
A Cluster System to Achieve Scalability and High-Availability with Low TCO
[This article was accidentally overwritten, and is being reposted. -- Scott]
In this article, a commercial implementation of the Linux Virtual Server (LVS), developed by Wensong Zhang (see Resources), is discussed . The management cost of a web farm is a dominant portion of its total cost of ownership (TCO). In our product, numerous management features were added to the LVS to lower the TCO and to improve fault tolerance. Such additions included automated configuration, automated updating, failure recovery and integration with the Coda filesystem for content replication.
Furthermore, for scalability verification, load testing was conducted by an independent lab that collected performance benchmarks. The results verified our assumption that the system performance increases linearly as more web servers are added to the cluster. In spite of the modest hardware platform used in our version, the system was able to accommodate 400 million hits per day.
Web technology is utilized everywhere, and demands for faster and more reliable web operations have become a critical issue for conducting most business. More specifically, the following features are essential for any web farm.
Scalability--It should accommodate an increase in traffic without a major overhaul.
24 x 7 availability--Even a short downtime can cause millions of dollar in damage to e-commerce companies. A web farm should stay operational in spite of hardware and software failure.
Manageability--Management of the web farm must be effective, no matter how it was designed and/or configured.
Cost-effectiveness--The majority of the TCO is due to the management cost. Therefore, the most effective way to lower the TCO is to reduce the management cost.
A high-performance web farm can be developed in several ways. One could deploy a large single high-powered server. It is straightforward and does not require significant management effort because there is only one machine to manage. This approach, however, has two major problems, cost and scalability. A large high-powered server could cost $1 million. The utilization of such an expensive machine would probably never be at a proper level; it would probably be either underutilized or overutilized. If it is underutilized, the cost justification would be difficult. On the other hand, if it were overutilized, it would be necessary to replace it with yet another server that is even more powerful and expensive. Consequently, this solution does not provide a cost-effective solution with respect to scalability.
Another way to implement a high performance web farm is to use cluster technology. By designing the system with scalability in mind, a scalable yet cost-effective solution can be developed by exploiting inexpensive standard hardware boxes running Linux, known as a Linux Virtual Server (LVS). To date people with Linux and networking expertise have used LVS, and some commercial versions of LVS have been reported (see Resources).
The LVS architecture consists of one or more load balancers and multiple web servers that are loosely integrated. LVS comes in three options, NAT, tunnel and direct routing. The direct routing option is especially noteworthy because the load balancer does not become a bottleneck. In this architecture, both load balancers and web servers share the same virtual IP address and must be on the same subnet. The virtual IP address is a real IP address given to a single virtual server that may actually consist of one or more machines, as in Figure 1 (courtesy of Zhang) .
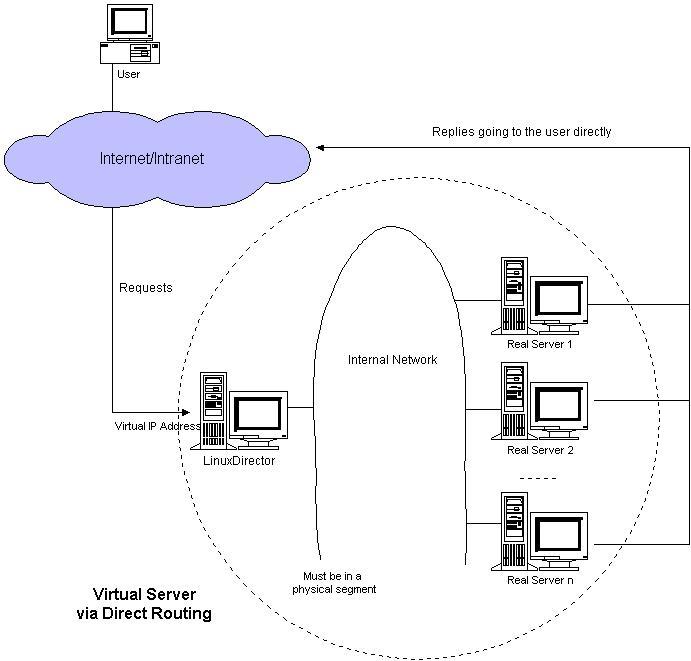
Figure 1. Linux Virtual Server: Direct Routing Option Network Topology
The load balancer receives a connection request from a web client, which is simply forwarded to an appropriate web server for processing according to the pre-set policy. A reply packet then goes back to the client without going through the load balancer. Such an architecture is well suited for web traffic because in normal web traffic, a requesting packet is typically short but the reply packet tends to be very long. Also, according to Zhang, when direct routing is used the overhead associated with forwarding packets on the load balancer is minimum, and performance will scale linearly as more servers are added.
