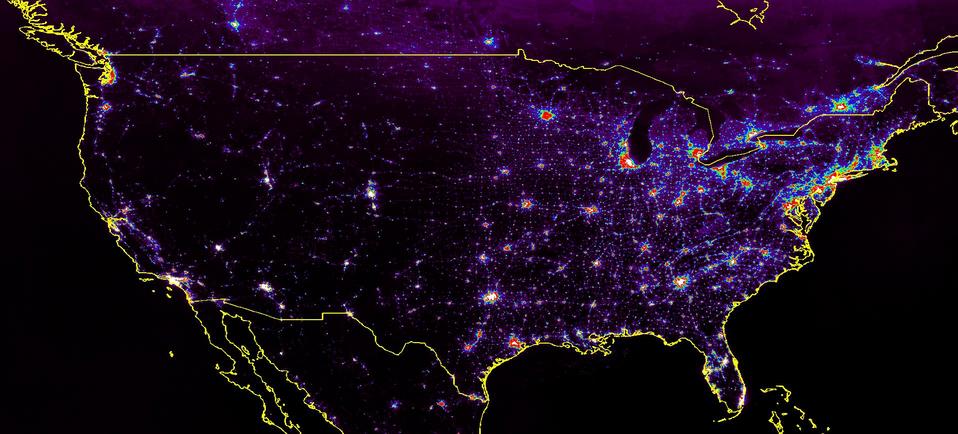
I work for the National Geophysical Data Center's (NGDC) Solar-Terrestrial Physics Division (STP), in the Defense Meteorological Satellite Program (DMSP) group. My boss, Chris Elvidge, and the other scientists in our group study the the night-time lights of Earth from space. The data we receive helps researchers understand changes in human population and the movement of forest fires, among other things. The infrastructure required to do this kind of work is astounding. The following image, showing the average intensity of night-time lights over part of North America, required over 100 gigabytes of input data and 142 terabytes of intermediate files to produce. Over 50,000 separate processes spread across 18 compute nodes and a week of clock time went into its production.
Linux clusters have become the new supercomputers. The economics of teraflop performance built on commodity hardware is impossible to ignore in the current climate of dwindling research funding. However, one critical aspect of cluster-building, namely orchestration, frequently is overlooked by the people doing the buying. The problem facing a developer with clustered systems is analogous to the one facing a home buyer who can afford only a lot and some bricks--he's got a lot of building to do.
Yukihiro Matsumoto, aka Matz, has said that "The purpose of Ruby is to maximize programming pleasure", and experience has taught me that enjoying the creative process leads to faster development and higher quality code. Ruby features powerful object-oriented abstraction techniques, extreme dynamism, ease of extensibility and an armada of useful libraries. It is a veritable Swiss Army machete, precisely the sort of tool one should bring into uncharted territory such as the NFS-mounted priority queue I was seeking to build.
The first task I faced when creating Ruby Queue (rq) was to work out the issues with concurrent access to NFS shared storage, and the first bridge I had to cross was how to accomplish NFS-safe locking from within Ruby. Ruby has an fcntl interface similar to Perl's and, like Perl's, the interface requires you to pack a buffer with the struct arguments. This is perfectly safe but, unfortunately, non-portable. I've wondered about this oversight before and decided to address it by writing a little C extension, posixlock, which extends Ruby's built-in File class with a method to apply fcntl, or POSIX-style, advisory locks to a File object. Here is a majority of the code from posixlock.c:
static int
posixlock (fd, operation)
int fd;
int operation;
{
struct flock lock;
switch (operation & ~LOCK_NB)
{
case LOCK_SH:
lock.l_type = F_RDLCK;
break;
case LOCK_EX:
lock.l_type = F_WRLCK;
break;
case LOCK_UN:
lock.l_type = F_UNLCK;
break;
default:
errno = EINVAL;
return -1;
}
lock.l_whence = SEEK_SET;
lock.l_start = lock.l_len = 0L;
return fcntl (fd,
(operation & LOCK_NB) ? F_SETLK :
F_SETLKW, &lock);
}
static VALUE
rb_file_posixlock (obj, operation)
VALUE obj;
VALUE operation;
{
OpenFile *fptr;
int ret;
rb_secure (2);
GetOpenFile (obj, fptr);
if (fptr->mode & FMODE_WRITABLE)
{
fflush (GetWriteFile (fptr));
}
retry:
TRAP_BEG;
ret =
posixlock (fileno (fptr->f),
NUM2INT (operation));
TRAP_END;
if (ret < 0)
{
switch (errno)
{
case EAGAIN:
case EACCES:
#if defined(EWOULDBLOCK) && EWOULDBLOCK != EAGAIN
case EWOULDBLOCK:
#endif
return Qfalse;
case EINTR:
#if defined(ERESTART)
case ERESTART:
#endif
goto retry;
}
rb_sys_fail (fptr->path);
}
void
Init_posixlock ()
{
rb_define_method (rb_cFile, "posixlock",
rb_file_posixlock, 1);
}
