
Embedding an SQL Database with SQLite
SQLite is a powerful, embedded relational database management system in a compact C library, developed by D. Richard Hipp. It offers support for a large subset of SQL92, multiple tables and indexes, transactions, views, triggers and a vast array of client interfaces and drivers. The library is self-contained and implemented in less than 25,000 lines of ANSI C, which is free to use for any purpose. It is fast, efficient and scalable, and it runs on a wide variety of platforms and hardware architectures ranging from ARM/Linux to SPARC/Solaris. Furthermore, its database format is binary-compatible between machines with different byte orders and scales up to 2 terabytes (241 bytes) in size.
Hipp conceived of the idea of SQLite while working with a team from General Dynamics on a program for the US Navy for use onboard the DDG class of destroyers. The program ran on HP-UX and used an Informix database. As they began the project, they quickly found that Informix can be rather difficult to work with. It runs fine once you get it going, but it can take a full day for an experienced DBA to install or upgrade.
At the time, the team was using Linux and PostgreSQL for development work. PostgreSQL required considerably less administration, but they still wanted to be able to produce a standalone program that would run anywhere, regardless of what other software was installed on the host platform. In January 2000, Hipp and a colleague discussed the idea of writing a simple embedded SQL database engine that would use GDBM as its back end, one that would require no installation or administrative support whatsoever. Later, during a funding hiatus, Hipp started writing it on his own, and SQLite version 1.0 soon came to life.
General Dynamics started using SQLite in place of PostgreSQL right away. SQLite allowed them to generate a standalone executable that could be installed quickly and easily on wearable computers and laptops for display at tradeshows and sales meetings. Informix still is being used for shipboard operation; however, the Naval office in charge of ongoing maintenance of the program recently has been e-mailing Hipp for help in compiling SQLite on an HP 9000. So, things may be changing.
Major changes came about with version 2.0. Version 1 used GDBM for storage, which uses unordered keys (aka hashing). This limited what SQLite could do. Furthermore, GDBM is released under the GPL, which discouraged some from trying it. In January 2001, Hipp began working on his own B*Tree-based back end to replace GDBM. The new B*Tree subsystem stores records in key order, which permits optimizations such as logarithmic time MIN() and MAX() functions and indexed queries with inequality constraints. It also supports transactions. The end result was a much more capable database. Version 2.0 was released into the public domain in September 2001.
SQLite started to take off with version 2.0. Dozens of people began writing in to tell how they were using it in commercial and free products. A few even contracted Hipp for technical support or custom modifications. According to Hipp, at least one widely used program for Windows incorporates a modified version of SQLite in recent releases. SQLite also is being used at Duke Energy and in other branches of the US military, besides the Navy project that originally inspired it.
Since its public release a year and a half ago, SQLite has been gaining features and users at a speedy clip. A quick look at the SQLite Wiki reveals many more applications whose developers have discovered SQLite and put it to use in their software. It even has its own Apache module (mod_auth_sqlite), which seems to be a sign of success in its own right. As the creators of PySQLite, a Python extension for SQLite, Gerhard Häring and I have been surprised to see more than 3,000 downloads in less than a year. Currently, SQLite is the highest-rated database engine on <@url>freshmeat.net.
SQLite has an elegant, modular design. It can be divided into eight primary subsystems (Figure 1), some of which take rather interesting approaches to relational database management.
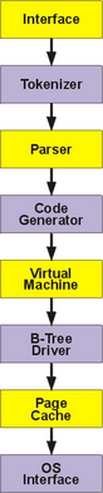
Figure 1. SQLite Architecture
At the top of the diagram is the parser and tokenizer. SQLite includes its own highly optimized parser generator, called the Lemon parser, which produces fast, efficient code, and by virtue of its novel design, it is especially resistant to memory leaks. At the bottom is an optimized B-Tree implementation, based on Knuth, which runs on top of an adjustable page cache, helping to minimize disk seeks. The page cache, in turn, operates on an OS abstraction layer that helps make the library more portable.
At the library's core is the virtual database engine. The VDBE performs all operations related to data manipulation and is the broker through which information is passed between client and storage. In many ways, it is the heart of SQLite. The VDBE comes into play after the SQL is parsed. The code generator takes the parse tree and translates it into a mini-program, which is made up of a series of instructions expressed in the VDBE's virtual machine language. One by one, the VDBE executes each instruction, which ends by fulfilling whatever request was specified in the SQL statement.