The Coda distributed filesystem is designed as a client/server model and is available from Carnegie Melon University. It has numerous features that are suitable for a distributed filesystem. In our implementation, two of the web servers function as both Coda servers and clients, while the rest of the web servers function as Coda clients only. Two servers are provided to avoid a single point of failure. This choice was made to achieve:
Caching and high performance
High availability
Ease of management
Unlike NFS, Coda allows its clients to cache files so that subsequent access to the referenced files does not require fetching them from the Coda server. This allows quick access to the files without requiring a large storage area on each client. As more files are referenced and stored in the cache, access time to files is improved. Neilson showed that web page requests follow the Zipf distribution; i.e., web page requests tend to be localized, and only a handful of pages are usually referenced. Therefore, those pages often referenced are likely to be in cache, and access to those pages do not require any extra time.
Coda also brings high availability into the cluster. Coda has read/write replication severs that, as a group, provide files to clients and share updates in that group. This insures high availability of data. When one server fails, other servers can transparently take over for the clients.
The Coda filesystem is mounted uniformly among all the clients as /Coda. This contrasts with NSF, which allows any number of remote directories to be mounted. Managing multiple remote directories is cumbersome because all the names and access points must be correctly specified for mounting. Coda's single, uniform name to mount simplifies access to the filesystem for our web servers.
The minimum configuration of our product consists of five machines: 1) one central management station (EMS), 2) two load balancers (EDS) and 3) two web servers (EPS). Figure 2 describes one of the four network topologies supported by our product, although the EMS station is not shown in the figure. When a web farm is created, it often must be integrated into an existing overall network structure of a data center, including the assignment of IP addresses. Consequently, the configuration of the web farm should be flexible to accommodate the pre-existing environment. Other possible configurations include one router with either a private or public address on one of the router interfaces.
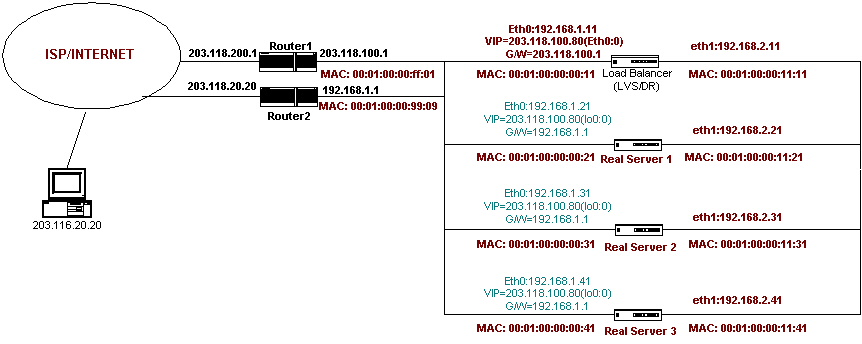
Figure 2. Our Network Architecture: VIP is a Virtual IP Address Shared by All the Machines in the Cluster
Note that the IP addresses and the MAC addresses shown in the figure are only for illustration. When a client machine (203.116.20.20) sends an HTTP request to the virtual server at its VIP (203.118.100.80), the load balancer intercepts the request. The virtual IP address (shared by all the clustered machines) is configured with the loopback interface for each web server and the eth0 interface for the load balancer. The loopback interface of each web server is configured not to reply to an ARP request for the virtual address. This is why the load balancer is the only one that receives the request packet. Once received, the load balancer decides which web server should service the request based on the preset algorithm ( e.g., round-robin and least connection). Let us assume that the Real Server 1 was chosen. The load balancer replaces the packet's MAC address (that of the load balancer) with the MAC address of Real Server 1 and pushes the packet onto the 192.168.2 subnet. When Real Server 1 receives the packet, it takes the packet for processing because its loopback interface is the destination IP address. The return packet then takes the VIP as the source address and is sent back to the client directly without going through the load balancer.
Moreover, because of the direct-routing option of LVS, the load balancer does not get involved in the transmission of the reply packet from the web server that processed the request. After Real Server 1 receives and processes the packet, the reply packet is sent directly back to the client via router 2. The load balancer acts as a Layer 4 switch, and switching is done in the kernel space rather than in the user space, minimizing the switching overhead. With these two design decisions, the performance should scale almost linearly as more web servers are added.
