
Internet Traffic Measurement in Complex Networks
Knowing how much IP traffic is being served to a specific IP is information many people want. There are, at least, two standard ways of determining traffic levels:
Use SNMP monitoring at the routers' interfaces with MRTG, Cricket or any other program.
Make network devices export traffic flow information, collect such data and report from it, a process called flow-based accounting.
Although SNMP monitoring looks easier, it lacks resolution at the IP address and TCP/UDP port level. Also, if the amount of requested MIB entries is big, it can generate high usage loads on the CPU in the monitored devices. On the other hand, flow-based accounting, standardized on Cisco's NetFlow data export format, allows a great degree of flexibility and fine granularity, while having low CPU levels on network devices.
What makes flow-based accounting more attractive is that data can be obtained not only from many vendors' switches and routers, but also from Linux and other UNIX routers by using ntop's NetFlow export plugin. With this method, you don't even need a router to collect and report your network traffic information.
Schematically, network collecting data for flow-based accounting looks like this:

Although many proprietary and freely available NetFlow FlowCollectors exist, the same is not true for the data analysis software. Most available collectors only support storing data in text files or custom databases, making it difficult to extract accurate data later.
F.L.A.V.I.O. is a freely available (GPLed) tool specifically designed to parse ASCII files (from the filesystem or from STDIN) containing NetFlow data and load the result into a standard SQL database (MySQL), aggregating it for easy statistics reporting and graph generation. Currently the ASCII files come from Cisco's NetFlow Collector and OSU Flow-Tools Collector, but F.L.A.V.I.O. can be extended easily to support other formats as well. The graphs generated can be shown per IP address or per customer, and they can include TCP/UDP, interfaces and autonomous systems traffic information. Developed in Perl, F.L.A.V.I.O. also can be extended to customize data processing. Additionally, F.L.A.V.I.O. includes its own Perl-based collector dæmon that makes it a complete drop-in replacement for Cisco's NetFlow Collector solution.
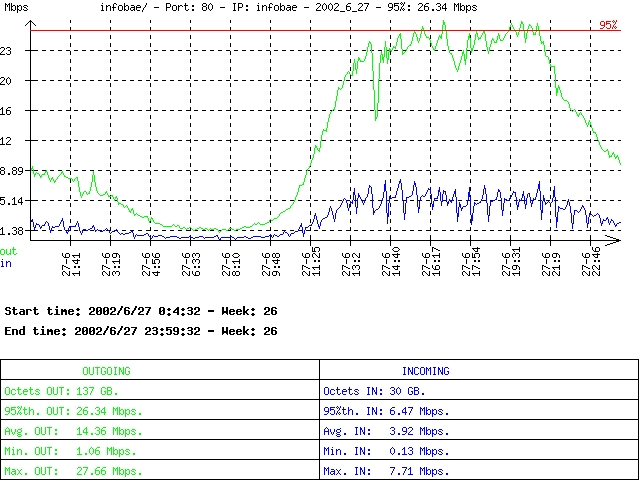
Figure 2. Sample Graph Generated by F.L.A.V.I.O.
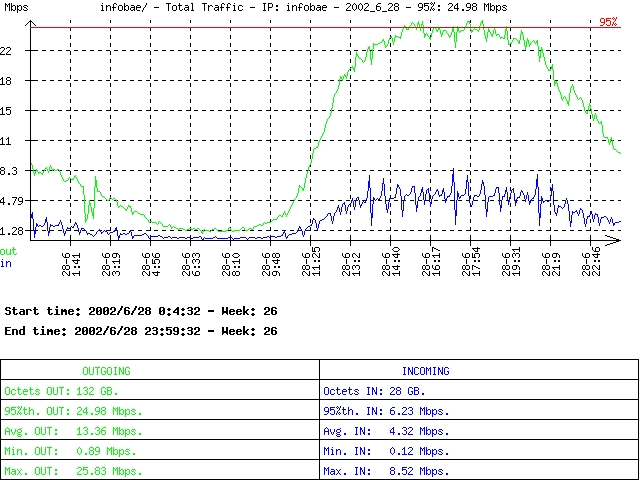
Figure 3. Sample Graph of a Total
Charts obtained from F.L.A.V.I.O.'s graph module are stored in a hierarchical directory tree, making it easy to integrate them into an intranet for direct reporting to customers. F.L.A.V.I.O. also generates 95th percentile information, useful for burstable traffic accounting and billing.