Granted, it's a bit ugly, but C code almost always is. One of things that's really impressive about Ruby, however, is the code for the interpreter itself is quite readable. The source includes array.c, hash.c and object.c--files even I can make some sense of. In fact, I was able to steal about 98% of the above code from Ruby's File.flock implementation defined in file.c.
Along with posixlock.c, I needed to write an extconf.rb (extension configure) file, which Ruby automagically turns into a Makefile. Here is the complete extconf.rb file used for the posixlock extension:
require 'mkmf' and create_makefile 'posixlock'
Usage of the extension mirrors Ruby's own File.flock call, but this is safe for NFS-mounted files. The example below can be run simultaneously from several NFS clients:
require 'socket'
require 'posixlock'
host = Socket::gethostname
puts "test running on host #{ host }"
File::open('nfs/fcntl_locking.test','a+') do |file|
file.sync = true
loop do
file.posixlock File::LOCK_EX
file.puts "host : #{ host }"
file.puts "locked : #{ Time::now }"
file.posixlock File::LOCK_UN
sleep 0.42
end
end
A tail -f of the NFS-mounted file fcntl_locking.test shows the file is being accessed concurrently in a safe fashion. Notice the lack of error checking: Ruby is an exception-based language, so any method that does not succeed raises an error, and a detailed stack trace is printed on standard error.
One of the things to note about this extension is I actually was able to add a method to Ruby's built-in File class. Ruby's classes are open--you can extend any class at any time, even the built-in ones. Obviously, extending the built-in classes should be done with great care, but there is a time and a place for it, and Ruby does not prevent you from doing so where it makes sense. The point here is not that you have to extend Ruby but that you can. And it is not difficult to do.
Having resolved my locking dilemma, the next design choice I had to make was what format to use to store the queue. Ruby has the ability to serialize any object to disk, and it includes a transactionally based, file-backed object storage class, PStore, that I have used successfully as a mini database for many CGI programs. I began by implementing a wrapper on this class that used the posixlock module to ensure NFS-safe transactions and that supported methods such as insert_job, delete_job and find_job. Right away, I started to feel like I was writing a little database.
Not being one to reinvent the wheel (at least not too often), I decided to utilize the SQLite embedded database and the excellent Ruby bindings for it written by Jamis Buck as a storage backend. This really helped get the project moving, as I was freed from writing a lot of database-like functionality.
Many database APIs have made the choice of returning either a hash or an array to represent a database tuple (row). With tuples represented as hashes, you can write code that can be read easily, such as this:
ssn = tuple['ssn']
Yet, you are unable to write natural code, such as:
sql =
"insert into jobs values ( #{ tuple.join ',' } )"
or
primary_key, rest = tuple
And with an array representation, you end up with indecipherable code, such as this:
field = tuple[7]
Now, what was field 7 again?
When I first started using the SQLite bindings for Ruby, all of the tuples were returned as hashes, and I had a lot of slightly verbose code that converted tuples from hash to array and back again. Anyone who's spent much time working with Ruby can tell you that Ruby's elegance inspires you to make your own code more elegant. All this converting was not only inelegant but inefficient too. What I wanted was a tuple class that was an array, but one that allowed keyword field access for readability and elegance.
