
Linux-Based USPS Mail Sorting System
The United States Postal Service has over 900 computer systems, each consisting of eight Linux machines, that are used to convert mail piece images into the destination address text. Seven are dual Pentium Pro 200s called slaves, and one is a single Pentium Pro that is the master. The master is a typical PC with a monitor, keyboard, mouse, floppy, hard disk and a CD-ROM drive. It has two Ethernet cards and one image capture board. (See the Sidebar for complete hardware/software information.) The other seven computers, called slaves, run the optical character recognition (OCR) algorithms. They only have a hard disk and an Ethernet card. This recognition system is shown in Figure 1, which also shows the network setup.
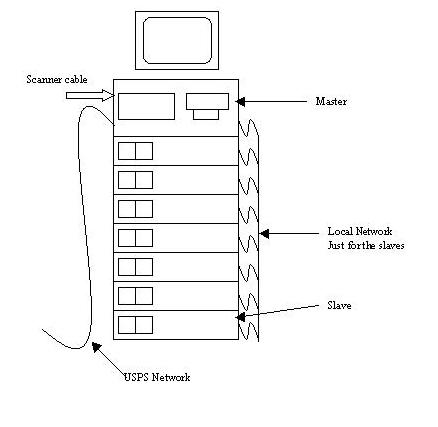
Figure 1. Network Setup
The mail sorter moves 12 mail pieces per second past a camera that captures the image. While the image is being recognized, the mail piece travels in a circuitous route and waits for the OCR results before it passes by a barcode printer. The camera has two output cables that send two pixels for each clock pulse, which cycles at 16MHz. One cable delivers a binary image, and the other has a grayscale image of 8 bits per pixel. A custom PCI image capture board resides in the master. This board can take either the grayscale or the binary image. The grayscale image arrives at 32MBps, which is too fast for the computer to do much with, so it isn't used in production. Instead, the binary image is used. The board packages the binary pixels into eight pixels per byte, then groups them into sets of four before putting them into the PC's memory using direct memory access (DMA).
The master computer then compresses the binary image and sends it to one of the seven slaves. Each slave runs two recognition processes, one for each CPU. When the slave process determines the destination address text, it returns it to the master. The master then forwards the results to another computer, which turns the text into a barcode for printing on the mail piece. Once the barcode is on the mail piece, the mail piece can be sorted over and over again without having to re-read the text.
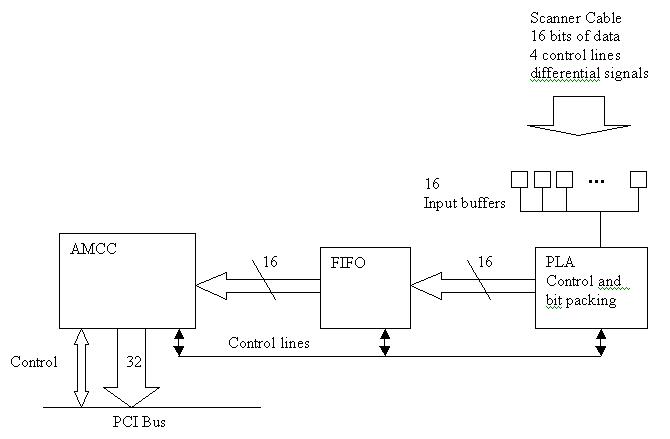
The image capture board uses an AMCC 5933 chip for the PCI logic, as shown in Figure 2. To that we added a FIFO and some PLAs. The PLAs pack the binary pixels into bytes, and they order both the grayscale and the binary bytes into longs. This process is diagrammed in Figure 3.

Figure 2. Image Capture Board
Figure 3. Block Diagram of Image Capture Board
At first, the device driver was designed to return the data via a call to read, with the thought that it would be like a normal file read. Fortunately we realized the silliness of trying to make a device driver for a custom image capture board compatible with common UNIX programs. On startup, the device driver allocates a big chunk of contiguous kernel memory. The AMCC is told to ``DMA'' the incoming data into memory. The user-space program requests that memory be mapped into its process space so that it can read from it. If we had returned the data via a call to read, there would be an extra copy of the data from the kernel buffer to the user-space buffer, which would have substantially increased processing overhead.
Whenever an end-of-mail-piece interrupt happens, the driver sticks the size of the last image onto the tail of a list of image start positions and sizes. It then checks to see if it can fit another image into the buffer. If it can't, it will reset the DMA to start at the top of the buffer. There is a physical gap between mail pieces on the scanner, so after the interrupt, there won't be any data for a moment. That moment is easily long enough for the interrupt to point the DMA back to the top. The start position of the new mail piece is put onto the tail of the list, and any sleeping user processes are awakened. The user process asks the driver for the position and size of the oldest mail piece. The driver returns the start and length from the head of the list of images. The user process looks like Listing 1.