F.L.A.V.I.O. is comprised of by four small tools: netflow_collector.pl, netflow_parse.pl, netflow_aggregate.pl and netflow_graph.pl
netflow_collector.pl receives data flow files from routers in a UDP port and exports them to ASCII files. It's fully compatible with Cisco's NDE (NetFlow Data Export) flows version 1, 5 and 7. It's able also to call netflow_parse.pl every time it saves a flow file, passing the flow file as an argument. For example,
./netflow_collector.pl 9999 /var/flows/ ./netflow_parse.pl
is similar to
./netflow_collector.pl 9999 /var/flows
and to
./netflow_parse.pl C /var/flows/fileXXXX.flw
where fileXXXX.flw is each of the created flow files.
When using the - (dash) mode, flow files are not created. Instead, output is piped directly to netflow_parse.pl as standard input.
On-the-fly parsing modes won't work on platforms where Perl is not allowed to fork new processes (for many reasons, including the potential that flows will lose one of them). By default, netflow_collector.pl will save flow files every 300 seconds. Change $period in netflow_collector.pl to modify the standard behaviour.
To record warnings and errors, netflow_collector.pl will create an error.log file inside the flows directory.
netflow_parse.pl generates a daily table of the flow statistics. It creates one table per day, as the amount of daily data can be huge (more than 100,000 records per day for 100Mbps of peak traffic). The data for the tables is generated from the NetFlow Collector files, and records are loaded into the daily table.
netflow_aggregate.pl generates weekly, monthly and yearly tables for which the day passed to it as an argument belongs. It gets the data from the daily table, reduces it to its 1/6th for the weekly table, 1/12th for the monthly table and 1/24th for the yearly table. It also calculates the totals for each sample from the per-port information and uploads them into the weekly, monthly and yearly tables. If these tables do not exist, netflow_aggregate.pl creates tables for them.
netflow_graph.pl gets data from a single table and draws a chart for that information. It draws a green line for output and a blue line for input, scaling Y and X axes accordingly. It adds a legend to the graph that contains basic reference data and the 95th percentile information.
F.L.A.V.I.O. requires:
Perl 5.0 or newer
Mysql 3.23 or newer
Perl DBD/DBI modules for MySQL
Perl GD module
A network collector and an exporter device
The following steps explain what is necessary to install F.L.A.V.I.O. on a system. Be sure to replace things such as "localhost", "customer1_name" and "ip1_address" in the example code below with the proper information for your setup.
1. Create a NetFlow database in MySQL running, as root, the following SQL sentence from the MySQL command-line interface:
CREATE DATABASE netflow;
2. Create a NetFlow user, and give him or her total permissions on the NetFlow database:
USE mysql;
INSERT INTO user values ("localhost","netflow",password("whatever"),"N","N",
"N","N","N","N","N","N","N","N","N","N","N","N");
INSERT INTO db values ("localhost","netflow","netflow","Y","Y","Y","Y","Y","Y",
"Y","Y","Y","Y");
flush privileges;
3. Create a customers table in the NetFlow database:
USE netflow; CREATE TABLE customers (name varchar(30), ip varchar(15), username varchar(15), password varchar(15), last_ip varchar(15), INDEX (ip));
4. Add your customers-to-customers table, replacing customer_name and ip_address with the real data:
USE netflow;
INSERT INTO customers values("customer1_name","ip1_address","","","");
INSERT INTO customers values("customer1_name","ip2_address","","","");
INSERT INTO customers values("customer1_name","ip3_address","","","");
INSERT INTO customers values("customer2_name","ip4_address","","","");
INSERT INTO customers values("customer3_name","ip5_address","","","");
INSERT INTO customers values("customer3_name","ip6_address","","","");
For big customers with many consecutive addresses, use this simplified format instead:
INSERT INTO customers values("customer4_name","initial_address","","","last_address");
where initial_address and last_address are the initial and the last address of that block, respectively, assigned to that customer. The next time you run netflow_parse.pl, it will take care of these special records and convert them into normal one_ip_by_customer records.
