
CORBA, Part I
Over the last 20 years or so, object-oriented programming techniques have matured from a curiosity to a major component of almost every software engineer's programming toolbox. The reason for this growth is easy to understand: object-oriented programming techniques help software engineers solve real problems, that is, constructing and maintaining software products.
In the Linux world, one can find object-oriented programming techniques realized in a variety of programming languages, including Perl, Python, Java and C++. Even though these programming languages utilize different programming constructs to realize object-oriented techniques, they all have one thing in common: the mechanism they employ to invoke an object's method. In all of these languages, an object's method is invoked by treating the method as if it were a regular function/procedure, providing a special reference to the object with which the method is associated. For example, C++ uses the keyword “this” while Python uses the keyword “self” to refer to the object.
The designers of these various programming languages have chosen to use this mechanism because it works and because it provides the best performance as compared to alternative mechanisms—an excellent design trade-off, but there is a problem. For those who construct applications that use multiple processes, this mechanism prevents them from using object-oriented techniques between processes. Simply stated, it is not possible to invoke an object's method in one process from an object in another process.
CORBA (Common Object Request Broker Architecture) is a specification for an architecture that provides support for invoking methods in objects that may exist in a different process. The CORBA architecture is based on the concept of a common object. Figure 1 shows how common objects interact. This figure shows how a request from one object, the left-most object in the figure, can be sent to an object existing within the same process, within another process running on the same processor or within another process running on a different processor. From the viewpoint of the requesting object, it does not matter where the object to which the request is being sent exists. It is the responsibility of a component of the CORBA architecture known as the ORB (Object Request Broker) to ensure that the request is delivered to the correct object.
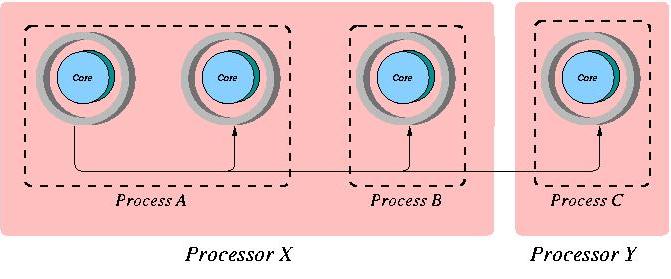
Figure 1. Method Invocation in CORBA
In order to better understand and appreciate what CORBA is, we are going to construct a simple CORBA application. This application consists of two objects, a server that can handle requests to get the current processor load and a client that makes requests for this information. These two objects are created in different processes.
The first thing to do in constructing a COBRA application is specify the interface for the object that will handle the requests. This interface is visualized in Figure 1 as a ring that surrounds the core of the object. One makes this specification using CORBA's Interface Definition Language (IDL). This IDL is formally known as the OMG IDL, OMG being the Object Management Group responsible for the CORBA specification. The specification for this interface specifies the methods (functions) supported by that interface.
The server we are constructing supports only a single method that can be invoked to determine the current CPU load. Listing 1 shows the specification for the CPULoad interface. This interface declares the method getLoadAvgs, which has three parameters: oneMinAvg, fiveMinAvg and tenMinAvg. These three parameters are all of the type float. CORBA's float data type is the same as the C/C++ float data type. In fact, the CORBA IDL supports most but not all C/C++ data types. The out keyword is used to specify that this parameter is an output parameter—a parameter used to return data to the method's invoker. The keywords in and inout can be used in place of out; in informs that the parameter is an input parameter, and inout indicates that the parameter is used as both an input and an output parameter.
Listing 1. The CPULoad Interface
// File: cpuLoad.idl
interface CPULoad {
void getLoadAvgs(out float oneMinAvg,
out float fiveMinAvg,
out float tenMinAvg);
};
Now that the interface has been specified, it needs to be processed so it can be used to build the required executables. IDL specification are processes using IDL compilers (Figure 2).
