
Alphabet Soup: The Internationalization of Linux, Part 1
What is Linux? Since you are reading this in the Linux Journal, you probably already know. Still, it is worth emphasizing that Linux is an open-source software implementation of UNIX. It is created by a process of distributed development, and a primary application is interaction via networks with other, independently implemented and administered systems. In this environment, conformance to public standards is crucial. Unfortunately, internationalization is a field of information processing in which current standards and available methods are hardly satisfactory. The temptation to forfeit conformance with (international) standards in favor of accurate and efficient implementation of local standards and customs is often high.
What is internationalization? It is not simply a matter of the number of countries where Linux is installed, although that is certainly indicative of Linux's flexibility. Until recently, although their native languages varied widely, the bulk of Linux users have been fluent in certain common not-so-natural languages, such as C, sh and Perl. Their primary purpose in using Linux has been as an inexpensive, flexible and reliable platform for software development and provision of network services. Of course, most also used Linux for text processing and document dissemination in their native languages, but this was a relatively minor purpose. Strong computer skills and hacker orientation made working around the various problems acceptable.
Today, many new users are coming to Linux seeking a reliable, flexible platform for activities such as desktop publishing and content provision on the World Wide Web. Even hackers get tired of working around software deficiencies, so now a strong demand exists for software to make text processing in languages other than English simple and reliable, and permitting text to be formatted according to each user's native language and customs.
This process of adapting a system to a new culture is called localization (abbreviated L10N). Obviously, this requires provision of character encodings, display fonts and input methods for the input and display of the user's native language, but it also involves more subtle adjustments to facilities such as the default time system (12 hour or 24 hour) and calendar (are numerical dates given MM/DD/YY as in the U.S., or YY/MM/DD as in the international standard, or DD/MM/YY?), currency representation and dictionary sorting order. APIs for automatic handling of these issues have been standardized by POSIX, but many other issues, such as line-wrapping and hyphenation conventions, remain. Thus, localization is more than just providing an appropriate script for display of the language and, in fact, more than just supporting a language. American and British people both use the same language as far as computers can tell, but their currency symbols are different.
Localization is facilitated by true internationalization, but can also be accomplished by patching or porting any system ad hoc. To see the difference, consider that a Chinese person who wishes to deal with Japanese in the Microsoft Windows environment has two choices: dual booting a Japanized Windows and a Sinified Windows, or using the rather unsatisfactory and generally unsupported by applications Unicode environment. This is a localization; it is non-trivial to port applications from Japanized Windows to Sinified Windows, as the same binaries cannot be used. In an internationalized setup, one would simply need to change fonts, input methods and translate the messages; these would be implemented as loadable modules (or separate processes). With respect to applications, the situation in Linux is, at best, somewhat better (especially from the standpoint of Asian users). However, the future looks very promising, because many groups are actively promoting internationalization and developing internationalized systems for the GNU/Linux environment.
Internationalization (abbreviated I18N) is the process of adapting a system's data structures and algorithms so that localizing the system to a new culture is a matter of translating a database and does not require patching the source. Of course, we would prefer the binaries to be equally flexible, but for reasons of efficiency or backward compatibility, localized versions may implement different data structures and algorithms. Although internationalization is more difficult than localization, once it is complete, the process of localizing the internationalized software to a new environment becomes routine. Furthermore, localization by its nature is not a strong candidate for standardization, because each new system to be localized to a particular environment brings its own new problems. Internationalization, on the other hand, is by definition a standard independent of the different cultural environments. An obvious extension is to jointly standardize those facilities common to many systems.
Internationalization can be contrasted with multilingualization. Multilingualization (abbreviated M17N) is the process of adapting a system to the simultaneous use of several languages. Obviously more difficult than localization or even internationalization, multilingualization requires that the system not only deal with different languages, but also maintain different contexts for specific parts of the current data set.
Note that the operating system can be localized, internationalized or multilingualized while some or all applications are not, and vice versa. In a certain sense, Linux is a multilingual operating system; the kernel presents few hindrances to use of different languages. However, most utilities and applications are limited to English by availability of fonts and input methods, as well as their own internal structures and message databases. Even the kernel panics in English. On the other hand, GNU Emacs 20, both the FSF version and the XEmacs variant, incorporate the Mule (MUlti-Lingual Extensions Emacs) facilities (see “Polyglot Emacs” in this issue). With the availability of fonts and, where necessary, internationalized terminal emulators, Emacs can simultaneously handle most of the world's languages. Many GNU utilities use the GNU gettext function (see “Internationalizing Messages in Linux Programs” in this issue), which supports a different catalog of program messages for each language.
