
Practical Threat Analysis and Risk Management
If you've been reading this column awhile, you know I like to balance technical procedures, tools and techniques with enough background information to give them some context. Security is a big topic, and the only way to make sense of the myriad variables, technologies and black magic that figure into it is to try to understand some of the commonalities between security puzzles.
One piece common to each and every security scenario is the threat. Without a threat there's no need for security measures. But how much time do you spend identifying and evaluating threats to your systems, compared to the time you spend implementing and (I hope) maintaining specific security measures? Probably far too little time. If so, don't feel bad, even seasoned security consultants spend too little time on threat analysis.
This is not to say you need to spend hours and hours on it. My point is that, ideally, threats to the integrity and availability of your critical systems should be analyzed systematically and comprehensively; threats to less essential but still important systems at least should be thought about in an organized and objective way.
Before we dive into threat analysis, we need to cover some important terms and concepts. First, what does threat mean? Quite simply, a threat is the combination of an asset, a vulnerability and an attacker.
An asset is anything you wish to protect. In information security scenarios, an asset is usually data, a computer system or a network of computer systems. We want to protect those assets' integrity and, in the case of data, confidentiality.
Integrity is the absence of unauthorized changes. Unauthorized changes result in that computer's or data's integrity being compromised. This can mean that bogus data was inserted into the legitimate data, or parts of the legitimate data were deleted or changed. In the case of computers, it means that configuration files have been altered by attackers in such a way as to allow unauthorized users to use the system improperly.
We also want to protect the confidentiality of at least some of our data. This is a somewhat different problem than that of integrity, since confidentiality can be compromised completely passively. If someone alters your data, it's easy to detect and analyze by comparing the compromised data with the original data. If an attacker illicitly copies (steals) it, however, detection and damage-assessment is much harder since the data actually hasn't changed.
For example, suppose ABC Corporation has an SMTP gateway that processes their incoming e-mail. This SMTP gateway represents two assets. The first asset is the server itself, whose proper functioning is important to ABC Corp.'s daily business. In other words, ABC Corp. needs to protect the integrity of its SMTP server so its e-mail service isn't interrupted.
Secondly, that SMTP gateway is host to data contained in the e-mail that passes through it. If the gateway's system integrity is compromised, then confidential e-mail could be eavesdropped and important communications tampered with. Protecting the SMTP gateway, therefore, is also important in preserving the confidentiality and integrity of ABC Corp.'s e-mail data.
Step one in any threat analysis, then, is identifying which assets need to be protected and which qualities of those assets need protecting.
Step two is identifying known and plausible vulnerabilities in that asset and in the systems that directly interact with it. Known vulnerabilities, of course, are much easier to deal with than vulnerabilities that are purely speculative. (Or so you'd think, but an alarming number of computers connected to the Internet run default, unpatched operating systems and applications.) Regardless, you need to try to identify both.
Known vulnerabilities often are eliminated easily via software patches, careful configuration or instructions provided by vendor bulletins or public forums. Those that can't be mitigated so easily must be analyzed, weighed and either protected via external means (e.g., firewalls) or accepted as a cost of doing whatever it is that the software or system needs to do.
Unknown vulnerabilities by definition must be considered in a general sense, but that makes them no less significant. The easy way to illustrate this is with an example.
Let's return to ABC Corporation. Their e-mail administrator prefers to run sendmail on the ABC Corp.'s SMTP gateway because she's a sendmail expert, and it's done the job well for them so far. But she has no illusions about sendmail's security record; she stays abreast of all security bulletins and always applies patches and updates as soon as they come out. ABC Corp. is thus well protected from known sendmail vulnerabilities.
ABC's very hip e-mail administrator doesn't stop there, however. Although she's reasonably confident she's got sendmail securely patched and configured, she knows that buffer-overflow vulnerabilities have been a problem in the past, especially since sendmail is often run as root (i.e., hijacking a process running as root is equivalent to gaining root access).
Therefore, she runs sendmail in a “chroot jail” (a subset of the full filesystem) and as user “mail” rather than as root, employing sendmail's SafeFileEnvironment and RunAsUser processing options, respectively. In this way the SMTP gateway has some level of protection not only against known vulnerabilities, but also against unknown vulnerabilities that might cause sendmail to be compromised, but hopefully not in a way that causes the entire system to be compromised, too.
The last piece of the threat puzzle we'll discuss before plunging into threat analysis is the attacker. Attackers, also sometimes called “actors”, can range from the predictable (disgruntled ex-employees, mischievous youths) to the strange-but-true (drug cartels, government agencies, industrial spies). When you consider possible attackers, almost any type is possible; the challenge is to gauge which attackers are the most likely.