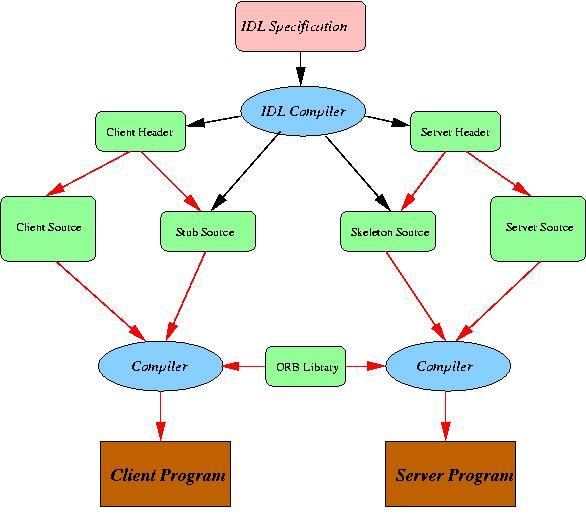
Figure 2. Creating the Client and Server Programs
The IDL compiler takes the specification and processes it to produce two header files, a client and a server header file, and two source files, a stub source file for the client and a skeleton source file for the server. The header and source files contain the declarations and code necessary to build a working CORBA program. Once the header and source files are produced, they are compiled and linked with either the client or source object files to produce a working executable.
The source and header files produced by the IDL compiler are language-specific. This is a strong feature of the CORBA specification, because it means you probably can use CORBA with your favorite programming language. If you have a favorite programming language, you need to find an IDL compiler that supports your language of choice. However, before rushing off to select an IDL compiler, we need to mention one other caveat of IDL compilers—they are targeted at a specific ORB. If you select an IDL compiler, you must use the ORB that the compiler targets. Conversely, if you choose an ORB, you need to use one of the IDL compilers targeted for that ORB. Given that the ORB has the biggest impact on performance and supported features, one usually selects an ORB and then the IDL compiler.
Another important aspect of ORBs and IDL compilers needs to be mentioned here. The ORB and IDL compiler used to build a CORBA executable—for example, the server program—do not have to be the same ORB and IDL compiler used to build a different CORBA executable, say, the client program. This is true even if the executables need to interoperate. The only information that needs to be shared is the IDL specification.
In this article, we use the DOC Group's TAO ORB, which was selected for three reasons: it is open-source, it is ported to a large variety of platforms, including Linux, and it is an efficient, full-featured ORB. The drawback to choosing TAO, from some developers' viewpoint, is it supports only C++.
Now that the IDL specification has been written, and an ORB and IDL compiler have been chosen, we can process the IDL specification. The Makefile shown in Listing 2 explains how to invoke the TAO IDL compiler, tao_idl, to process the IDL specification.
Listing 2. The Makefile
# file: Makefile
# Note, change this to reflect where ACE/TAO
# is installed
ACE_ROOT= \
/home/Work/Sky/Packages/ACE-TAO/ACE_wrappers
ACE_CPPFLAGS= -D_POSIX_THREADS \
-D_POSIX_THREAD_SAFE_FUNCTIONS \
-D_REENTRANT -DACE_HAS_AIO_CALLS \
-DACE_HAS_EXCEPTIONS \
-I$(ACE_ROOT)
ACE_LDFLAGS= -L$(ACE_ROOT)/ace -lACE -lpthread -lrt
TAO_ROOT= $(ACE_ROOT)/TAO
TAO_CPPFLAGS= -I$(TAO_ROOT) \
-I$TAO_ROOT/orbsvcs $(ACE_CPPFLAGS)
TAO_LDFLAGS= -L$(TAO_ROOT)/tao -lTAO \
-lTAO_PortableServer \
-lTAO_CosNaming -lTAO_Svc_Utils -lTAO_IORTable \
$(ACE_LDFLAGS)
TAO_IDL= $(TAO_ROOT)/TAO_IDL/tao_idl
CXXFLAGS= -W -Wall -Wpointer-arith \
-Wno-uninitialized $(TAO_CPPFLAGS)
LDFLAGS= $(TAO_LDFLAGS)
TARGETS= client server
all: $(TARGETS)
client: client.cpp cpuLoadC.o
server: server.cpp cpuLoadS.o cpuLoadC.o
cpuLoadC.o: cpuLoadC.cpp
cpuLoadS.o: cpuLoadS.cpp
cpuLoadC.h cpuLoadC.cpp cpuLoadS.h cpuLoadS.cpp:
↪cpuLoad.idl
$(TAO_IDL) cpuLoad.idl
clean:
$(RM) *.o *.i $(TARGETS) *_T.* cpuLoadC.* \
cpuLoadS.*
Processing an IDL file produces several files, only four of which are important to the application being built:
cpuLoadS.h: the header file needed by the server.