The foundation is the operating system kernel. The main condition imposed on the functionality of the kernel is that it must treat natural language text data as binary data. Data passed between processes should not be altered gratuitously in any way. For many kernel functions (e.g., scheduling and memory management), this is already a requirement to which most systems conform.
Historically, computer text communications used 7-bit bytes and the ASCII character set and encoding. Often, communications software would use the high bit as a “parity bit”, which facilitates error detection and correction. Some terminal drivers would use it as a “bucky-bit” or to indicate face changes, such as underlining or reverse video. Although none of these usages are bad per se, they should be restricted to well-defined and well-documented interfaces, with 8-bit-clean alternatives provided.
Unfortunately, the seven-significant-bits assumption leaked into a lot of software, in particular implementations of electronic mail, and now has been enshrined in Internet standards such as RFC-821 for the Simple Mail Transport Protocol (SMTP) and RFC-822 which describes the format of Internet message headers for text messages. Software that transparently passes all data and does not perform unrequested transformations is called “8-bit clean”. Note that endianness is now an issue in text processing, since character sets such as Chinese, Japanese, Korean and the Unicode character set use at least two-byte integers to represent some or all characters. Hencefoward, any mention of 8-bit cleanness should be taken to imply correct handling of endianness issues as well.
One might also want kernel log and error messages to be localized. Although error messages are rather stylized and easy to learn, they are also easy to translate. The main objection to doing this is efficiency. Compiling all known languages into the kernel would make it huge; localizing the kernel would mean maintaining separate builds for each language. A more subtle problem is the temptation to avoid new features that would require translating more messages, or to do a hasty, inaccurate translation. Finally, separate message catalogs would require loading at some point, introducing more possibilities for bugs. Even worse, a system crash before loading the catalog would mean no error messages at all.
The next layer is file systems which are normally considered part of the kernel. In cases like Linux's /proc file system, they are inseparable from the kernel. File systems are a special case because the objects they contain inherently need to be presented to users and input by them. Hence, it is not enough for the programs implementing file systems to be 8-bit clean, since the directory separator, /, has special meaning to the operating system. This means that trying to use Japanese file names encoded according to the JIS-X-0208 standard may not work because some of those two-byte characters contain the ASCII value 0x2F as a second byte. If the file system treats path names as simply a string of bytes, such characters will be corrupted when passed to the file system interface in function arguments.
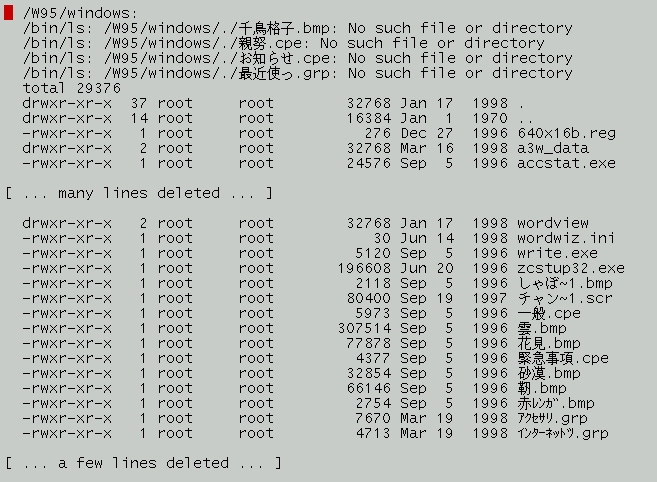
One can imagine various solutions to the problem such as redesigning file system calls to be aware of various encodings, using a universal encoding such as Unicode, or removing dependence of the operating system on such special characters by defining a path data type as a list of strings. However, these solutions would preclude backward compatibility and compatibility with alien file systems and would be something of a burden to programmers. Fortunately, a fairly satisfactory solution is to use a transformed encoding that sets the eighth bit on non-ASCII characters. The major Asian languages have such encodings (EUC), as does Unicode (UTF-FSS, officially UTF-8). By definition the ISO-8859 family of encodings, all of which contain U.S. ASCII as a subset, satisfy this constraint without need for transformation. Using a transformation format is rarely a burden on users, as they generally need not be aware of which encoding format their language is using. However, this difficulty can still apply to mounting alien file systems, especially MS-DOS and VFAT file systems, where Microsoft has implemented idiosyncratic encodings such as Shift-JIS for their localized extensions of DOS and MS Windows. A partial directory listing of a Japanized Windows 95 file system mounted as an MS-DOS file system on my Linux system is shown in Figure 1, a Dired buffer in Mule. Note the error messages at the top of the buffer. ls is unable to find a file name it just received from the file system. When the directory listing is made, one pass generates a list of file names, which includes Shift-JIS-encoded Japanese names. When the list is passed back to the file system to get the file properties, some of the octets of Japanese characters are interpreted as file system separators. Thus, the Japanese character is not found and the error message results. The VFAT file system does not exhibit this problem in this case; I am not sure why. Most characters are passed unscathed, as you can see.