LVS is available open source. We have added a group of features, called the "operational aid", to LVS to enhance the ease of management and increase availability. We call this enhanced version of LVS a Single Virtual Machine (SVM). SVM makes it possible to manage multiple machines as if they were one single machine. Therefore, SVM = LVS + Coda + operational aid.
Let us take a look at each component of the cluster more closely. The EMS station is used to configure and monitor the cluster. Regardless of the number of machines in the cluster, this single management station provides centralized management for all the machines. The EMS contains an Apache web server, a configuration engine, a monitoring program, LDAP and FTP. The EDS unit has LVS and a web server. The EDS units come as a pair to prevent a single point of failure. The stand-by load balancer will take over if the master load balancer fails. Extra functionality was added to facilitate and provide close communications among EMS, EDS and EPS. In addition, the Coda system was integrated so that it shares the web contents across all the web servers.
In the following, each feature of the operational aid will be discussed.
Two initial installation methods are available. One method is to install and configure the system when all the machines are connected and on-line. When a support engineer configures the system on the EMS station, a set of configuration files is generated. Those configuration files are saved to a floppy disk, and the EDS unit reads the configuration files from the floppy disk during the first boot-up. If a new set of configuration files is introduced after the initial boot with the floppy, they are securely copied to the EDS unit via SSH. No matter how the configuration files are copied into the EDS unit, the EDS generates a set of configuration files for the EPS units. Those files in turn are copied to each EPS securely via SSH, and the EPS units configure themselves automatically.
The second method is called pre-configuration. Pre-configuration is performed with only the EMS station. When the configuration is specified using the EMS station, the generated configuration files can be stored on a floppy. This can be done without connecting the EMS station to the rest of the system. With this floppy, pre-installation is possible prior to a visit to the final installation location. The support engineer can run the EMS facility to create a floppy disk containing the configuration files at his/her office. He/she can dispatch a set of equipment to the installation site and use the floppy for the installation. At the installation site, the EDS unit configures itself automatically when booted with the floppy disk. After the EDS unit comes on-line, it generates the necessary configuration files, which are then transmitted to web servers.
If a component fails, the configuration files stored in the floppy can be used to restore the system. The EMS station generates two types of configuration files, an EMS backup copy and a backup copy for the EDS unit. When the EMS station fails and a replacement unit is brought in, the EMS can be easily restored with the backup floppy for the central management station.
If the master EDS fails, a replacement unit can be booted with the EDS backup copy to restore it to an appropriate state. When the EDS backup copy does not exist but the EMS backup copy does exist, a set of configuration files are generated for the EDS unit using the EMS station.
When the EPS unit fails, a replacement EPS unit may not be configured or populated with the web contents. Therefore, as it boots up, it contacts the load balancer via DHCP to obtain its IP address and necessary configuration information. If its configuration file is older than that on the EDS or is nonexistent, the appropriate configuration files are copied to the EPS via HTTP. After receiving the configuration file, the web server configures itself automatically and mounts the web contents via the Coda server. Consequently, there is no need to explicitly configure the web server or to copy the web contents.
The boot-up process consists of two phases. In the first phase, a mini OS is booted, and in the second phase, the main OS is invoked. After the mini OS is booted, it locates the main OS to invoke. The mini OS is stored in a partition of the filesystem that is different from the main OS. This two-phased approach increases the chance of stability even if the main OS gets corrupted or is not available. This boot-up applies to all the EMS, EDS and EPS units in the cluster.
In the future, if the main OS is not available or is corrupted, the mini OS will locate an appropriate version from somewhere like EMS . The mini OS can be stored in a removable Flash memory which would protect the mini OS from corruption or deletion, as the mini OS would not be stored on the same medium as the main OS.
The boot-up feature can also be used for OS upgrades. An OS upgrade would be performed via the EMS unit. It would automatically push the necessary files to the EPS units. When the OS upgrade is required on an EPS unit, the mini OS is booted. The mini OS would then receive the new OS and install it on top of the old OS, completing the OS upgrade.
The main purpose of partitioning is to divide a physical server pool into smaller logical server clusters. One physical load balancer acts as multiple logical load balancers for these logical server clusters. In other words, a given physical server cluster can be partitioned into many logical server clusters. Each logical cluster can have one or more VIPs. Furthermore, each VIP can support one or more virtual domains.

