
The Need for Speed and Automation
The open-source world of Linux software development is evolving at an explosive rate. Patches, features and functions are being submitted at an extremely rapid pace. Have you ever wondered how those who are in control stay abreast of this overwhelming amount of change? How can anyone be expected to be aware of all the interactions that can and do take place between one or more patches? The people responsible for this minor miracle certainly are more than capable at what they do, which is why they are doing it. The reality of the situation, however, is there is more going on, more code interactions taking place, than even a team of the brightest people realistically can keep up with. As a result of this process, many functional and performance problems aren't recognized until the code has been released. Most problems are discovered by people like you and me who attempt to use the code and find out first-hand that something is wrong. When functions don't work it becomes quite clear there is a problem. When overall runtime regresses by, say, 5%, how many people actually notice? The point of this example is often times performance degradations (called regressions) go unnoticed. To recognize performance regressions, one usually has to search for them.
Today, the most common way of measuring overall system performance is through the use of benchmarks. Benchmarks, as the name implies, measure specific aspects of performance. Performance is the result of how efficiently the hardware and software work together to complete a task. There are basically two major types of benchmarks, the micro and the macro.
A micro benchmark focuses on one facet or subsystem, such as a filesystem sequential read test or a network I/O bandwidth test. A macro benchmark typically focuses on a specific workload and usually combines the overall performance characteristics of many subsystems, such as a TPC-H or SPECjAppServer workload. Both benchmark types are useful in determining the performance of a given set of software/hardware.
Using benchmarks, users or groups can monitor the performance of the newest available Linux kernels. Should a problem be discovered, they can sound the alarms and rally the troops to help analyze and then resolve the regression.
Given the current rate at which new kernels are being released, it can be difficult for individuals to test each and every version available. Most of the time, results are posted from kernels that are several point releases apart. This results in a large number of changes being introduced into the kernel between performance runs. Thus, when a regression is discovered, it becomes difficult to isolate the root cause. It would be beneficial if each and every kernel could be tested quickly and in a consistent manner. By doing so, the instant a performance problem is introduced it could be identified swiftly and its cause narrowed down to the offending patch.
IBM's Linux Technology Center performance team has been working on a solution to address this need. This team has created a multiphase regression package that automatically detects, retrieves and benchmarks newly available kernels, and then dynamically post-processes the data to detect performance regressions. This package has the ability to complete the analysis of a new kernel or patchset within 12 hours of its release.
The first step in the process is the regression package must determine when new work needs to be done. Checking for new work currently is driven by a cron job. This job runs every hour to see if new kernels/patches have been released. The script looks for changes in the several 2.5/2.6 (-bk, -mm and -mjb) development trees. When changes are detected, the retrieval and benchmarking phase of the regression process begins.
To handle the benchmark execution requirements a package called Autobench was created. Autobench is a small set of bash scripts that work together to create a consistent and coherent framework for running benchmarks and test programs. In addition to running benchmarks, Autobench also handles a number of common activities typically required when testing kernels and patches. The major capabilities of Autobench include:
Retrieves input files (one at a time) from a remote queue.
Retrieves kernels, .config files and patches from user-specified URLs (defaults to kernel.org for kernels).
Builds and installs kernels using .config file and patches.
Boots newly built or user-specified kernels.
Runs the benchmarks, collecting system state information before, during and after.
Stores results locally and/or remotely.
Autobench accepts a single input file, called a job or dat file (see Figure 1), that tells Autobench what to do. The job file has a pseudo-language, or a limited set of commands that Autobench understands. Those commands are:
build: retrieves the kernel, .config and patch files, then builds and installs new kernels.
boot: boots a selected kernel, supports kernel command-line boot arguments, supports LILO, GRUB and yaboot.
run: runs the actual benchmark script, passing arguments from the job file to the benchmark script. It also creates a log file for the benchmark output and results. It also takes a snapshot of the system state before and after the benchmark runs to aid in problem analysis.
results: sends results to user-specified location—optionally e-mail user of newly completed benchmark runs—and stores the results locally (in case of faulty transmission or other network outages).
setup: generic script that allows pre-benchmark run setup, such as mkfs, of devices prior to running a filesystem benchmark. This command can support most any type of setup requirements.
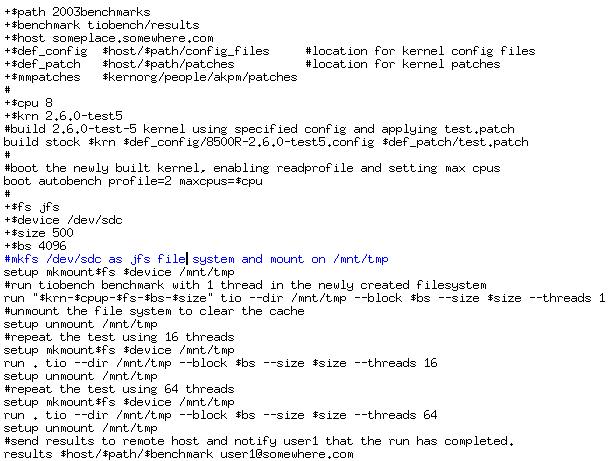
Figure 1. A Dat File for Executing the Benchmark tiobench within Autobenc.