Figure 1. Japanized Windows 95 File System on Linux
This principle applies generally to other system processes (init, network daemons, loggers and so on). As long as the programs implementing them are 8-bit clean, use of non-ASCII characters in comments and strings in configuration files and the like should be fairly transparent, as long as file-system-safe transformation formats of standard encodings are used. This is true because keywords and syntactically significant characters have historically been drawn from the U.S. ASCII character set and, in particular, U.S. English. This is unlikely to change because the historic dominance of the U.S. in computer systems manufacturing and distribution means that most programming and scripting languages are English-based and use the ASCII character set. An interesting exception is APL; because of its IBM heritage, it is based on EBCDIC, which contains many symbols not present in ASCII.
The major standards for programming languages, operating systems (POSIX), user interfaces (X) and inter-system communication (RFC 1123, MIME and ISO 2022) specify portable character sets which are subsets of ASCII. Protocol keywords are defined to be strings from the portable character set, and where a default initial encoding is specified, it is U.S. ASCII or its superset, ISO-8859-1. Note that in most cases a character set is specified, for example, in C and X. IBM mainframes must support a portable character set which is a subset of ASCII, but those characters will be encoded in EBCDIC.
The only exception is ISO 2022 which specifies neither a portable nor ASCII character set as default; however, even there the influence of ASCII is extremely strong. The 256 possible bytes are divided into “left” (eighth bit zero) and “right” (eighth bit one) halves of 128 code points each and within each half, the first 32 code points (0x00 to 0x1F) are reserved for control characters while the remaining 96 may be printable characters. Further, positions 0x20 and 0x7F have reserved interpretations as the space and delete characters respectively and may not be used for graphic characters, while 0xA0 and 0xFF are often left unused.
The next layer is user interfaces, such as the Linux console and X. Here, the strong preference is for a primitive form of multilingualization, allowing arbitrary fonts to be displayed and text to be input in arbitrary encodings via configurable mappings of the keyboard. Both the Linux console and X provide these features, although the Linux console does not directly support languages with characters that cannot be encoded in one byte. They need not have more sophisticated mechanisms, because users rarely deal directly with them; application developers will build user-friendly interfaces on top of these toolkits. On the other hand, they should be as general as possible, so that the localizations can be as flexible as possible.
The next layer is applications, including system utilities. Here, things become much more complicated. Not only is it desirable that they issue messages and accept input in the user's native language, but must also handle non-trivial text manipulations like sorting. Of course, their entire purpose may be text manipulation, e.g., the text editor Emacs or the text formatter TeX.
One example of this complexity is that even where languages have characters in common, the sorting order is typically different. For example, Spanish and English share most of the Roman alphabet and both can be encoded in the ISO-8859-1 encoding. However, in English the names Canada, China and Czech Republic sort in that order, but in Spanish they sort as Canada, Czech Republic and China, because Spanish treats “ch” as a single entity, sorting after “c” but before “d”. Although Chinese, Japanese, Korean and to some extent Vietnamese share the ideographic characters that originated in China, they have very different ideas about how those characters are sorted.
The outermost layer, beside the user-to-system interface, is inter-system communication. This layer has all the problems already mentioned, plus one more. Within a single system, specifying how to handle each language can be done implicitly; when a language is recognized, the appropriate version of some subsystem handles it. However, when communicating with another system, a mechanism for specifying formats must be present. Here, the MIME (Multipurpose Internet Multimedia Extensions) formats are crucial. Where possible, a means to negotiate the appropriate format for the communication should be provided as in HTTP, the hypertext transport protocol which is the foundation of the World Wide Web.