5. Install the Perl DBI, DBD-mysql and GD modules, following their instructions. Summarily untar each one and run, as root, the following command sequence for each one:
perl Makefile.PL make make test make install
6. Untar FLAVIO-X.X.tar.gz in a directory. You'll get four files:
netflow_collector.pl netflow_parse.pl netflow_aggregate.pl netflow_graph.pl
Look at the first lines of each script, and change them if you want to use a different database name, user name or password.
Decide if you'll use F.L.A.V.I.O.'s netflow_collector, Cisco's collector or OSU's Flow-tools collector, and set the $format accordingly in netflow_parse.pl.
Set $diff_as to 1 in netflow_aggregate.pl if you want traffic differentiated by autonomous systems in your weekly, monthly and yearly tables. Set $diff_if to 1 in netflow_aggregate.pl if you want traffic differentiated by interfaces in your weekly, monthly and yearly tables.
Also change $multiplier factor in netflow_graph.pl if your routers feature multisampling; that is, if they export one every N flows. Optionally, set $fast_mode to 1 in netflow_parse.pl to speed up parsing. It may create bigger tables, but it will be significantly faster.
7a. If you're using Cisco's collector, review your NetFlow Collector configuration files and create at least two threads, one for incoming and one for outgoing traffic. Store each of them in a different directory tree. (This step is required in order to graph incoming vs. outgoing traffic). Make sure you're using DetailASMatrix for the aggregation type, as data file parsing depends on aggregation scheme. If the Aggregation format is different from DetailASMatrix, netflow_parse.pl will exit with an error.
Optionally, you can make the NetFlow Collector use a single thread for incoming and outgoing traffic. If you do this, pass the C flag to netflow_parse.pl, which will ask it to read the customers table to see if an IP is a valid internal IP. Of course, for this mode to work properly you need an up-to-date customers table, as it will record data only for valid IPs in the table.
F.L.A.V.I.O. is hardcoded to process five-minute files, so make sure your threads are configured for exporting at five-minute intervals. Otherwise, the resulting values will be wrong, and netflow_parse.pl will exit with an error.
Make sure you have your NetFlow Collector files in uncompressed ASCII format. If they are binary files, transform them to ASCII files with Cisco's bin_to_ascii tool. If they are compressed, use gunzip to uncompress them.
Create a shell script with a simple for/next loop to pass each data file as an argument to netflow_parse.pl:
for a in outgoing_data_dir/date/*; do ./netflow_parse.pl S $a; done for a in incoming_data_dir/date/*; do ./netflow_parse.pl D $a; done
7b. If you're using F.L.A.V.I.O.'s netflow_collector, set @valid_routers in netflow_collector.pl to allow it to receive flows from your real routers. Then, create a directory to store flow files and the error.log.
You can execute netflow_collector.pl in one of three ways. The standard way let flows in ASCII format be ready for batch processing from netflow_parse.pl. The on-the-fly parsing mode (with backups) runs netflow_parse.pl every time a new flow file is created (once every five minutes by default) with the C tag and the flow file as arguments. The on-the-fly without backup mode run netflow_parse.pl with the C tag and - arguments, passing flows through as standard input (flow files are not created inside flows directory).
The syntax for these three options, respectively, is:
./netflow-collector.pl 9876 /var/flows/
./netflow_collector.pl 9876 /var/flows/ ./netflow_parse.pl
./netflow_collector.pl 9876 /var/flows/ ./netflow_parse.pl -
7c. If you're using the OSU Flow-tools collector module, create a directory to store flow files. Once the directory is present, pass uncompressed ASCII files to netflow_parse.pl using flow_print format 5.
8. Run netflow_aggregate.pl to generate weekly, monthly and yearly tables, and then run netflow_graph.pl to graph everything. Replace the year, month and day entries with actual dates, and do not pad year, month and day entries with left zeros. Next, replace data_root_directory accordingly. Then create a cron job to run the whole thing once a day, collecting the previous day's data.