Each command listed above is a bash script, so adding additional commands is easy. However, these commands make up the basic set of functionality in Autobench and have proven adequate for dozens of benchmarks. A dat file can contain any combination of commands in any order. It quite commonly is used to obtain data for the execution of multiple benchmarks.
In addition to the commands, Autobench also supports flexible aliasing capabilities known as dat-variables or datvars. Datvars aliasing can make dat files much more readable, maintainable and reusable. Datvars are stored and persist across reboots. Datvars then are deleted when a dat file has been executed fully.
Scheduling jobs in Autobench is accomplished through the use of remote queues, directories on a remote machine. Dat files can be placed in the remote directory regardless of the state of the machine running Autobench. When Autobench has completed its last task (dat file), it examines its remote queue. If files are found there, it downloads the next file it finds (based on sort-order) and begins processing that dat file. This technique allows a virtually unlimited number of dat files to be queued up at any time, thus providing the potential for machine utilization 24/7.
In addition to automating and driving benchmark workloads on one or more machines, Autobench can be wrapped by other packages/scripts to provide higher levels of functionality. The regression package utilizes Autobench to drive a suite of benchmarks to collect a comprehensive set of data to evaluate various aspects of kernel performance. The suite of benchmarks covers components such as filesystems, scheduler, block I/O, kernel primitives (including system calls and memory latency) networking and memory management. Multiple aspects are evaluated for many of the components, such as different block sizes for filesystems, RAW vs. buffered I/O and so on). In all, the regression package supports about a dozen different benchmarks and can be extended easily to support even more.
After detecting new work, the regression package constructs an Autobench dat file containing the necessary commands to retrieve and build the newly detected kernel/patchset and executes the suite of regression benchmarks/variations. The new dat file is placed in one of the regression machine's remote queue for execution. Once the dat file has been executed, the output/results of the benchmark suite is moved to a common location in preparation for the post-processing phase of the regression process.
Post processing is a series of steps that distill raw benchmark data as well as system state information collected by Autobench into an elemental form. This is accomplished by invoking a script for each benchmark that isolates data from benchmark output files, performs mathematical operations on one or more pieces of data—such as computing averages, differences and standard deviations—and produces summary files and any other benchmark data manipulations. In addition to parsing the raw benchmark output files, the benchmark post-processing scripts also can evaluate data from other sources, such as CPU utilizations, context switches, transfer statistics and networking activity. The format used is the gnuplot file format. This format represents (x, y) data in an ASCII file in a simple two column manner. The gnuplot file then can be fed directly into the gnuplot utility to produce graphs of any relevant data collected by a benchmark. Compared to reviewing benchmark results in raw or tabular form, graphs are useful for conveying large amounts of information to the viewer in an efficient manner, and they aid in the ability to notice trends or other interesting characteristics within the results. Another benefit of this format is it allows easy comparison of one benchmark run to another, which is necessary to detect performance regressions.
To evaluate potential regressions, each benchmark's plot files are compared to the equivalent plot files from another kernel version. Each data point from both kernels plot files is compared. The differences then are compared against a predefined set of tolerances. If the new kernel's data point varies by more than what is allowed, that specific result is flagged as an improvement or as a regression. Each benchmark has a unique script that knows how to evaluate and compare each of its plot files. This script creates a comparison report, in HTML, showing the results of the old kernel vs. the results of the new kernel along with the delta, the % difference and the maximum tolerance. Additionally, the comparison report is populated with links to the results graphs, allowing the viewer to review the results in either tabular or graphical forms (see Figure 2).
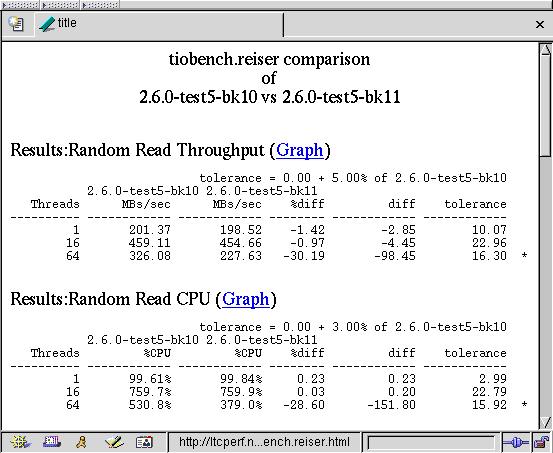
Figure 2. A Segment of a tiobench Benchmark Regression Report between Two Kernel Versions
As each benchmark's regression script is run, the comparison reports are linked to a kernel summary HTML page that contains summary lines for all the benchmarks. Each line in the summary contains the benchmark name, the pass/fail status, indications of detected improvements or regressions, links to the raw benchmark results for both kernel versions and a link to the benchmark comparison report clearly describing the differences (see Figure 3).