Localizing an application means enabling it to display, receive input and modify text in the preferred language of the user. Since this is usually the user's native language, we will also write native language support (NLS) for localization.
The most basic capability is text display. Merely discussing text display requires three concepts: character set, encoding and font. A language's character set is those characters used to form words, phrases and sentences. A character is a semantic unit of the language and the concept of “character” is quite abstract. Computers cannot deal directly with characters; they must be encoded as bit strings. These bit strings are usually 8 bits wide; strings of 8 bits are called octets in the standards. “Byte” is not used because it is a machine-oriented concept; octets may refer to objects transmitted over a serial line, and there is no need for the hosts at either end to have facilities for handling 8-bit bytes directly. Most Linux users are familiar with the hexadecimal numbering system and the ASCII table, so I will use a two-hex-digit representation of octets. For example, the “Latin capital letter A” will be encoded as 0x41.
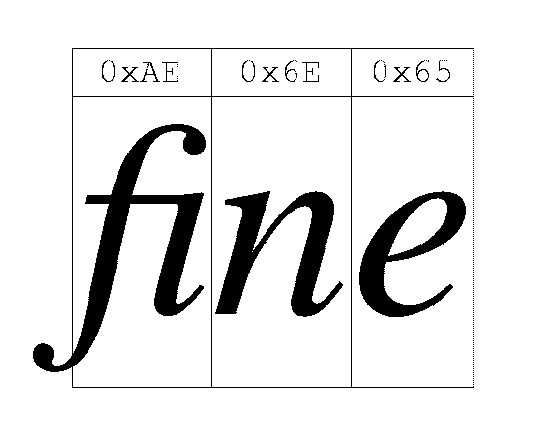
Human readers do not normally have serial interfaces for electronic input of bit strings; instead, they prefer to read a visual representation. A font is an indexed set (not necessarily an array, because there may be gaps in sequences of the legal indices) of glyphs (character shapes or images) which can be displayed on a printed page or video monitor. The glyphs in a font need not be in a one-to-one correspondence with characters and do not necessarily have semantic meaning in the native language. For example, consider the word “fine”. As represented in memory, it will consist of the string of bytes “Ox66 Ox69 Ox6E Ox65”. Represented as a C array of characters, it would be “fine”, but as displayed after formatting by TeX in the PostScript Times-Roman font, it would consist of three glyphs, “fi”, “n” and “e” as shown in Figure 2.
Figure 2. Times-Roman Font Display of Word fine
Conversely, in some representations of the Spanish small letter enye (ñ), the base character and the tilde are encoded separately. This is unnecessary for Spanish if ISO-8859-1 or Unicode is used, but the facility is provided in Unicode. It is frequently useful in mathematics, where arbitrary meanings may be assigned to typographical accents. An example of a font which does not have semantic meaning in any human's native language is the standard X cursor font (see Figure 3).
An encoding is a mapping from each abstract character or glyph to one or more octets. For the common encodings of character sets and fonts for Western languages, only one octet is used. However, Asian languages have repertoires of thousands of ideographic characters; normally, two octets are used per character and two per glyph. Two formats are used for such large encodings. The first is the wide character format, in which each character is represented by the same number of octets. Examples are the pure Japanese JIS encoding and Unicode, which use two octets per character, and the ISO-10646 UCS-4 encoding (a planned superset of Unicode) which uses four octets per character. This encoding is the index mapping for a character set or font.
Another format is the multibyte character in which different characters may be represented by different numbers of octets. One example is the packed Extended UNIX Code for Japanese (8-bit EUC-JP), in which ASCII characters are represented in one octet which does not have the eighth bit set, and Japanese characters are represented by two octets. These octets are the same as in the plain JIS encoding, except that the eighth bits are set (in pseudo-C code, euc = jis | 0x8080). By using this encoding, any 8-bit-clean compiler designed for ASCII can be used to compile programs which use Japanese in comments and strings. This option would not be available for wide-character formats. If programs were written in pure JIS, the compiler would have to be rewritten to accept JIS ASCII characters. The ASCII character set is a subset of the JIS character set, but instead of being assigned the range 0x00 to 0x7F, the letters and digits are assigned values given by the ASCII value + 0x2300, and punctuation is scattered with no such simple translation. Another common place to encounter multibyte characters is in transformation formats, specifically the file-system-safe transformation of Unicode, UTF-8. Like EUC-JP, UTF-8 encodes the ASCII characters as single bytes in their standard positions.