For Ruby, this task was no problem. I wrote a pure Ruby module, ArrayFields, that allowed any array to do exactly this. In Ruby a module not only is a namespace, but it can be mixed in to other classes to impart functionality. The effect is similar but less confusing than multiple inheritance. In fact, Ruby classes not only can be extended in this way, but instances of Ruby objects themselves can be extended dynamically with the functionality of a module--leaving other instances of that same class untouched. Here's an example using Ruby's Observable module, which implements the Publish/Subscribe design pattern:
require 'observer' publisher = Publisher::new publisher.extend Observable
In this example, only this specific instance of the Publisher class is extended with Observable's methods.
Jamis was more than happy to work with me to add ArrayFields support to his SQLite package. The way it works is simple: if the ArrayFields module is detected at runtime, then the tuples returned by a query are extended dynamically to support named field access. No other array objects in memory are touched, only those arrays returned as tuples are extended with ArrayFields.
Finally, I was able to write readable code that looked like this:
require 'arrayfields'
require 'sqlite'
...
query = 'select * from jobs order by submitted asc'
tuples = db.execute query
tuples.each do |tuple|
jid, command = job['jid'], job['command']
run command
job['state'] = 'finished'
# quoted list of job's fields
values = job.map{|val| "'#{ val }'" }.join ','
sql = "insert into done values( #{ values } )"
db.execute sql
end
and elegant code, such as this:
jobs.sort_by{ |job| job['submitted'] }
This extension offers more than mere convenience; using arrays over hashes is faster, requires about 30% less memory and makes many operations on tuples more natural to code. Allowing keyword access to the arrays makes the code more readable and frees the developer from remembering field positions or, worse, having to update code if a change to the database schema should change the order of fields. Finally, a reduction in total lines of code almost always aids both development and maintenance.
Using posixlock and SQLite made coding a persistent NFS-safe priority queue class relatively straightforward. Of course, there were performance issues to address. A lease-based locking system was added to detect the possible lockd starvation issues I'd heard rumors about on the SQLite mailing list. I posted many questions to the NFS mailing lists during this development stage, and developers such as Trond Myklebust were invaluable resources to me.
I'm not too smart when it comes to guessing the state of programs I myself wrote. Wise programmers know that there is no substitute for good logging. Ruby ships with a built-in Logger class that offers features such as automatic log rolling. Using this class as a foundation, I was able to abstract a small module that's used by all the classes in Ruby Queue to provide consistent, configurable and pervasive logging to all its objects in only a few lines of code. Being able to leverage built-in libraries to abstract important building blocks such as logging is a time- and mind-saver.
If you still are using XML as a data serialization format and yearn for something easier and more readable, I urge you to check out YAML. Ruby Queue uses YAML extensively both as input and output format. For instance, the rq command-line tool shows jobs marked "important" as:
- jid: 1 priority: 0 state: pending submitted: 2004-11-12 15:06:49.514387 started: finished: elapsed: submitter: redfish runner: pid: exit_status: tag: important command: my_job.sh - jid: 2 priority: 42 state: finished submitted: 2004-11-12 17:37:10.312094 started: 2004-11-12 17:37:13.132700 finished: 2004-11-12 17:37:13.739824 elapsed: 0.015724 submitter: redfish runner: bluefish pid: 5477 exit_status: 0 tag: important command: my_high_priority_job.sh
This format is easy for humans to read and friendly to Linux commands such as egrep(1). But best of all, the document above, when used as the input to a command, can be loaded into Ruby as an array of hashes with a single command:
require 'yaml' jobs = YAML::load STDIN
It then can be used as a native Ruby object with no complex API required:
jobs.each do |job| priority = job['priority'] ... end
Perhaps the best summary of YAML for Ruby is offered by it's author, "_why". He writes, "Really, it's quite fantastic. Spreads right on your Rubyware like butter on bread!"
