
Building an Inexpensive, Powerful Parallel Machine and Using It for Numerical Simulations
During my postdoctoral training at SUNY Health Science Center at Syracuse two years ago, I had some exposure to a commercial 30-processor SUN Enterprise E6500 machine. The price of that machine, together with its support package and software licenses, ran up around half a million dollars. This cost is why during the negotiation of my new faculty startup funds at Montclair State University, when I was offered a maximum of $25,000 for "something parallel", I was skeptical at first. However, in the spring of 2001, after doing my homework, I embarked on a project of building my own Beowulf-type cluster of Pentium-based computers.
Choosing Linux as the operating system for the cluster was obvious. Even though I had only about one year of experience with Linux, I already considered myself a Linux fan and a big supporter of open-source software. I spent much more time, therefore, choosing the right hardware that would optimize the projected performance under the constrained cost. After the choice was made, the boxes began to arrive.
In July 2001, about three months after the project began, I had a cluster, which I named GALAXY, up and running. It has since exceeded my best amateur expectations of its performance and reliability, and it has become an indispensable tool in my research of spiral waves in excitable media.

Classic Beowulf-type clusters used to be built with PCs. However, because of falling prices of rackmountable, Intel-based servers, I realized that with a small sacrifice in the price-performance ratio I could assemble my cluster in a standard cabinet enclosure (on wheels). This would make it much more manageable, compact and portable, compared to the LOBOS model (lots of boxes on shelves). I purchased ten dual 1GHz Pentium III rackmountable servers at about $2,000 per server, for a total of about $20,000, from Microway, Inc. (www.microway.com).
Gigabit Ethernet over copper (1000BaseT), which uses category 5e conventional Ethernet cables, was chosen as the internode communication standard. Thus, each node included a 3COM Gigabit PCI network card, or one card per two CPUs. Each of the ten cards was connected to a 12-port 3COM Gigabit switch (SuperStack-3 4900), which cost about $3,000.
The rest of the money (about $2,000) was spent on a standard 19" 40U rackmount cabinet with a shelf (APC Netshelter), a UPS for power backup of the master node, power outlets, Ethernet kit and cable and KVM extension cables. All the cluster components, except for the servers, were ordered through MicroWarehouse (www.microwarehouse.com).
One special node out of ten, called the master node, has two 20GB hard drives, a CD-RW drive and 512MB of ECC SDRAM. This is the only node that has a keyboard, video and mouse connected. Its rackmount size is 2U. In addition to the Gigabit connection with the switch, this node is also connected by Fast Ethernet to the outside network. Each of the nine slave nodes has a single 10GB hard drive, 256MB of memory and is 1U in size. Every node has a floppy drive. The cabinet's front and back doors are perforated for air circulation. The only fans are the ones inside the server boxes and inside the switch.

Figures 1 and 2 show the front and rear views of GALAXY, whose assembly was carried out by a single person. Its total peak performance is represented by the formula 1GHz/CPU x 20 CPUs, which, assuming one floating-point operation per one-clock tick, is equal to 20 Gigaflops, or 20 billion floating-point operations per second.
With an optional 4-port module (about $1,000), the total number of Gigabit ports in the switch, and thus the maximum number of nodes, can easily be increased to 16, all of which corresponds to 32 processors and 32 Gigaflops peak performance. The cabinet space can accommodate twice that number of nodes, which can be hooked up using multiple cascading switches, but the room's electrical capabilities and heat dissipation will become an issue at that point.
Although the term "cluster" is traditionally appropriate for a system like GALAXY, it is not a cluster of PCs because each server is not exactly a PC. In fact, this cluster is structurally not very different from the 30-CPU SUN Enterprise server mentioned above, which nobody calls a cluster. This is why I used the term "parallel machine" instead of cluster in the title of this article.
There is a choice of parallel software for clusters, some installed on top of Linux, others integrated into Linux and running out-of-the-box. An example of the latter is the Scyld Beowulf Cluster Operating System (www.scyld.com), which can be viewed as a numerous set of patches to Red Hat Linux 6.2, and which I happened to adopt for GALAXY. I purchased a Scyld Beowulf CD (with version 27bz-7) from Linux Central (www.linuxcentral.com) for about $5. This software is open-source, and the source code is available at ftp.scyld.com.