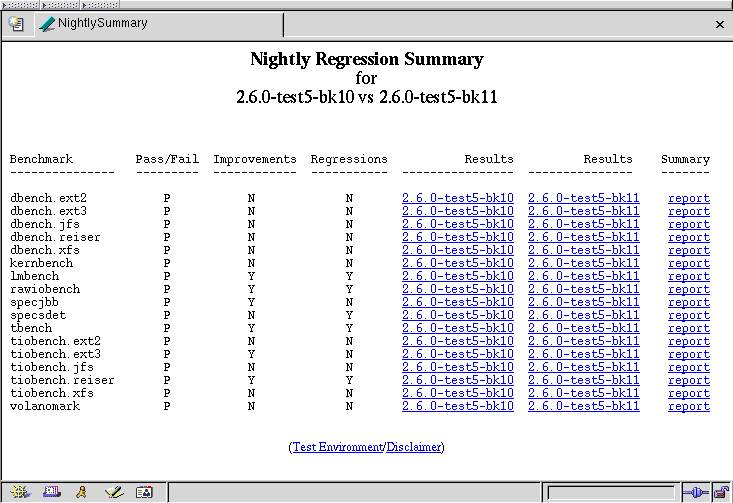
Figure 3. A Nightly Kernel Regression Summary
It is relatively easy to recognize significant differences between kernel versions. Subtle changes, however, are much harder to detect. If a 1% deviation was seen between two kernel versions, it likely would be dismissed as a typical run-to-run repeatability variation. What if the next kernel version changes by another 1%? And the next, and so on. By themselves, the 1% deviations don't seem significant, but if you look at the trend over time it would be obvious that something is degrading. This leads to the value of showing results not only between two kernel versions but also over time, so that subtle yet real regressions can be seen.
To solve this problem of slow regressions, the notion of history graphs was created. History graphs take a single data point (from a plot file) and track that value across the entire range of kernel versions. To produce the history graphs, each data point is taken from selected benchmark plot files from all kernel versions. A graph plotting each data point is produced, with each kernel version representing a different x-axis data point. By leveraging the plot files created during the regression phase, history graph creation was standardized across all the benchmarks without the need for benchmark specific scripts (see Figure 4).
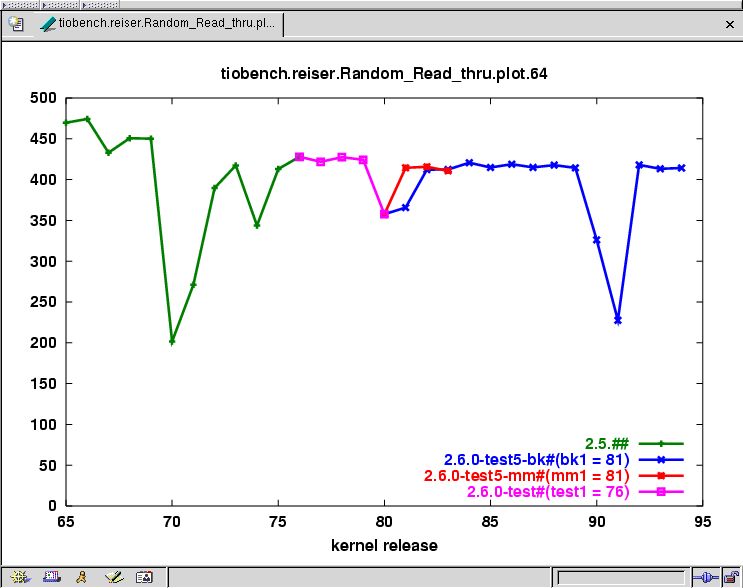
Figure 4. tiobench History Graph of 64-Thread Random Read throughput on ReiserFS.
This package currently runs approximately a dozen benchmarks on a pair of eight-way Pentium III machines. To date, it has identified 30+ regressions and problems across the -bk, -mm and -mjb development trees. With additional benchmarks and machines performing regression testing, we are confident that an even greater number of problems can be found. Additionally, more development trees or machines of different architectures could be added to widen the scope of coverage.
Resources
History Graphs of 300+ Data Points from Various Benchmarks for 2.5.65 to Current: ltcperf.ncsa.uiuc.edu/data/history-graphs
IBM Linux Technology Center Performance Team Web Site: www-124.ibm.com/developerworks/opensource/linuxperf
IBM Linux Technology Center Web Site: oss.software.ibm.com/developerworks/opensource/linux
Nightly Regression Kernel Version Summary Repositor: ltcperf.ncsa.uiuc.edu/data
Mark Peloquin is a Senior Software Engineer in IBM's Linux Technology Center. Mark has spent the past 11 years in operating system development and the most recent four years working on Linux in filesystems, block device drivers and kernel performance.
Steve Pratt is a Senior Software Engineer at IBM working in the Linux Technology Center. He has worked on operating systems for the past 14 years and has been working on the Linux kernel and related code for the last four years.
Ray Venditti is a Senior Software Development Manager working in IBM's Linux Technology Center. He spent many years working on IBM's mainframe computers as both a software developer and as a manager of software engineers before moving to IBM's desktop operating system, OS/2. He's had various management assignments since joining the LTC four years ago.