I actually had a prototype of Ruby Queue (rq) in production, a step we do a lot in the DMSP group, when a subtle bug cropped up. NFS has a feature known as silly renaming. This happens when two clients have an NFS file open and one of them removes it, causing the the NFS server to rename the file something like ".nfs123456789" until the second client is done with it and the file truly can be removed.
The general mode of operation for rq, when feeding on a queue (running jobs from it), is to start a transaction on the SQLite database, find a job to run, fork a child process to run the job, update the database with information such as the pid of the job and end the transaction. As it turns out, transactions in SQLite involve some temporary files that are removed at the end of the transaction. The problem was that I was forking in the middle of a transaction, causing the file handle of the temporary file to be open in both the child and the parent. When the parent then removed the temporary file at the end of the transaction, a silly rename occurred so that the child's file handle still was valid. I started seeing dozens of these silly files cluttering my queue directories; they eventually would disappear, but they were ugly and unnerving to users.
I initially looked into the possibility of closing the file handle somehow after forking, but I received some bad news from Dr. Richard Hipp, the creator of SQLite, on the mailing list. He said forking in the middle of a transaction results in "undefined" behavior and was not recommended.
This was bad news, as my design depended heavily on forking in a transaction in order to preserve the atomicity of starting a job and updating its state. What I needed to be able to do was fork without forking. More specifically, I needed another process to fork, run the job and wait for it on my behalf. Now, the idea of setting up a co-process and using IPC to achieve this fork with forking made me break out in hives. Fortunately, Ruby offered a hiveless solution.
DRb, or Distributed Ruby, is a built-in library for working with remote objects. It's similar to Java RMI or SOAP, only DRb is about a million times easier to get going. But, what do remote objects have to do with forking in another process? What I did was code a tiny class that does the forking, job running and waiting for me. An instance of this class then can set up as a local DRb server in a child process. Communication is done transparently by way of UNIX domain sockets. In other words, the DRb server is the co-process that does all the forking and waiting for me. Interacting with this object is similar to interacting with any other Ruby object. The entire JobRunnerDaemon class contains 101 lines of code, including the child process setup. The following are some excerpts from the Feeder class, which shows the key points of its usage.
An instance of a JobRunnerDaemon is started in a child process and a handle on that remote (but on localhost) object is returned:
jrd = JobRunnerDaemon::daemon
A JobRunner object is created for a job, and the JobRunner is created by pre-forking a child in the JobRunnerDaemon's process used later to run the Job. The actual fork takes place in the child process, so it does not affect the parent's transaction:
runner = jrd.runner job pid = runner.pid runner.run
Later, the DRb handle on the JobRunnerDaemon can be used to wait on the child. This blocks exactly as a normal wait would, even though we are waiting on the child of a totally different process.
cid, status = jrd.waitpid2 -1, Process::WUNTRACED
We go through "Run it. Break it. Fix it." cycles like this one often in my group, the philosophy being that there is no test like production. The scientists I work with most closely, Kim Baugh and Jeff Safran, are more than happy to have programs explode in their faces if the end result is better, more reliable code. Programs written in a dynamic language such as Ruby enable me to fix bugs fast, which keeps their enthusiasm for testing high. The combined effect is a rapid evolutionary development cycle.
Here, I walk though the actual sequence of rq commands used to set up an instant Linux cluster comprised of four nodes. The nodes we are going to use are called onefish, twofish, redfish and bluefish. Each host is identified in its prompt, below. In my home directory on each of the hosts I have the symbolic link ~/nfs pointing at a common NFS directory.
The first thing we have to do is initialize the queue:
redfish:~/nfs > rq queue create created <~/nfs/queue>
Next, we start feeder daemons on all four hosts:
onefish:~/nfs > rq queue feed --daemon -l=~/rq.log twofish:~/nfs > rq queue feed --daemon -l=~/rq.log redfish:~/nfs > rq queue feed --daemon -l=~/rq.log bluefish:~/nfs > rq queue feed --daemon -l=~/rq.log
In practice, you would not want to start feeders by hand on each node, so rq supports being kept alive by way of a crontab entry. When rq runs in daemon mode, it acquires a lockfile that effectively limits it to one feeding process per host, per queue. Starting a feeder daemon simply fails if another daemon already is feeding on the same queue. Thus, a crontab entry like this:
15/* * * * * rq queue feed --daemon --log=log
checks every 15 minutes to see if a daemon is running, and it starts a daemon if and only if one is not running already. In this way, an ordinary user can set up a process that is running at all times, even after a machine reboot.