The VDBE's machine language consists of 128 opcodes, all centered around database management. There are opcodes for opening tables, searching indexes, storing and deleting records and many other database operations. Each instruction in the VDBE consists of an opcode and up to three operands. Some instructions use all three operands; others use none. It all depends on the nature of the instruction. For example, the Open instruction, which opens a cursor on a table, uses all three operands. The first operand (P1) contains the ID by which the cursor will be identified. The second operand (P2) refers to the location of the root (or first) page of the table, and the third operand is the table's name. The Rollback instruction, on the other hand, requires no operands at all. The only thing the VDBE needs to know in order to perform a rollback is whether or not to do one.
For any given SQL statement, you can view the generated VDBE program using the explain command in the SQLite shell. Listing 1 shows a simple example.
Listing 1. explain Results for a Simple Query
explain is not only useful for gaining better insight into the workings of the VDBE but also for practical matters like query optimization. The VDBE is really a subject in itself. Fortunately, for those who are interested, it is well documented, and its theory of operation along with its opcodes are covered in great detail on the SQLite web site.
With respect to physical storage, each database is stored in a single file. That is, all database objects that comprise an individual database (views, triggers, indexes, tables, schema and so on) reside together in one file that defines an SQLite database. Database files are made up of uniformly sized pages. Page size is set upon database creation, and valid sizes range from 512b-4Gb. By default, SQLite uses a 1Kb page size, which seems to offer the best overall performance.
Transactions are implemented using a second file called the journal, which only exists when there is one or more active connections to the database. Each database has exactly one journal file. It holds the original (unmodified) pages that were changed in the course of a transaction. When the transaction commits, the journal pages are no longer needed and are summarily discarded. Rollbacks are performed by restoring pages from the journal file to the database file. The use of the journal file ensures that the database always can survive a crash and be restored to a consistent state. The first client to connect to a database after a crash triggers a rollback of the previous transaction. Specifically, when the client connects, SQLite tries to create a new journal file, only to find that a previous one exists. When this happens, it infers a crash must have occurred and proceeds to copy the contents of the old journal file back into the database, effectively restoring it to its original state before the crash. Then it gives the client the go-ahead to start working.
SQLite has an extremely easy-to-use API that requires only three functions with which to execute SQL and retrieve data. It is extensible, allowing the programmer to define custom functions and aggregates in the form of C callbacks. The C API is the foundation for the scripting interfaces, one of which (the Tcl interface) comes included in the distribution. The Open Source community has developed a large number of other client interfaces, adapters and drivers that make it possible to use SQLite in other languages and libraries.
Using the C API requires only three steps. Basically, you call sqlite_open() to connect to a database, in which you provide the filename and access mode. Then, you implement a callback function, which SQLite calls for each record it retrieves from the database. Next, call sqlite_exec(), providing a string containing the SQL you want to execute and a pointer to your callback function. Besides checking for error codes, that's it. A basic example is illustrated in Listing 2.
Listing 2. Basic C API Example
One of the nice things about this model that differs from other database client libraries is the callback function. Unlike the other client APIs where you wait for the result set, SQLite places you right in the middle of the result-gathering process, in the thick of things as they happen. Therefore, you play a more active role in fetching data and directly influence the retrieval process. You can aggregate data as you collect it or abort record retrieval if you want. The point is, because the database is embedded, your application is essentially as much the server as it is the client, and SQLite takes full advantage of this through the use of its callback interface.
In addition to the standard C API, an extended API makes it even easier to fetch records, using sqlite_get_table(), which does not require a callback function. This function behaves more like traditional client libraries, taking SQL and returning a rowset. Some of the features of the extended API are functions to extend SQL by adding your own functions and aggregates, which is addressed later in this article.
Finally, if for some reason you need an ODBC interface, I am pleased to inform you that one is available, written by Christian Werner. His ODBC driver can be found at www.ch-werner.de/sqliteodbc.