cpuLoadS.cpp: the skeleton source file needed by the server.
cpuLoadC.h: the header file needed by the client.
cpuLoadC.cpp: the skeleton source file needed by the client.
If you are using a different IDL compiler, the names of the files produced most likely will be different, so check the documentation.
Next, we produce the client and server sources files. Listing 3 contains the source code for the client program. Even though this file at first may appear to be somewhat overwhelming, it is actually quite simple.
Listing 3. The Client Source Code
// File: client.cpp
#include <string>
using std::string;
#include <fstream>
#include <iostream>
using std::cerr;
using std::cout;
using std::endl;
#include "cpuLoadC.h"
int
main(int argc, char *argv[])
{
try {
// First we initialize the ORB
CORBA::ORB_var orb = CORBA::ORB_init(argc,argv);
// Next we need to get the reference string for
// the server object. This string will be
// stored in the file ior.dat
ifstream iorFile("ior.dat");
if (!iorFile) {
cerr << "Failed to open ior.dat file" << endl;
throw 0;
}
string iorString;
iorFile >> iorString;
iorFile.close();
// Convert the reference string to an object
// reference and make sure its valid
CORBA::Object_var obj =
orb->string_to_object(iorString.c_str());
if (CORBA::is_nil(obj.in())) {
cerr << "Nil server reference" << endl;
throw 0;
}
// Cast it to the proper type
CPULoad_var cpuLoad =
CPULoad::_narrow(obj.in());
if (CORBA::is_nil(cpuLoad.in())) {
cerr << "Reference string does not refer "
"to a CPULoad server" << endl;
throw 0;
}
// Get the CPU load
CORBA::Float oneMinAvg;
CORBA::Float fiveMinAvg;
CORBA::Float tenMinAvg;
cpuLoad->getLoadAvgs(oneMinAvg, fiveMinAvg,
tenMinAvg);
// Tell the user what we got
cout << "CPU load:\n"
<< " One Minute: " << oneMinAvg
<< " Five Minute: " << fiveMinAvg
<< " Ten Minute: " << tenMinAvg
<< endl;
}
catch (const CORBA::Exception &x) {
cerr << "Uncaught CORBA exception" << endl;
return 1;
}
catch (...) {
return 1;
}
return 0;
}
The first thing one needs to do in a CORBA application is initialize the ORB, which is accomplished using the ORB_init() function. This function takes the argc/argv arguments, allowing one to pass initialization arguments through the program to the ORB. In this application, there is no need to pass any initialization arguments to the ORB.
Once the ORB has been initialized, we can access any CORBA object. In order to access an object, we need an object reference to that object. There are several different ways to generate an object reference. The method used in this example is to convert an object reference string to an object reference, using the ORB's string_to_object() method. Of course, this begs the question, how does one generate an object reference string? We are going to side-step this question right now and simply state that the object reference string has been provided for us in the file ior.dat. Thus, looking at the code, you can see that we open the file ior.dat, extract the object reference string from it and pass that string to the ORB's string_to_object() method.
The ORB's string_to_object() method returns a generic object reference—not quite what we want. Instead, we want an object reference to the common object that implements the CPULoad interface. In order to get this, we upcast the generic object reference to the specific object reference using the _narrow method associated with the CPULoad interface. The CPULoad interface, as used in C++, is nothing more than a class specification. Thus, we invoke the _narrow() method as shown in Listing 3.