The biggest advantage of the Scyld Beowulf Cluster OS for me is its beoboot utility. The Scyld Beowulf OS is installed on the master node pretty much the same way Red Hat Linux is installed. After the installation, a beoboot floppy is created. Adding the first slave node and any subsequent nodes to the cluster is as easy as booting that floppy and waiting. A node, which might have no OS on it at all, becomes a part of the cluster in about one minute. It first boots an initial kernel from the beoboot floppy, which tells it to get in touch with the master node and download and execute the full-size kernel from it. Thus, system administration only needs to be done on the master node. The slave nodes get the updated OS from the master node every time they boot.
Jobs on any node are started from the master node, which is the only login place in the entire cluster. Scyld Beowulf software creates an illusion of a single computer (master node) with many CPUs (those of slave nodes). Monitoring slave nodes from the master node is easy with a graphical beostatus utility (see Figure 3) or simply with top.
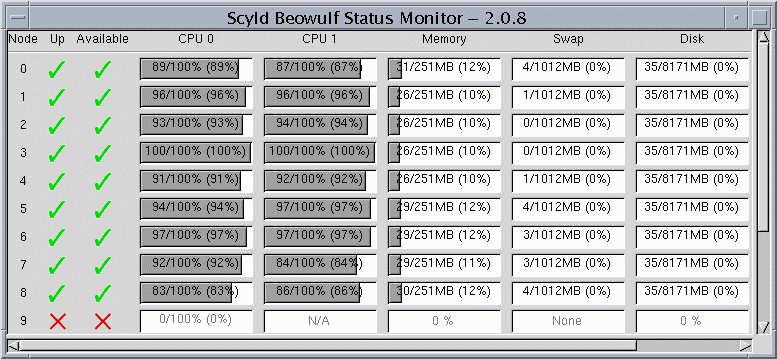
Figure 3. Node Monitoring with the beostatus Utility
Newer incompatible network card drivers, the ATAPI CD-RW drive and the fact that all my nodes are actually SMPs (symmetric multiprocessors) did cause some problems with Scyld Beowulf OS, which didn't work smoothly out-of-the-box the way it should. To fix all those problems I had to recompile both the main and the beoboot kernels. The Linux kernel recompilation, which scared me at the beginning, is actually a streamlined process, well-documented in the Linux HOWTOs. After a while, I had a custom kernel that included only the features I wanted (SMP support, i686 optimizations, SCSI emulation mode for the ATAPI CD-RW drive, etc.). I soon realized that the Linux kernel I obtained, as well as the entire system, was rock-solid and the cluster was functioning exactly as it should.
Message passing is the established programming paradigm for distributed memory parallel machines, of which GALAXY is an example. MPI (message passing interface) is an accepted open standard for message passing between processors, and there are many concrete implementations of the MPI standard for different platforms. One of them is MPICH, a customized version of which is integrated into Scyld Beowulf software. From the programmer's point of view, an MPI implementation is a set of Fortran, C and C++ libraries. These libraries provide routines, of which the four most important being: Get_size(), Get_rank(), MPI_Send(...) and MPI_Recv(...).
An MPI program is usually started on all P available processors. Each concurrently running instance of that program can query the parallel machine for the total number of CPUs using Get_size() and for the local CPU number using Get_rank(). With MPI_Send() and MPI_Recv(), a pair of CPUs can send data between each other.
Having properly installed the Scyld Beowulf Cluster OS software, one can start writing parallel programs. I have been writing my code in C++, compile it with g++ and link it with libmpi++. The parallel Linux-based operating system I built, which is 100% open-source and has a total cost of under $10, exhibits an amazing stability. My parallel programs run on GALAXY's 20 processors for hours and days without a glitch. On the standard Linpack benchmark, which is also included with Scyld Beowulf OS, GALAXY demonstrated a sustained performance of 7 Gigaflops.