A good rule of thumb in identifying probable attackers is to consider the same suspects your physical security controls are designed to keep out, minus geographical limitations. This is a useful parallel: if you install an expensive lock on the door to your computer room, nobody will ask, “Do you really think the maintenance staff will steal these machines when we go home?”
Computer security is no different. While it's often tempting to say “my data isn't interesting; nobody would want to hack me”, you have no choice but to assume that if you're vulnerable to a certain kind of attack, some attacker eventually will probe for and exploit it, regardless of whether you're imaginative enough to understand why. It's considerably less important to understand attackers than it is to identify and mitigate the vulnerabilities that can feasibly be attacked.
Once you've compiled lists of assets and vulnerabilities (and considered likely attackers), the next step is to correlate and quantify them. One simple way to quantify risk is by calculating annualized loss expectancies (ALEs).
For each vulnerability associated with each asset, you estimate first the cost of replacing or restoring that asset (its single loss expectancy) and then the vulnerability's expected annual rate of occurrence. You then multiply these to obtain the vulnerability's annualized loss expectancy.
In other words, for each vulnerability we calculate: single loss expectancy (cost) × (expected) annual rate of occurrences = annualized loss expectancy.
For example, suppose Mommenpop, Inc., a small business, wishes to calculate the ALE for denial-of-service (DOS) attacks against their SMTP gateway. Suppose further that e-mail is a critical application for their business; their ten employees use e-mail to bill clients, provide work estimates to prospective customers and facilitate other critical business communications. However, networking is not their core business, so they depend on a local consulting firm for e-mail-server support.
Past outages, averaging one day in length, have tended to reduce productivity by about one-fourth, which translates to two hours per day per employee. Their fallback mechanism is a fax machine, but since they're located in a small town, this entails long-distance telephone calls and is expensive.
All this probably sounds more complicated than it is; it's much less imposing expressed in spreadsheet form (Figure 1).

Figure 1. Itemized Single Loss Expectancy
The next thing to estimate is this type of incident's expected annual occurrence (EAO). This is expressed as a number or fraction of incidents per year. Continuing our example, suppose Mommenpop, Inc. hasn't been the target of espionage or other attacks by its competitors yet, and as far as you can tell, the most likely sources of DOS attacks on their mailserver are vandals, hoodlums, deranged people and other random strangers.
It seems reasonable to guess that such an attack is unlikely to occur more than once every two or three years; let's say two to be conservative. One incident every two years is an average of 0.5 incidents per year, for an EAO of 0.5. Let's plug this in to our ALE formula:
950 ($/incident) × 0.5 (incidents/yr) = 475 ($/yr).
The ALE for DOS attacks on Mommenpop's SMTP gateway is thus $475 per year.
Now suppose some vendors are trying to talk the company into replacing their homegrown Linux firewall with a commercial firewall; this product has a built-in SMTP proxy that will help minimize but not eliminate the SMTP gateway's exposure to DOS attacks. If that commercial product costs $5,000, even if its cost can be spread out over three years (to $2,166 per year after 10% annual interest), such a firewall upgrade would not appear to be justified by this single risk.
Figure 2 shows a more complete threat analysis for our hypothetical business' SMTP gateway, including not only the ALE we just calculated but also a number of others that address related assets, plus a variety of security goals.

Figure 2. Sample ALE-Based Threat Model
In this example analysis, customer data in the form of confidential e-mail is the most valuable asset at risk; if this is eavesdropped or tampered with, customers could be lost (due to losing confidence in Mommenpop), resulting in lost revenue. Different perceived potentials in these losses are reflected in the single loss expectancy figures for different vulnerabilities. Similarly, the different estimated annual rates of occurrence reflect the relative likelihood of each vulnerability actually being exploited.
Since the sample analysis in Figure 2 is in the form of a spreadsheet, it's easy to sort the rows arbitrarily. Figure 3 shows the same analysis sorted by vulnerability.
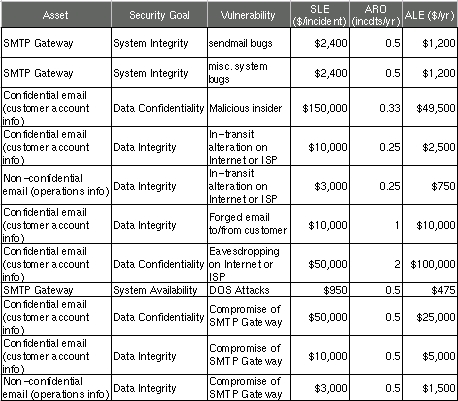
Figure 3. Same Analysis Sorted by Vulnerability
This is useful for adding up ALEs associated with the same vulnerability. For example, there are two ALEs associated with in-transit alteration of e-mail while it traverses the Internet or ISPs, at $2,500 and $750, for a combined ALE of $3,250. If a training consultant will, for $2,400, deliver three half-day seminars for the company's workers on how to use free GnuPG software to sign and encrypt documents, the trainer's fee will be justified by this vulnerability alone.