A couple of things should be pointed out regarding the string_to_object() and the _narrow() methods. First, these methods return a pointer to a C++ object, a pointer to a CORBA::Object object in the case of string_to_object() and a pointer to a CPULoad object in the case of _narrow(). We assign these pointers to a variable of the type CORBA::Object_var for the pointer returned by string_to_object() and to a variable of the type CPULoad_var for the pointer returned by _narrow(). In CORBA applications, many types end in _var; they are data types created by the IDL compiler and are basically smart pointer data types. They are smart in the sense that they destroy the object to which they are pointing when they themselves are destroyed. In this example, when the variables obj and cpuLoad are destroyed (when the try block is exited), the objects to which they point also are destroyed automatically, freeing up any allocated memory.
The second thing to note about these functions is they may return a NULL pointer. The correct way to test for NULL pointers in CORBA is with the method is_nil(). As you can see in this example, we invoke this method to test the pointers returned by string_to_object() and _narrow(). Because is_nil() expects a pointer and not a smart pointer, we invoke the smart pointers in() method, which returns the pointer in a form suitable for passing into a method. The smart pointer also supports the out() and inout() methods that can be used to retrieve a pointer from a function or to do both (pass in and pass out).
At this point, one may think that CORBA is more complicated than it is worth. However, the truth is what we have covered up to this point is basically all boilerplate. Many programmers create template functions to do all of this, which can be invoked using a single function call.
The real beauty of CORBA shines through next. The line:
cpuLoad->getLoadAvgs(oneMinAvg,
fiveMinAvg, tenMinAvg);
demonstrates the power of CORBA. For those readers who know C++, this line appears to be a simple method invocation on the cpuLoad object. In reality, this method causes the remote invocation to occur. The results of that invocation are stored in the local variables oneMinAvg, fiveMinAvg and tenMinAvg. In other words, invoking the getLoadAvgs() method causes the ORB linked to the program to determine where the object is at which the invocation is directed, and then it sends the invocation message, receives the reply and stores the results. One simple line causes all of this to happen. Not only that, but by including the header files generated by the IDL compiler, this line is checked at compile time to make sure it conforms with the method specification, just as the compiler checks method invocations on local C++ objects.
For a server, one needs to create a CORBA object that supports the desired interface. In C++, this is handled by first specifying a new class that supports the interface. Once this class is specified, a C++ object is instantiated from the class. A side effect of this instantiation is the desired CORBA object is created. Let's look at the server code to see how this is done.
Listing 4. The Server Source Code
// File: server.cpp
#include <fstream>
#include <iostream>
using std::cerr;
using std::cout;
using std::endl;
#include "cpuLoadS.h"
// The CPULoad interface
class CPULoad_impl : public virtual POA_CPULoad
{
public:
virtual void
getLoadAvgs(CORBA::Float_out oneMinAvg,
CORBA::Float_out fiveMinAvg,
CORBA::Float_out tenMinAvg)
throw(CORBA::SystemException);
};
void
CPULoad_impl::
getLoadAvgs(CORBA::Float_out oneMinAvg,
CORBA::Float_out fiveMinAvg,
CORBA::Float_out tenMinAvg)
throw(CORBA::SystemException)
{
ifstream loadAvg("/proc/loadavg");
if (!loadAvg) {
cerr << "Unable to open /proc/loadavg" << endl;
throw 0;
}
loadAvg >> oneMinAvg >> fiveMinAvg >> tenMinAvg;
loadAvg.close();
}
int
main (int argc, char *argv[])
{
try {
// First we initialize the ORB
CORBA::ORB_var orb = CORBA::ORB_init(argc,argv);
// Get reference to Root Portable Object
// Adapter (POA)
CORBA::Object_var obj =
orb->resolve_initial_references("RootPOA");
PortableServer::POA_var poa =
PortableServer::POA::_narrow(obj.in());
// Activate POA manager
PortableServer::POAManager_var mgr =
poa->the_POAManager();
mgr->activate();
// Now create the CORBA object
CPULoad_impl cpuLoad;
// Given that the CORBA object is created, we
// need to register it with the ORB.