I have used GALAXY extensively for numerical modeling of excitable media. Under certain conditions, excitation waves propagating in such media break into persistent spiral patterns. One major example of an excitable medium is cardiac muscular tissue. Cardiac arrhythmias, the leading cause of deaths in industrialized countries, are believed to be triggered by the appearance of spiral waves in cardiac electrical activity. The area of my current investigation is the asymptotic behavior of a large number of interacting spirals; that is, the long-term development in a 2-D excitable system with a large number of initially generated random spirals.
To answer this question I had to solve numerically a system of the underlying nonlinear PDEs on a very large domain (to accommodate a large number of spirals) and for a very large number of time steps. GALAXY helped me reduce the simulation time from days to hours. Very often, in order to achieve such results, researchers would reduce the numerical solution of a system to performing linear algebra operations on large matrices, which can be parallelized using the existing libraries (such as LAPACK, www.netlib.org/lapack). However, this approach is very specific for each individual type of problem and usually involves rather complicated math. The approach I used is by far more straightforward and uniform, and it can be used by anyone who deals with any PDE system on a rectangle, providing it has already been solved numerically (using some difference scheme) for a single CPU.
The method consists of splitting the rectangular domain into P equally-sized stripes (see Figure 4) and assigning each stripe to one of the P available processors. Each iteration of the main loop consists of two major steps. First, each processor updates the data on the grid-points of its corresponding stripe. Then, using simple MPI_Send() and MPI_Recv() calls, all pairwise neighboring processors exchange the data along the shared boundary of the corresponding stripes.

Figure 4. Dividing the Domain among Multiple CPUs
This simple parallelization technique, applied to my sequential spiral interaction code, led to a 12-fold speed-up on the 18 slave CPUs (with 18 stripes). The two CPUs of the master node were used for a periodic data collection and file output (one pthread) and for displaying results using Mesa 3-D graphics (second pthread). The numerical simulations revealed a new and unexpected effect: the interacting spirals tend to form stable triplets (see Figure 5). Clearly, the above algorithm can be extended to a 3-D case, which is one of my future directions.

Figure 5. One Simulation Result for Spiral Wave Interaction
It is worth noting one more naturally parallelizable situation that does not require processor communication (message passing) at all. Researchers often run one program many times with different input, for example, to find out which parameters lead a simulated system to some special behavior. One can start such a program on P available processors with P different parameter values, and the running time will be P times less than with P consecutive runs on a single CPU.
GALAXY is a performant message-passing, multiprocessor system, which can be compared to some commercial parallel machines, although it carries only a small fraction of their cost. My example has demonstrated that such a machine can be built, maintained and successfully used by a single person. With a simple message-passing algorithm, like the one described above, GALAXY can speed up a generic PDE solver on a rectangular domain by at least ten times compared to a single workstation. With such a speed up, some programs, previously run as batch jobs, can be converted into real-time, interactive, graphical simulations.
Writing an MPI program can be a tedious task. Is the time spent really justified? Because of physical limitations, the clock rate of a single CPU can't grow indefinitely. Most researchers agree that Moore's law, which states that the CPU speed doubles every 18 months, will probably not hold beyond 10-15 years from now. Utilization of parallelism will become the primary way to increase performance. A well-written MPI program receives the total processor number dynamically at runtime and, therefore, such a program should seamlessly scale to a growing number of CPUs, whenever such systems will become available.
A combination of two factors makes systems like GALAXY possible: inexpensive commodity hardware components of tremendous performance (processors, memory, switches, etc.) and the existence of Linux and numerous other open-source software products such as GNU compilers, GNOME desktop, MPICH MPI implementation and Scyld cluster software. There is an emerging middle ground between the industrial multiprocessor computers running proprietary software and self-made systems like GALAXY.
Spiral Waves in Excitable Media: "On the Interaction of Vortices in Two-Dimensional Active Media", E.A. Ermakova, A.M. Pertsov and E.E. Shnol. Physica D 40 (1989) 185-195. North-Holland, Amsterdam.
I'd like to thank my Department Chair, Dr. Dorothy Deremer, and the former College Dean, Dr. Kenneth C. Wolff, for the project funding and support.
Dr. Roman Zaritski is a professor at the Department of Computer Science of the Montclair State University in New Jersey. His primary interest is numerical modeling of biological systems.
email: zaritski@roman.montclair.edu