We also see some relationships between ALEs for different vulnerabilities. In Figure 3 we see that the bottom three ALEs all involve losses caused by the SMTP gateway's being compromised. In other words, not only will an SMTP gateway compromise result in lost productivity and expensive recovery time from consultants ($1,200 in either ALE, at the top of Figure 3), it will expose the business to an additional $31,500 risk of e-mail data compromises, for a total ALE of $32,700.
Clearly, the ALE for e-mail eavesdropping or tampering caused by system compromise is high. Mommenpop, Inc. would be well-advised to call that $2,400 trainer immediately.
Problems with relying on the ALE as an analytical tool include its subjectivity (note how often in the example I used words like “unlikely” and “reasonable”) and, therefore, the fact that the experience and knowledge of whoever's calculating, rather than empirical data, ultimately determine its significance. Also, this method doesn't lend itself too well to correlating ALEs with each other (except in short lists as shown in Figures 2 and 3).
The ALE method's strengths, though, are its simplicity and its flexibility. Anyone sufficiently familiar with their own system architecture and operating costs, and possessing even a general sense of current trends in IS security (e.g., from reading CERT advisories and incident reports now and then), can create lengthy lists of itemized ALEs for their environment with little effort. If such a list takes the form of a spreadsheet, ongoing tweaking of its various cost and frequency estimates is especially easy.
Even given this method's inherent subjectivity (not completely avoidable in practical threat-analysis techniques), it's extremely useful as a tool for enumerating, quantifying and weighing risks. A well-constructed list of annualized loss expectancies can help you optimally focus your IT security expenditures on the threats likeliest to affect you in ways that matter.
Bruce Schneier, author of Applied Cryptography, has proposed a different method for analyzing risk: attack trees. An attack tree, quite simply, is a visual representation of possible attacks against a given target. The attack goal (target) is called the root node; the various subgoals necessary to reach the goal are called leaf nodes.
To create an attack tree, you must first define the root node. For example, one attack objective might be “steal Mommenpop, Inc.'s customers' account data”. Direct means of achieving this could be 1) obtain backup tapes from Mommenpop's fileserver, 2) intercept e-mail between Mommenpop, Inc. and their customers and 3) compromise Mommenpop's fileserver over the Internet. These three subgoals are the leaf nodes immediately below our root node (Figure 4).

Figure 4. Root Node with Three Leaf Nodes
Next, for each leaf node you determine subgoals that will achieve that leaf node's goal, which become the next layer of leaf nodes. This step is repeated as necessary to achieve the level of detail and complexity with which you wish to examine the attack. Figure 5 shows a simple but more-or-less complete attack tree for Mommenpop, Inc.

Figure 5. More-Detailed Attack Tree
No doubt you can think of additional plausible leaf nodes at the two layers shown in Figure 5 and additional layers as well. Suppose for our example, however, that this environment is well secured against internal threats (seldom the case), and that these are the most feasible avenues of attack for an outsider.
We see in this example that backup media are obtained most probably by breaking into the office; compromising the internal fileserver involves hacking in through a firewall, and there are three different avenues to obtain the data via intercepted e-mail. We also see that while compromising Mommenpop, Inc.'s SMTP server is the best way to attack the firewall, a more direct route would simply be to read e-mail passing through the compromised gateway.
This is extremely useful information; if this company is considering sinking more money into its firewall, it may decide that their money and time are better spent securing their SMTP gateway. But as useful as it is to see the relationships between attack goals, we're not done with this tree yet.
After an attack tree has been mapped to the desired level of detail, you can start quantifying the leaf nodes. For example, you could attach a cost figure to each leaf node that represents your guess at the cost of achieving that leaf node's particular goal. By adding cost figures in each attack path, you can estimate relative costs of different attacks. Figure 6 shows our example attack tree with costs added (dotted lines indicate attack paths).