CPULoad_var cpuLoadRef = cpuLoad._this();
// Now that we have the reference, we need to
// convert it to astring so that we can make it
// available to the client
CORBA::String_var str =
orb->object_to_string(cpuLoadRef.in());
// Now that we have the reference string, we
// can save it so that the client can get it
ofstream iorFile("ior.dat");
if (!iorFile) {
cerr << "Failed to open ior.dat file"
<< endl;
throw 0;
}
iorFile << str.in() << endl;
iorFile.close();
// Now that everything is done, we can start
// the ORB so that it listens for requests.
orb->run();
}
catch (const CORBA::Exception &) {
cerr << "Uncaught CORBA exception" << endl;
return 1;
}
return 0;
}
The first thing we do in the server code is define a new class, named CPULoad_impl. This class inherits from the POA_CPULoad class, which contains the necessary support for creating the actual CORBA object. In the CPULoad_impl class specification, we declare the interface method, namely getLoadAvgs(), which was declared as a virtual method in the POA_CPULoad class.
Following the class specification is the implementation for getLoadAvgs(). This is the method that eventually is called when a remote invocation for getLoadAvgs() is received. Basically, this method returns the load information obtained from the proc filesystem.
For readers unfamiliar with C++, all that is going on here is a linking between a CORBA object's interface method and some actual code. This linking is handled differently in other languages, but the effect is the same: the code is executed when the CORBA object's method is invoked.
Now that we have specified what actions to take when a request is received, we need to initialize the ORB so it knows what to do when it receives a request. This is done in main(). As with the client code, the code in main may appear overwhelming at first. Keep in mind, however, that practically all of this code is boilerplate code.
As with the client code, the first action taken is to initialize the ORB. Next, we need to obtain a reference to the ORB's portable object adapter (POA). The POA is the piece of the ORB that manages server-side resources, handling all transactions within the ORB. We obtain a reference to the adapter with the ORB's resolve_initial_references() method.
Once we have obtained the POA reference, we need to activate its manager. We do this by first obtaining a reference to the manager using the POA's the_POAManager() method; then, we invoke the manager's activate() method. At this point, the POA is up and running, but the ORB is not yet ready to accept requests.
Before we enable the ORB to receive requests, we need to create and register the CORBA object that handles the requests with the ORB. The CORBA object is created as a side effect of instantiating an object from the CPULoad_impl class. Once created, we register the CORBA object with the ORB by invoking the cpuLoad's _this() method. The _this() method does two things. First, it registers the CORBA object with the ORB; second, it returns a reference to the CORBA object. This reference is required by any client wanting to make a request to the CORBA object.
Several ways exist to make a CORBA object reference available to clients. The simplest way, and the one used in this example, is to turn the reference into a string and publish the string, accomplished by invoking the ORB's object_to_string() method. Once we have the reference string, we can publish it simply by storing it in a file, in this case, the ior.dat file. If you remember back to the client code, this is how the reference string found it way into the ior.dat file.
Once we have published the reference, we basically are finished. The only thing left to do is start the ORB. We do this by invoking the ORB's run() method. At this point, the ORB is up and running, listening for requests.
To see how the application runs, build it using the Makefile shown in Listing 3. Once built, start the server and put it into the background, with ./server &. You need to wait a few seconds to make sure the ORB is up and running. Next, run the client, and you should see output similar to:
CPU load: One Minute: 0.25 Five Minute: 0.08 Ten Minute: 0.06
You can run the server easily on one node and the client on another node, as long as they share a common filesystem on which the ior.dat file can be created. The example we presented here, although simple, clearly demonstrates the major components of a CORBA application. With what you've learned, you should be able to build more complex applications.
In Part II, we will look at some of CORBA's more advanced features, including its sequence data structure and services.
Gerry Pocock has been working with multiprocessor systems since his undergraduate days at the Laboratory for Laser Energetics at the University of Rochester. Since then, he obtained his PhD from UMass at Amherst, worked as a professor at UMass at Lowell, worked as a consultant for various companies including Intel and held several full-time positions. He currently is chief software architect for Sky Computers, Chelmsford, Massachusetts.