Multibyte formats do not interfere with handling of text where the program does not care about the content (operations such as concatenation, file I/O and character-by-character display), but will work poorly or inefficiently where the content is important and addressing a specific character position is necessary (operations such as string comparison, the basis of sorting and searching). They may be especially useful for backward compatibility with systems designed for and implemented under the constraints of ASCII, e.g., compilers. They may be more space-efficient if the single-octet characters are relatively frequent in the text.
Wide-character formats are best where addressing specific character positions is important. They cannot be backward compatible with systems designed for single-octet encodings, although with appropriate choice of encoding, e.g., Unicode, little effort beyond recompiling with the type of characters extended to the size of wide characters may be necessary. Unfortunately, existing standards for languages like C do not specify the size of a wide character, only that it is at least one byte. However, the most recently designed languages often specify Unicode as the internal encoding of characters, and most system libraries specify a wide-character type of two bytes, which is equivalent to two octets.
Text input is in some senses the inverse of text display. But, because computers are much better at displaying graphics than reading them, it presents problems of its own.
Probably the easiest method of text input would be voice. However, voice-input technology is still in its infancy, and there are times when a direct textual representation is preferable, such as for mathematics and computer programming. A highly adaptive system could be created, but typed keyboard input will be faster and more accurate for some time. Similarly, although optical character recognition (OCR) and handwriting recognition are improving rapidly, keyboard input will also remain more efficient for large bodies of text. The difference between OCR and handwriting recognition is that OCR treats static two-dimensional data, whereas handwriting recognition has the advantage of dynamics; this is particularly important in recognizing handwritten ideographic characters in Oriental languages. However, both of these would be quite close to an exact inverse of text display; the system would map from the physical inputs to the internal encoding directly, without user intervention. The fact that voice and optical technologies are not available for Linux systems makes the point moot for the moment.
For practical purposes, most Linux systems are limited to keyboard input. Several problems are related to internationalizing keyboard input. The first is that most computer keyboards are well-designed for at most one language. U.S. computer keyboards are not well-adapted to produce characters in languages that use accents. But the obvious solution, which is to add keys for the accented characters, is inefficient for those languages which have many accented characters (Scandinavian) or context-dependent forms (Arabic). It is impossible for languages which use ideographic character sets such as Chinese Hanzi or complex syllabaries like Korean Hangul. What is to be done for languages such as Greek and Russian with their own alphabetic scripts that can conveniently be mapped on a keyboard, but which cannot be used for programming computers?
The solution is the creation of input methods which translate keystrokes into encoded text. For example, in GNU Emacs with Mule, the character “Latin small letter u with umlaut” can be input on U.S. keyboards via the keystrokes "u. However, this presents the problem that the text upper cannot be directly input one keystroke per character. Furthermore, umlauts are not appropriate accents for consonants; even for vowels, languages vary as to which vowels may be accented with umlauts. So this usage of the keystroke " must be context dependent within the input stream and must be conditioned by the language environment.
In the case of ideographic Oriental languages, the process is even more complex. Of course, it is possible to simply memorize the encoding and directly input code points, e.g., in hexadecimal. It is more efficient for ISO-2022-compatible encodings to memorize the two-octet representation as a pair of ASCII characters. Although this method of input is very efficient, it takes intense effort and a lot of time to memorize a useful set of characters. Educated Japanese adults know about 10,000; Unicode has 20,902. Furthermore, if you need a rare character that you have not memorized, the dictionary lookup is very expensive, since it must be done by hand. For these languages, the most popular methods involve inputting a phonetic transcription which the input method then looks up in an internal dictionary. The function which accepts keystrokes, produces the encoded phonetic transcription and queries the dictionary is often called a front-end processor, while the dictionary lookup is often implemented as a separate server process called the back end, dictionary server or translation server.
Dictionary servers often define a complex protocol for refining searches. In Japanese, some ideographic characters have dozens of pronunciations and some syllables correspond to over 100 different characters. The input method must weed out candidates using context, in terms of characters that are juxtaposed in dictionary words and by using syntactic clues. Even so, it is not uncommon that rather sophisticated input methods will produce dozens of candidates for a given string of syllables. Japanese has many homonyms, often with syntactically identical usage; occasionally, even with the help of context, the reader must trust that the author has selected the right characters. An amusing example occurred recently in a church bulletin, where the Japanese word “megumi”, meaning “(God's) grace”, was transcribed into a pair of characters that could easily be interpreted as a suffix meaning “gang of rascals”. The grammatical usage was different from the noun “megumi”, but as it happened, it would have been acceptable in the context of that issue. Only the broader context of the church bulletin made the typographical error obvious.