Figure 3. Partitioning to Create Multiple Logical Clusters
In the example in Figure 3, six physical servers are partitioned into three logical clusters, A, B and C. Cluster A may be assigned two VIPs, and each VIP may support five virtual domains. In this way, ten virtual domains are supported in logical cluster A. Cluster B may be assigned four VIPs, and each VIP may support three virtual domains, resulting in twelve distinct domains. The cluster C may be assigned only one VIP and may support only one domain. As seen in this example, different domain requirements can be supported with this flexible partitioning. Some domains may require a dedicated server with large space requirements, while other domains may be packed with many other domains. More servers can be added into Cluster C if the customer in Cluster C requires better performance, a practice known as "Pay as you grow". For this implementation, each web server is configured with an appropriate VIP on its loopback interface, while the eth0 interface of EDS is configured with all the VIPs used in the cluster.
A Coda client, an FTP server and an LDAP server are installed on the EMS unit for content uploading. The FTP server uses the LDAP server for authentication. When a new virtual domain is added, a Coda volume will be created in the Coda server, and a web Master account for the virtual domain will be added on both the Coda and the LDAP servers. The web Master account owns the Coda volume, and the Coda volume will be mounted as the home directory of the virtual domain on all web servers in the cluster . The administrator of the virtual domain can use the web Master account to login to the FTP server on the EMS station. Once an FTP session is authenticated, the Coda client on the EMS station will be authenticated for write access to the Coda server. Since the web Master account owns the Coda volume, the FTP session can write to the home directory of the virtual domain. Without authentication by the Coda server, each Coda client only has read-only access to the virtual domain home directory.
On each EPS unit the web contents are read-only, even for the root user. Another level of security is incorporated to protect accidental modification or deletion of the web contents: the user must be authenticated for write access to the web contents stored in the Coda filesystem.
This section discusses the performance and high availability of our system.
We would like to verify 1) the scalability and 2) the high availability of our system. Systems similar to ours have been developed based on the LVS but to-date very few performance results have been reported, with the exception of "Linux on Carrier Grade Web Servers".
According to Zhang, the load balancer's overhead is minimal because its forwarding function is executed in the kernel space rather than the user space. Furthermore, by adopting the LVS direct-routing option, the load balancer cannot become a bottleneck because it does not get involved in returning the result. Based on this design, the performance should scale almost linearly as more web servers are added
One factor that may contribute to performance is the Coda filesystem. The web servers come in two flavors, Coda server and Coda client or Coda client only. When a request is forwarded to the first type, any necessary web contents are available on that server. On the other hand, if a request is forwarded to the second type and if the request page is in the cache, the request could be honored immediately. Otherwise, a page would have to be fetched from the Coda server, adding some delay. Initially, when the cache is not filled with pages that are already referenced, the Coda client would need to send many requests to the server for pages. After some processing, however, the cache-hit ratio will increase, and the delay due to the page fetch would become negligible.
eTesting Labs was hired to conduct performance testing. The results are presented in terms of requests per second and throughput. The network topology used is shown in Figure 4. At eTesting Labs, a collection of PCs with WebBench generated web page requests. When a PC made a page request, the client on the PC did not issue another request until the results of the current request were returned. Rather than displaying the results, each round-trip time was recorded. Multiple PCs were necessary because each PC could generate only so many requests per second. The product was stress-tested by increasing the number of WebBench clients from 1 through 120. In addition, the testing used two types of page requests, static page and e-commerce page. A static page request has no dynamic content, while the e-commerce page requests have CGI scripts and SSL turned on. Today it is very rare to see web sites with only static pages. However, the static-page benchmark is useful as a baseline.
Figure 4 shows that the initial test configuration consisted of one EMS unit, two EDS units and two EPS units. EPS units were added incrementally as the test progressed. For the initial configuration with two EPSes, each EPS served as both a Coda server and a Coda client. In the other test configurations (using three, four, six, and 10 EPSes, respectively) two of the EPSes served as both a Coda server and a Coda client; and the other EPSes served as only a Coda client.