Listing 1. Buffer Management for Mail Piece Images
By using mmap, the image data is not copied but is popped into memory by the AMCC DMA. Then the user program compresses it from that very location.
It was difficult for some of the developers to give up normal practices. If this was an image capture board for the general market, the driver would need to be more efficient with memory use, and the API for using it would need to be compatible with other image capture APIs. For a while we tried to achieve these goals, even though this driver wasn't for the general market. For example, we agonized about how to deal with buffer overflow. When the end-of-mail-piece interrupt occurs, the driver needs to calculate whether the oldest image was overwritten. If it was overwritten, it will need to tell the user process. From my description above, the driver will pop the last mail piece start position and size off its internal list and return that to the user process. The user process might take a long time to create the compressed data from that image, which means the DMA could overwrite that image. Therefore, the driver won't have a record of the start and size of that piece, so it won't be able to know for sure if the image was overwritten. You can see there is no code in order to lock the image buffer while the user process is using it. Fortunately, we realized there is no point in adding code and making it bulletproof, when all that was needed was a sufficiently large image buffer and a very conservative overflow flag. If the DMA ever gets within three maximum-sized mail pieces of the oldest image, the flag is raised. This flagging may be premature, but if the user process can't keep up, something is really wrong. This is an embedded system, so it doesn't make any difference if we hog lots of contiguous kernel memory and return errors prematurely. In other words, this error condition cannot happen in production. We must catch any occurrences of it in development and fix it so it won't happen later.
We designed a second-generation image board that can take images from a new camera specified by the USPS. The new camera had 2,048 pixels in the vertical direction instead of 1,024, and it sent four pixels per clock cycle at a rate of 20MHz. This meant that the grayscale image would arrive at a rate of 80MBps and the binary at 10MBps.
The new board used the PLX 9060, which is much easier to program for than the AMCC. The PLX can take a linked list of memory chunks and automatically make the DMA go from chunk to chunk. This allowed me to allocate normal kernel pages of 4K each. I hooked up the end of the linked list to the beginning, creating a loop, so the DMA never needed attention. The user process was modified so that mmap occurred inside the loop:
int ret = ioctl(inj,RPSI_GET_LAST,(void*)&ch);
if (ret < 0) { // handle over flow }
char *imageBufPtr = mmap(0,ch.size,…,inj,ch.start);
// now the image is at imageBufPtr
// contains ch.size bytes
munmap(…);
The driver will map the individual memory chunks into a single virtual buffer for the user space. This is nice because there is no special case for the end of the buffer. When asked to mmap the buffer, the driver finds the first respective chunk, then follows its linked list and tacks each chunk together until it reconstructs the full image.
The driver for the old board was changed to behave in the same manner. The AMCC doesn't support a linked list of buffers, but it will interrupt when it has filled one buffer. When this interrupt occurs, the driver sets the DMA to start on the next buffer in the list. This may take a moment to do, so while the DMA is stopped, the FIFO on the board starts filling up. The FIFO is big enough, and the interrupt is handled quickly enough, so that it doesn't overflow. With this change, the user process can use either board.
Both the old and the new image capture boards can collect grayscale images for testing purposes. To capture grayscale, I increased the size of the kernel memory buffer to almost the whole PC's memory. The user process writes images to the disk as fast as it can but has no hope of keeping up with the incoming data. In a matter of a few seconds, the driver will detect that the incoming data is about to overwrite the unused image data, so it shuts off the DMA and flags the error. The user process eventually reads all the images and is then given the error. It then resets the driver and starts again. There are several other ways to throttle back the data rate, one of which is to slow the scanner's feed rate. When the feed rate is slowed, the belt speed remains the same. This means that for the new scanner the data still comes in at a rate of 80MBps, but there are enormous gaps between the mail pieces. It was nice to see firsthand that the PCI bus can handle an 80MBps transfer and behave properly.
A big new feature we wanted to add to the system would enable the slaves to take images from more than one scanner. This will allow the USPS to locate the slaves in a central location and off the processing floor, where paper dust is a big problem. It also would allow the USPS to add scanners and OCR capability to other mail-handling machines without having to add a whole stack of computers. We wanted to add key entry stations to the real-time recognition system, and we wanted to make an architecture where the image could be processed by different recognition algorithms in parallel.
We also wanted to reduce the replacement headaches caused by the poor design of the slave software. All the slave disks were created to have identical configurations, but in order to get a unique IP for the computer, the developers created a convoluted scheme. Each computer was booted by itself with a fixed IP. It then got a new IP from the master and wrote that to its disk. Once a disk received its real IP, it was stuck with it, making replacements difficult. For the upgrade, we tossed that silliness and used DHCP because we wanted all the disks to be identical and stay that way. With DHCP, each slave receives its IP from the master when booted.