While SQLite does not support sequences per se, it does have an auto-increment key and the equivalent of MySQL is mysql_insert_id(). A primary key can be set to auto-increment by declaring it INTEGER PRIMARY KEY. The value of the last inserted record for that field is obtained by calling sqlite_last_insert_rowid().
You can store binary data in SQLite columns with the restriction that it only stores up to the first NULL character. In order to store binary data, you must first encode it. One possibility is URL-style encoding; another is base64. If you have no particular preference, SQLite makes life easy for you through two utility functions: sqlite_encode_binary() and sqlite_decode_binary().
SQLite is as threadsafe as you are. The answer more or less centers around the SQLite connection handle returned by sqlite_open(). This is what should not be shared between execution contexts; each thread should get its own. If you still want threads to share it, protect it with a mutex. Likewise, connection handles should not be shared across UNIX fork() calls. This is more common sense than anything else. Bottom line: thread or process, get your own connection handle, and everything should be fine.
SQLite uses the concept of a pragma to control runtime behavior. Pragmas are parameters that are set using SQL syntax. There are pragmas for performance tuning, such as setting the cache size and whether to use synchronous writes. There are some for debugging, like tracing the parser and the VDBE, and others still are for controlling the amount of information passed to client callback functions. Some pragmas have options to control their scope, having one variant that lasts only as long the current session and another that takes effect permanently.
SQLite sorts a column lexigraphically if, and only if, that column is declared as type BLOB, CHAR, CLOB or TEXT. Otherwise, it sorts numerically. SQLite used to make decisions on how to sort a column solely by its value. If it “looked” like a number, then it was sorted numerically, otherwise lexigraphically. A tremendous amount of discussion about this appeared on the mailing list, and it eventually was refined to the rules it uses today, which allow you to control the method of comparison by the declared type in the schema.
As mentioned earlier, many client interfaces have been developed for SQLite. To give you a taste, a Python version of the previous C example is illustrated in Listing 3, and its Perl counterpart is shown in Listing 4. It doesn't get any easier. SQLite also can be used from the shell, which makes it amenable to system administration tasks. A shell version of our stock example is provided in Listing 5.
Finally, because I am not a Java, Tcl, Ruby, Delphi, Lua, Objective C, PHP, Visual Basic, .NET, Mono, DBExpress, wxWindows, Euphoria or REXX programmer, I will have to refer the likes of you who are, to the SQLite Wiki to find your respective interfaces. See cvs.hwaci.com:2080/sqlite/wiki?p=SqliteWrappers for your preferred way to talk to SQLite.
SQLite includes a nice C framework in which to create your own functions and aggregates that can be called from SQL. Some wrappers, such as the Python wrapper, allow you to use this feature to implement them in the extension's language. SQL, such as INSERT INTO orders purchase_date values CURRENT_TIME(), is a simple matter of writing a callback function that looks something like Listing 6. Then, register the function and use it as shown in Listing 7.
Listing 6. Implementation of CURRENT_TIME()
Listing 7. Using CURRENT_TIME()
All of SQLite's built-in functions, such as avg(), min(), max() and sum(), with the exception of the magical typeof(), are implemented using this API. User-defined aggregates can be added just as easily. Doing something like SELECT variance(age) from population uses a very similar approach to creating functions. This, however, is left as an exercise for the reader. Hint: the file func.c includes some excellent examples. Like functions, SQLite uses the API to implement its aggregates as well.
For administration, SQLite offers an intuitive utility program conveniently named sqlite with which users of MySQL and PostgreSQL will feel perfectly at home. It has both shell and command-line modes. Within the shell, you can view a database's tables, schema and indexes, as well as execute SQL on the command line and in external files. It also has some nice modes for viewing data and VDBE output.
Though loading and unloading data can be done within the shell, it is even easier on the command line. Given a file containing valid DDL/DML (call it dump.sql), you can load it into a database (call it db), like so:
sqlite db < dump.sql
This creates the database db if it doesn't exit. The reverse process to dump a database would be:
sqlite db .dump > dump.sqlSQLite is powerful. Its wide application, ease of use, portability, speed, scalability, small footprint and clean code base make it a library that all programmers should have in their arsenals. And given its license, there is simply no reason not to. The SQLite Project is always looking for new users and developers, and it welcomes new ideas and engaging discussion. I hope you enjoy learning about and using it as much as I have.