Jobs can be submitted from the command line, from an input file or, in Linux tradition, from standard input as part of a process pipeline. When using an input file or stdin, the format is either YAML (such as that produced as the output of other can rq commands) or a simple list of jobs, one job per line. The format is auto-detected. Any host that sees the queue can run commands on it:
onefish:~/nfs > cat joblist echo 'job 0' && sleep 0 echo 'job 1' && sleep 1 echo 'job 2' && sleep 2 echo 'job 3' && sleep 3 onefish:~/nfs > cat joblist | rq queue submit - jid: 1 priority: 0 state: pending submitted: 2004-11-12 20:14:13.360397 started: finished: elapsed: submitter: onefish runner: pid: exit_status: tag: command: echo 'job 0' && sleep 0 - jid: 2 priority: 0 state: pending submitted: 2004-11-12 20:14:13.360397 started: finished: elapsed: submitter: onefish runner: pid: exit_status: tag: command: echo 'job 1' && sleep 1 - jid: 3 priority: 0 state: pending submitted: 2004-11-12 20:14:13.360397 started: finished: elapsed: submitter: onefish runner: pid: exit_status: tag: command: echo 'job 2' && sleep 2 - jid: 4 priority: 0 state: pending submitted: 2004-11-12 20:14:13.360397 started: finished: elapsed: submitter: onefish runner: pid: exit_status: tag: command: echo 'job 3' && sleep 3
We see in YAML format, in the output of submitting to the queue, all of the information about each of the jobs. When jobs are complete, all of the fields are filled in. At this point, we check the status of the queue:
redfish:~/nfs > rq queue status --- pending : 2 running : 2 finished : 0 dead : 0
From this, we see that two of the jobs have been picked up by a node and are being run. We can find out which nodes are running our jobs using this input:
onefish:~/nfs > rq queue list running | egrep 'jid|runner' jid: 1 runner: redfish jid: 2 runner: bluefish
The record for a finished jobs remains in the queue until it's deleted, because a user generally would want to collect this information. At this point, we expect all jobs to be complete so we check each one's exit status:
bluefish:~/nfs > rq queue list finished | egrep 'jid|command|exit_status' jid: 1 exit_status: 0 command: echo 'job 0' && sleep 0 jid: 2 exit_status: 0 command: echo 'job 1' && sleep 1 jid: 3 exit_status: 0 command: echo 'job 2' && sleep 2 jid: 4 exit_status: 0 command: echo 'job 3' && sleep 3
All of the commands have finished successfully. We now can delete any successfully completed job from the queue:
twofish:~/nfs > rq queue query exit_status=0 | rq queue delete --- - 1 - 2 - 3 - 4
Ruby Queue can perform quite a few other useful operations. For a complete description, type rq help.
Making the choice to roll your own always is a tough one, because it breaks Programmer's Rule Number 42, which clearly states, "Every problem has been solved. It is Open Source. And it is the first link on Google."
Having a tool such as Ruby is critical when you decide to break Rule Number 42, and the fact that a project such as Ruby Queue can be written in 3,292 lines of code is testament to this fact. With only a few major enhancements planned, it is likely that this code line total will not increase much as the code base is refined and improved. The goals of rq remain simplicity and ease of use.
Ruby Queue set out to lower the barrier scientists had to overcome in order to realize the power of Linux clusters. Providing a simple and easy-to-understand tool that harnesses the power of many CPUs allows them to shift their focus away from the mundane details of complicated distributed computing systems and back to the task of actually doing science. Sometimes small is beautiful.
Ara T. Howard is a research associate at The Cooperative Institute for Research in Environmental Sciences. He spends his time programming Ruby or mountain biking and skiing with his wife, Jennifer, and a trio of border collies--Eli, Joey and Zipper.