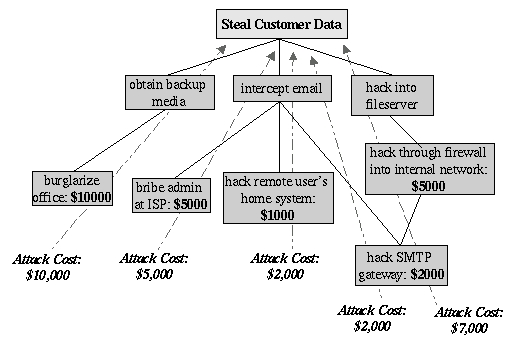
Figure 6. Attack Tree with Cost Estimates
In Figure 6 we've decided that burglary, with its risk of being caught and being sent to jail, is an expensive attack. Nobody will perform this task for you without demanding a significant sum. The same is true of bribing a system administrator at the ISP; even a corruptible ISP employee will be concerned about losing his or her job and getting a criminal record.
Hacking is a bit different, however. While still illegal, it's often perceived as being less risky than burglary. Furthermore, most organizations' computer defenses aren't nearly as difficult to breach as their physical defenses.
Having said that, hacking through a firewall takes more skill than the average script-kiddie possesses and will take some time and effort; therefore, this is an expensive goal. But hacking an SMTP gateway should be easier, and if one or more remote users can be identified, the chances are good that the user's home computer will be easy to compromise. Therefore, these two goals are much cheaper.
Based on the cost of hiring the right kind of criminals to perform these attacks, the most promising attacks in this example are hacking the SMTP gateway and hacking remote users. Mommenpop Inc., it seems, had better take a close look at their perimeter network architecture, SMTP server's system security and remote-access policies and practices.
Cost, by the way, is not the only type of value you can attach to leaf nodes. Boolean values such as feasible and not feasible can be used; a “not feasible” at any point on an attack path indicates that that entire path is infeasible. Alternatively, you can assign effort indices, measured in minutes or hours. In short, you can analyze the same attack tree in any number of ways, creating as detailed a picture of your vulnerabilities as you need to.
The cost estimates in Figure 6 are all based on the assumption that the attacker will need to hire others to carry out the various tasks. These costs might be computed very differently if the attackers themselves are skilled system crackers; in such a case time estimates for each node might be more useful than cost estimates.
The whole point of threat analysis is to try to determine what level of defenses are called for against the various things to which your systems seem vulnerable.
There are three general means of mitigating risk. Defenses can be categorized as means of reducing an asset's value to attackers mitigating specific vulnerabilities and neutralizing or preventing attacks.
Reducing an asset's value may seem like an unlikely goal, but the key is to reduce that asset's value to attackers, not to its rightful owners/users. The best example of this is encryption: all of the attacks described in the examples earlier in this article would be made irrelevant largely by proper use of e-mail encryption software.
If stolen e-mail is effectively encrypted, it can't be read easily by thieves. If it's digitally signed (also a function of e-mail encryption software), it can't be tampered with without the recipient's knowledge, regardless of whether it's encrypted too. A physical world example is dye-bombs: a bank robber who opens a bag of money only to see himself and his loot sprayed with permanent dye will have some difficulty spending that money. Asset-devaluation techniques like these don't stop attacks, but they have the potential to make them unrewarding and pointless.
Another strategy to defend information assets is to eliminate or mitigate vulnerabilities. Software patches are a good example of this: every single sendmail bug over the years has resulted in its developers distributing a patch that addresses that particular bug.
An even better example of mitigating software vulnerabilities is defensive coding. By running your source code through filters that parse, for say, improper bounds checking, you can help insure that your software isn't vulnerable to buffer-overflow attacks. This is far more useful than releasing the code without such checking and simply waiting for the bug reports to trickle back to you.
The defensive approach we tend to focus on the most (not that we should) is heading off attackers before they reach vulnerable systems. The most obvious example is firewalling; firewalls exist to stymie attackers. No firewall yet designed has any intelligence about specific vulnerabilities of the hosts it protects or of the value of data on those hosts. A firewall's function is to mediate all connections between trusted and untrusted hosts and minimize the number of attacks that succeed in reaching their intended targets.
Access control mechanisms such as username/password schemes, authentication tokens and smart cards also fall into this category since their purpose is to distinguish between trusted users and untrusted users (i.e., potential attackers). Note, however, that authentication mechanisms also can be used to mitigate specific vulnerabilities (e.g., using SecurID tokens to add a layer of authentication to a web application with inadequate access controls).
And with that, I bid you adieu for the next couple of months. Due to the demands of a book on Linux security I'm writing for O'Reilly & Associates, the Paranoid Penguin temporarily will be covered by others. Have no fear; they'll maintain the high level of paranoia and vigilance you've come to expect here. See you again in the April 2001 issue.
Mick Bauer (mick@visi.com) is a network security consultant in the Twin Cities area. He's been a Linux devotee since 1995 and an OpenBSD zealot since 1997, and enjoys getting these cutting-edge OSes to run on obsolete junk.