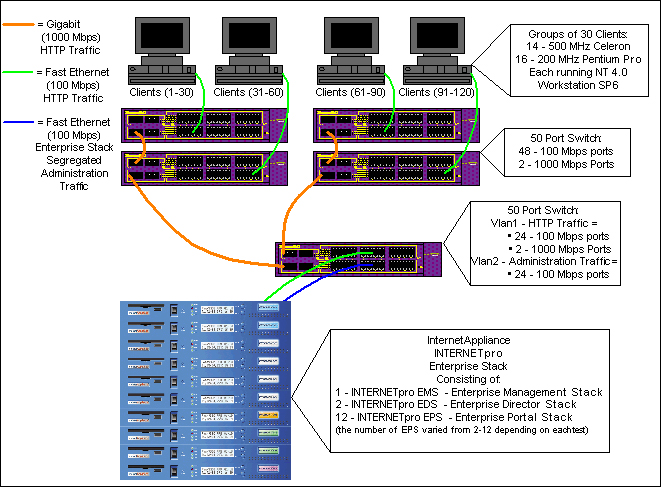
Figure 4. Test Network Topology at eTesting Lab
The results of e-commerce testing showed perfect or near linear scaling . When the number of EPS units was increased from two to three, 1.5 times more requests were processed per second. When the number of EPS units was doubled from two to four, there were 1.99 times more requests processed per second. The performance improvement was 4.65 times when there were 10 EPS units rather than two. Considering the additional overhead, these results are good. With 10 EPS units, nearly 4,600 requests per second were serviced at 18 million bytes per second. At a rate of 4,600 requests per second, more than 397 million requests could be serviced in 24 hours.
Figure 5 and Figure 6 show the e-commerce testing results in terms of requests per second and throughput, respectively.
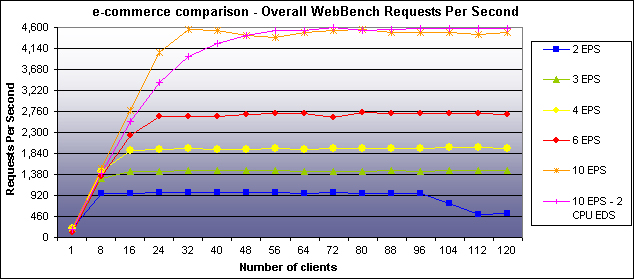
Figure 5: Request Per Second for E-commerce Testing
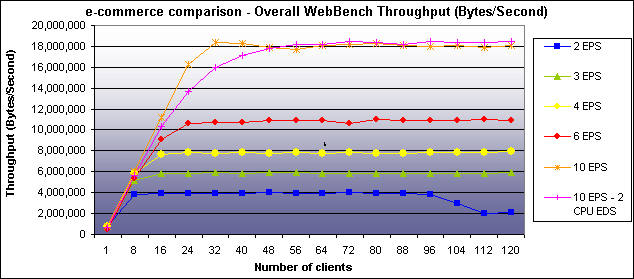
Figure 6: Throughput for E-commerce Testing
Both fail-over tests for EDS and EPS units worked as expected. First, the master load balancer was turned off. As a result, the stand-by load balancer took over and no service interruption was observed. When the master was again turned on, it resumed the load balancing function without any interruption. When one of the EPS units was turned off, it was removed from the available server pool but there was no service interruption. When that EPS unit was again turned on, it sent a signal to the EDS to put itself back in the available server pool, resulting in no visible service interruption.
With up to 10 web servers, there was no significant performance degradation. However, dedicated Coda servers would probably be required for a much higher load. Otherwise, access to the Coda would become a bottleneck.
Although we added a number of improvements over LVS, there are a few areas we would like to improve. They are:
Load balancer bottleneck
Stateful fail-over
Lost packet
Integration with backend servers
Load balancing other servers
Since the load balancer is a choke point, it could become a bottleneck for processing web requests. During performance testing, the CPU utilization rate was nearly 100% for the master EDS and the EDS unit clearly became a bottleneck. An extra CPU (to create a dual-CPU system) was added to compensate for this problem, alleviating the performance bottleneck. This solution, however, will eventually reach a higher saturation point. This is due to the LVS approach to load balancing, called Active/Passive, since only one load balancer is active at any given time, while the other one remains idle. The problem can be solved by making two or more load balancers active simultaneously, called Active/Active. This requires load balancing among load balancers. One approach is to make the router that feeds into the web farm the load balancer for the load balancer cluster. This, however, only makes sense when more than two VIPs are assigned to the server pool.
Specific web site requirements will determine the architecture of load balancers and web servers. For example, if a web farm is relatively small and a small number of requests would be expected, it may not be necessary to have a dual load-balancing system. On the other hand, if a large number of requests would be expected, multiple load balancers that are active simultaneously would be appropriate.