./netflow_aggregate.pl YEAR MONTH DAY cd /data_root_directory/ /path_to_FLAVIO/netflow_graph.pl YEAR_MONTH_DAY (i.e. 2002_4_17) /path_to_FLAVIO/netflow_graph.pl WYEAR_WEEK (i.e. W2002_16) /path_to_FLAVIO/netflow_graph.pl MYEAR_MONTH (i.e. M2002_4) /path_to_FLAVIO/netflow_graph.pl YYEAR (i.e. Y2002)
Optionally you could ask netflow_graph.pl to aggregate by customers' names instead of IP addresses by using the C tag. Or, should you need only to generate graphs for a single customer, pass the customer_name entry to netflow_graph.pl after the C tag.
9. Finally, set up Apache to look up the graphs in /data_root_directory/.
As of version 1.2.1, F.L.A.V.I.O has preliminary support for Flow-tools. netflow_parse.pl can parse and import records from files created from Flow-tools with the command
flow-cat <filename> | flow-print -f 5.
Change NetFlow's parse $format variable to FT, and change the $fixed_year to reflect the current year. Make sure your Flow-tools file format is 5, as this is hardcoded into F.L.A.V.I.O.
netflow_parse.pl fast mode (set $fast_mode to 1 to enable it) bypasses looking for existing records in daily tables in order to update them, if the new potential record matches. It may create bigger tables if more than one ASCII source file exists for the same period and for the same customer IP (for example, should you get information from multiple routers in the same path). But this is unlikely to happen. On the other hand, it will considerably speed up things because it will avoid a SELECT and an UPDATE to the big daily tables.
"Read flows from STDIN mode" is netflow_parse.pl's ability to read flows in ASCII format from STDIN. This mode bypasses the creation of temporary files when converting flows from binary formats. It can be used for on-the-fly database loading while uncompressing and converting files. Here's an example of what "Read flows from STDIN mode" looks like:
flow-cat <filename> | flow-print -f 5 | netflow_parse.pl C -
As mentioned before, netflow_graph.pl now supports a customer name after the C flag to draw graphs for a single customer; this process is called single customer graphing mode. To do this for customer foo_isp, enter netflow_graph.pl 2002_6_12 C foo_isp.
As of version 1.2.0, F.L.A.V.I.O. supports autonomous systems and interfaces parsing, recording, aggregating and graphing. Simply set $diff_as and/or $diff_if to 1 in netflow_aggregate and netflow_graph to generate records aggregated by autonomous systems and interfaces, and graph them accordingly.
We are currently using F.L.A.V.I.O. in Diveo Argentina's Internet Data Center to measure and record traffic information and to make it available in an intranet for our customers direct review. It has been useful, and it has provided us with great flexibility. Being that our network is based on Cisco Catalyst 6500 switches with hundreds of Ethernet interfaces, SNMP monitoring was not an option because of the routers' CPU usage. So we decided to run a flow-based accounting system. We configured NetFlow Collector to receive data from those switches. We offer an NFS share of the resulting ASCII files, which can be mounted from another server for data processing. F.L.A.V.I.O. parse, running on a different server, parses ASCII files and loads database records for the aggregate and graph modules.
Additionally, we use F.L.A.V.I.O. to analyze traffic directed to other autonomous systems in order to arrange for peer agreements and to invoice our customers accurately, according to the destination of the traffic.
1. F.L.A.V.I.O.: geminis.myip.org
2. NetFlow Collector: www.cisco.com/warp/public/732/Tech/nmp/netflow/index.shtml
3. OSU Flow Tools: www.splintered.net/sw/flow-tools/
4. ntop: www.ntop.org
5. MySQL: www.mysql.com
6. Perl: www.cpan.org
Flavio Villanustre is the director of operations of one of the biggest internet data centers in Argentina. He has been involved with Linux since 1993 and was the founder of the Buenos Aires Linux Users Group in 1994. He has been administering medium- and large-sized IP networks since 1995. When he's not working, he enjoys coding stuff for free, and he's currently involved in the development of the F.L.A.V.I.O. set of tools.
email: flavio@geminis.myip.org