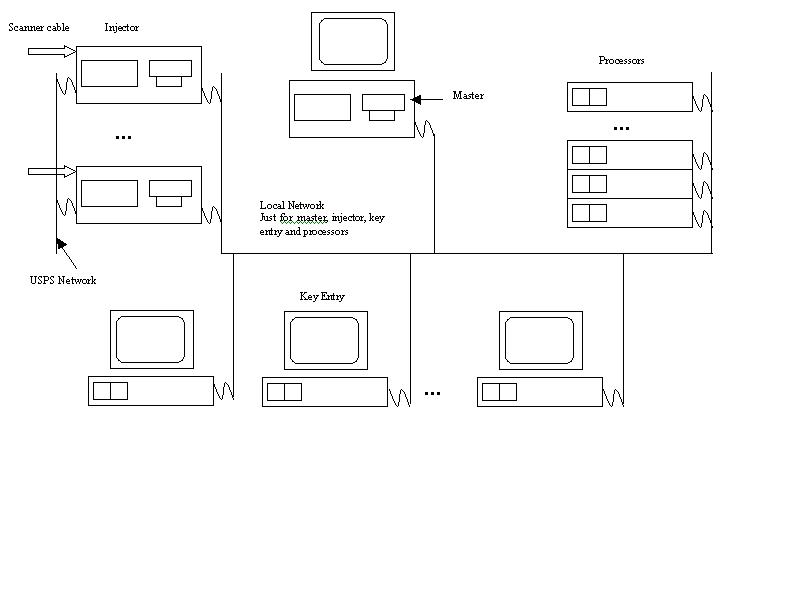
The new architecture has four different types of computers called master, injector, processor and key station, mapped out in Figure 4. Only one master is needed in each facility. Its job is to provide all the other computers with everything they need to operate and provide a user interface for the whole system. We wanted, therefore, just two types of disks, one for the master and one for all the others.
Figure 4. Four Computer-Type Architecture
Except for the master, all the disks are identical and called the client disk. The client disk has a kernel for booting and gets the IP using DHCP from the master and the root partition from the master using NFS. The fun part was making the three different clients behave differently, even though they were using identical client disks. We did that by making the client programs look for the various hardware they needed.
The injector has two Ethernet cards and a scanner card. The program that takes images from the scanner, called injector, will sleep forever if it can't open the scanner device. The device driver will not provide the scanner device if it can't locate a scanner board. The OCR processes will sleep while waiting for a flag that is set when the injector goes to sleep and for another flag that gets set when the key entry software goes to sleep. That way OCR is done only if it is not an injector and not a key entry station. The key entry user interface will sleep if it can't find an X server locally, and the X server won't run without a video card.
The master disk was also changed so that almost the whole filesystem is read-only. Only the directory where statistics and test data is written is writable. This means there is no need to do a filesystem check (fsck) at startup, which reduces the boot time and means you can just snap off the power to shut it down.
The old system dedicated a group of slaves to one scanner. In the new system we didn't want to assign either key entry or OCR computers to each scanner. We wanted a pool of computers that any scanner could send images to. To do that, we created a library of software that has both a sender and a receiver module. The sender module multicasts the images. All the receiver modules will take all the images, then request the right to process one of the images. The sender will grant the right to process each image to only one receiver. When the receiver is finished processing the image, it sends the results back to the sender. When the sender gets the results, it sends a message telling the receivers that they can free the image. On the other hand, if the sender detects a bad receiver, it can tell the other receivers to take the image that died on the bad slave hardware.
This multitasking system allows recognition of each mail piece with more than one algorithm to be a trivial task. There can be a set of processors that run the hand print algorithms and another set that runs machine print algorithms, for example. The sender will grant processing rights to one hand print and one machine print processor. It will then wait for both to finish before sending the best results off to the barcode printer.
Because we were developing this multicasting library, we were able to fix another problem with the old system. The developers of the old system implemented a multicasting protocol to send several hundred megabytes of data that the OCR algorithms need to recognize as hand print. The problem was that the old multicast algorithm was implemented so poorly that it was slower than sending the data sequentially using normal NFS. With so many multiprocessor computers and only one master, it is nice to be able to update the files for the whole group in the same time it takes to update one.

John Taves started Pacific Northwest Software (http://pnwsoft.com/) in 1998 to provide contract software development and consulting. He and his partner also founded Pick A Time (http://pickatime.com/), a startup that provides an Internet Appointment Book. He can be reached at jtaves@pnwsoft.com.
email: jtaves@pnwsoft.com

{kind=link}
{kind=link}