Obviously, substantial user interaction is necessary. Most input methods for Japanese involve presenting the user with a menu of choices; however, the interaction goes beyond this. The input methods will give the user a means to register new words in the dictionary and often a way to specify the priority in candidate lists. Furthermore, dictionaries are pre-sorted according to common usage, but sophisticated input methods will keep track of each user's own style, presenting the candidates used most often early in the menu.
Users often have preferences among input methods even for the relatively simple case of accented characters in European languages, so each user will want to make the choice himself. Furthermore, no current input method is useful for more than two or three languages. Wnn, a dictionary server originally developed for Japanese, also handles Chinese and Korean with the same algorithms, although each language is served by a separate executable. The implication for internationalization is that protocols for communicating between applications and input methods will be very useful, so that users may select their own favorite and even change methods on the fly if the language environment changes. In X11R6, this protocol is provided by the X Input Method (XIM) standard; however, no such protocol is currently available for the console.
Although detailed discussion of the input methods themselves is beyond the scope of this article, I will describe the most common approaches to user interfaces for input methods. First of all, for non-Latin alphabetic scripts, the keyboard will simply be remapped to produce appropriate encoded characters. Both X and the Linux console provide straightforward methods for doing this. For novice users, the key-caps will need to be relabelled as well; touch-typists won't even need that.
For accented scripts, unless the number of accented characters is very small, it will not be possible to assign each one to its own key. One method of handling accents is the compose key, a special key which does not produce an encoded character itself but introduces a sequence of keystrokes which are interpreted as an accented character. Compose key methods typically need not be invoked or turned off by the user; they are simply active all the time. Since a special key is used, they do not interfere with the native language of the keyboard. The accent may be given a key of its own, but commonly some mnemonic punctuation mark is used, e.g., the apostrophe is mapped to the acute accent.
An alternative to the compose key is the dead-key method. Certain keys are called dead keys because they do not produce encoded characters; instead, they modify a contiguous character by placing an accent on it. Dead-key methods can be either prefix methods or postfix methods, depending on whether the modifier is entered before or after the base character. Obviously, these methods do interfere with input in other languages; a means of toggling them on and off is necessary.
Compose key methods are analogous to the use of a shift key to capitalize a single letter; dead-key methods are like the use of shift lock. Which is better depends on user preference and the task. Keyboard remapping, combined with either the compose key or the dead-key method, is sufficient to handle all of the ISO 8859 family of character sets.
Processing text is an extremely complex and diverse field of application. Currently, most aspects of localization and therefore internationalization have to be handled by each application according to its own needs. Programmers who want their applications to have the broadest possible utility should pay attention to internationalization issues, using standard techniques such as gettext wherever possible. They should avoid optimizations, such as using high bits in bytes or unused code points in an encoding for non-character information, that might conflict with extension to a new character set. Where standards have not yet evolved, internationalization demands that programmers design their own protocols for application-specific functionality that needs localization. Wherever possible, complex operations on text should be localized to a few functions that can be generalized to other languages or made conformable if a new standard is adopted.
Many areas come up which have been standardized already: numeric formatting, date formatting, monetary formatting and sorting. Yes/no answers have also been standardized, but this is superseded by GNU gettext.
Each of these functions has one or more functions provided by the POSIX standard for the C standard library. Linux's libc has not historically provided them, but they are all more or less fully provided in version 2 of the GNU C library. These functions are controlled by locale, an environmental parameter encoding various cultural aspects of text processing.
Locale is explicitly set in a program using the setlocale function. The current locale can be retrieved using the same setlocale function. Internally, each locale is divided into several parts which can be controlled separately. Users normally inform programs about their locale preferences using one or more environment variables (LANG, LC_ALL, LC_COLLATE, LC_CTYPE, LC_MONETARY, LC_NUMERIC, LC_TIME, LC_MESSAGES).