Some implementations of LVS generate better performance with more than 10 web servers, according to Zhang (personal communications). However, more work is needed to fine-tune the kernel on the EDS unit.
Version 1.05 of LVS for Linux kernel 2.2, the one we utilized, does not support stateful fail-over. However, in version 0.9.2 of LVS for kernel 2.4, this feature was added. The stateful fail-over has become a must-have feature in order to support e-commerce transactions, such as shopping carts. Without stateful fail-over, several problems will arise. When a switchover takes place, the information associated with each web server's state and the information concerning the received packets (on the master load balancer) is lost. When the stand-by starts to function, it does not have any prior knowledge of the state nor of the received packets on the master load balancer. Consequently, the user may have to click again to get the request processed. This is a non-critical annoyance rather than a major problem. However, the loss of each web server's state, including the number of connections, may have an impact on the load balancing. Furthermore, this has a more serious effect when a connection had been established between a client and a specific web server (like the shopping cart). The connection loss forces the client to start from scratch.
The current LVS implementation processes load balancing in the kernel. This approach is good for performance but since the information stays in the kernel, in case of a master's failure, the state information would not be available to pass on to the stand-by. In order to solve this problem, the information available in the kernel must be stored outside of the load balancer, such as in database. With this approach, additional overhead will be incurred. More research concerning the trade-off of speed vs. reliability is necessary.
When a client sends out a request packet, the load balancer receives it but does not establish the connection. The actual connection takes place on the selected web server. If the web server crashes before it establishes the connection, the request is lost. Since this happens before the connection is established, the request is not automatically re-sent by TCP/IP. The user does not obtain any reply to his/her request and simply clicks again to receive the reply. This may not be a major problem since the probability of this would be very small. But if it happens, it is still an annoyance. The direct routing option of LVS was chosen for its scalability, but each request is not monitored once it has dispatched the request to an appropriate web server. To solve this problem, the load balancer should retain the request packet information until a web server completes the processing, degrading the performance and scalability.
The current implementation is only for a stand-alone web farm. In reality, web servers would be part of the whole e-commerce infrastructure and usually would be placed as front end to the rest of the e-commerce infrastructure. More servers, such as application or database servers, would be placed behind them. Consequently, the web farm should be integrated with the backend servers. Each of our web servers has an extra interface on the interface 1 (eth1) to connect to other servers. This would require software components to support backend servers. Such components would tend to be specialized with respect to the particular backend server. A large number of such components, however, may compromise the security and the reliability of a web server. Therefore, careful consideration should be exercised.
The LVS system was not developed simply to load-balance web servers. Other servers, including application and database servers, can be accommodated. The current product ties together closely all of its components, namely EMS, EDS and EPS. Thus, it is necessary to redesign the product to accommodate other servers. This includes adjustments to the configurations, the log files and the monitoring methods. Since e- commerce infrastructure typically includes several servers, it is necessary to support the entire structure for load balancing.
We would like to acknowledge Li ZiQiang and Chen XueFeng of Internet Appliance, Inc. for their contribution to product development and performance testing. We also would like to thank Jeff Sacilotto of eTesting Labs for his contribution to the performance tests . Thanks also go out to Thian Teck Ong, Cyrus Keller, Colin Low and Kevin Foo of Internet Appliance, Inc. for their participation in the testing process. Special thanks are due to Wensong Zhang for his review and comments on the draft of this paper and the use of his figure for this paper.
Zhang, Wensong, "Linux Virtual Server for Scalable Network Services," Proc. Ottawa Linux Symposium 2000, July 2000.
Red Hat, www.redhat.com/support/wpapers/piranha
Ultra Monkey, ultramonkey.sourceforge.net
Turbo Linux, community.turbolinux.com/cluster
Coda coda.cs.cmu.edu
Jin Nan Tang is a Senior Consultant at Hewlett Packard Company, Singapore. He has fifteen years of experience in IP networking, highly available systems, systems integration, and data center implementation. He received the B.E. in Information Engineering from Northwest Telecommunications Engineering Institute, Xi'an, China.
Zen Kishimoto is President of Internet Protocol Devices, Inc. His expertise lies in IP networking and the Internet security as well as distributed object technology, software design and validation. He received the Ph.D. in Computer Science from Northwestern University, Evanston, IL.
email: zen@ipdeviecs.com
email: zen@ipdeviecs.com