First of all, the convention for naming locales indicates the language, the regional subvariant and the encoding used. The “portable locale” is an exception; it has two names, C and POSIX. They have identical meaning. Two-letter abbreviations for language (ISO 639) and country (ISO 3166) have been standardized. So U.S. English, for example, may be specified as en_US.iso646-irv. (ISO 646-IRV is the version of the U.S. ASCII standard published by the ISO.) This has a slightly different meaning from en_US.iso8859-1, in that the latter specifies use of the ISO 8859-1 encoding, which would permit the direct inclusion of accented letters from German or French if the necessary fonts were available. The former does not. How these differences are handled will be implementation-dependent, and even within Linux the console driver handles this differently from X.
British English would be specified as en_GB.iso8859-1. (ISO 646-IRV would not be satisfactory here, as it does not include the pound currency sign.) The U.S. and British locales do not differ on things like spelling. Theoretically, ispell could take a hint from the LANG variable, but as far as I know it does not. The main differences would be currency formatting and of course the dates, i.e., the U.S. uses MM/DD/YY, while Britain uses DD/MM/YY. Furthermore, Linux provides an English language locale for Denmark (reflecting the nationality of Keld Simonsen, who coordinates the locale library for WG15 of the ISO); this locale uses the Danish kroner as currency unit and the ISO 8601 standard YY/MM/DD for dates.
Another example is the several Japanese locales. While the Japanese language is widely used only in Japan, so that all of them start with ja_JP, there are several commonly used encodings. The locale normally used on Japanese Linux systems is ja_JP.eucJP (using the EUC-JP encoding), but internationalized software running on Japanese MS Windows systems would presumably use the ja_JP.sjis locale (using Microsoft's Shift-JIS encoding for Japanese). The reason for the difference is that UNIX file systems are compatible with file names encoded in EUC-JP, while MS Windows file systems will use file names in the somewhat different Shift-JIS encoding. This could cause problems with Japanese file names in MS-DOS and VFAT file systems mounted on a Linux system, as the POSIX locale system does not allow for multiple locales to be simultaneously active. Some elderly Japanese systems which are not 8-bit clean might use the ja_JP.jis locale, with the basic seven-bit JIS encoding.
The following aspects of a system are affected by the locale. The first five are implemented in libc according to the POSIX standard. Others are implemented in X or ad hoc by application software. Those implemented by libc are controlled explicitly by the setlocale call, which normally will default to the contents of the environment variable LANG. The remainder are implemented as “advice” encoded in the LANG environment variable or other environment variables.
numeric formatting
date formatting
monetary formatting
collating (sorting)
yes/no messages
display fonts
file system encoding
text file encoding
input method
The display fonts are normally set by the application according to the encoding portion of the locale (after the period). Russian, Japanese and traditional Chinese all have multiple encodings. However, most fonts are provided in only one encoding, so applications must re-map other encodings internally. If this remapping is not done properly, the display will be unintelligible “mojibake”, pronounced MOH-JEE-BAH-KAY, a Japanese word literally meaning “changed characters” but more fancifully translated “monster characters”. Compare the Japanese text encoded in EUC-JP in Figure 4 with the mishmash of punctuation and funny characters produced when the kterm is explicitly told to interpret the text as Shift JIS in Figure 5. This is familiar to users of programs ported from DOS which use text windows based on the PC line-drawing characters. Since most Linux fonts are based on the ISO-8859-1 character set, you get “French windows” bordered in frilly accented characters rather than lines.
Figure 4. Japanese Text Encoded in EUC-JP
Figure 5. Japanese Text Encoded in Shift JIS
The file system encoding is also retrieved from the advice in the encoding portion of the LANG variable. Here, it is critical that the application be very defensively programmed. Carelessly accepting the advice may result in files with names which get corrupted when inserted in the file system or which cannot be accessed.
Text file encodings are similarly defaulted to the advice in the encoding portion of the LANG variable. However, in a networked environment, alien files will often be imported, e.g., using FTP, and there is no reason to suppose that these files will have the same encoding as the current locale. Applications should provide a means of specifying the encodings of files used; in locales where multiple encodings are available (today, Japanese, Russian and traditional Chinese, but soon with the popularization of Unicode and UTF-8, all locales), utilities for translating among compatible encodings should be provided.
Finally, a default input method can often be guessed from the LANG variable. In current systems, it will often be bundled with the keyboard mapping or console driver. X provides a more flexible system in which the XMODIFIERS environment variable is consulted to learn the user's preferred input method for each locale.
Next month, I will look at the large body of internationalization standards which have evolved to handle these problems.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}