
Improving Application Performance on HPC Systems with Process Synchronization
One would expect that doubling the processing power available to an application would double the application performance or cut the run time in half. Unfortunately, HPC users know this is far from true, with actual performance efficiency dropping to as low as only 5% of a system's theoretical peak performance. HPC researchers and application developers have spent and continue to spend much effort trying to find the source of these performance losses and boost sustained application performance. When we set about developing the Cray XD1 system, we joined the ranks of researchers attacking this problem. This article describes how we learned from those who went before us and how we built on that knowledge to develop a new Linux scheduling-based solution that promises to improve real application performance significantly on Linux HPC systems.
The majority of research has focused on the structure of the HPC applications themselves. Various research teams attempted to improve the efficacy of caching, looked for ways to minimize interprocessor communications and explored a variety of similar measures, but each strategy offered performance gains of only a few percent. Another area of research has shown particular promise, however. By understanding the interaction between the HPC application and the system background processes, one can find ways to modify this interaction to improve performance.
In a seminal paper documenting their research into this interaction, researchers Petrini, Kerbyson and Paking of the Los Alamos National Labs (see the on-line Resources) quantified the loss in application performance caused by what they deemed “noise”—the interaction between large multiprocess MPI jobs and background processes. They observed that housekeeping tasks, or noise, delayed individual processors from reaching MPI barriers (synchronization points in the application) and caused all other processors to wait while one processor finished up its housekeeping. This resulted in wasted cycles on all other processors.
The top half of Figure 1 illustrates this interaction and how it results in lost performance. The processes illustrated are part of a parallel job, each running on a separate processor and periodically synchronizing through the use of MPI barriers. In the first part of the computation, Process 1 is delayed because the node's scheduler pauses process execution to run background processes, such as those found on every Linux or UNIX node. Processes 2 and 3 also are delayed. Repetition of this pattern results in substantially reduced sustained application performance. The magnitude of the impact is a function of the frequency with which barriers are encountered and the number of processors.
Petrini and colleagues quantified this loss of performance running SAGE, a compressible Eulerian hydrodynamics code, on their HPC system, named ASCI Q. ASCI Q is a cluster of 2,048 HP ES45 nodes, where each node is a four-way SMP. Petrini, et al., observed that better performance was obtained when they restricted SAGE to run on only three of the four processors in the SMP when more than 256 nodes were utilized. They theorized that this result was caused by background noise, and the theory was verified by eliminating many of the sources of noise and observing the improvement in performance.
This research points to lack of process synchronization and wait time as the culprit that is robbing fine-grained and highly parallel HPC applications of up to 50% (and perhaps more) of their potential performance. Unfortunately, a means to stop this thievery still was not at hand. The method employed by Petrini, et al., to identify the culprit—restricting the system's freedom to run housekeeping tasks—doesn't present a practical solution for most HPC applications. The prospect of relegating one-quarter of the processors on an HPC system to running housekeeping tasks is not palatable to many HPC sites. In addition, many background processes cannot be removed, limiting the performance gain achievable using this approach.
When we set out to build a new high-performance computer, we also set out to find a way to prevent this performance theft. We considered a new approach using the Linux scheduler to synchronize scheduling of MPI jobs and housekeeping tasks. Previous work and our research suggest that this new synchronized scheduling approach can deliver a 50% or greater performance boost to many fine-grained parallel applications running on 32 or more processors.
Our approach was to create a new Linux scheduling policy. To achieve the desired gains, this policy must synchronize the schedulers on all nodes in a Linux HPC system to ensure that MPI processes run concurrently on all processes and that Linux housekeeping processes execute at the same time. Thus, the scheduler must have a means to achieve global synchronization, as illustrated in Figure 1. To achieve global synchronization, we designed a feature in the communications processor to synchronize the clock in each processing node.
The new Linux scheduler policy defines a scheduling frame of 128 time slots, 120 of them reserved for application execution and eight for housekeeping processes. Schedulers on different processors are able to align their scheduling frames by exploiting a globally synchronized clock, which guarantees sub-microsecond variation in time between nodes in the system. At any moment in time, all processors either are executing the HPC application or running housekeeping processes (bottom half of Figure 1).
This approach to process synchronization is scalable to high processor counts, because scheduling decisions are made locally on each node. This provides a significant boost to sustained application performance by eliminating wasted CPU cycles caused by waiting at barriers.

Figure 1. An Example of Asynchronous and Synchronous Execution of Processes
The synchronized scheduler is implemented as a new policy augmenting the three existing policies in the scheduler associated with the Linux kernel. The Linux scheduler is invoked when the process being executed is blocked or voluntarily gives up the CPU, when the processor receives an interrupt or at the end of a 10-millisecond timeslice. The scheduler selects the next process to run based on the scheduling policy applicable to that process and its priority. With the new synchronization policy in place, Linux then selects from one of the following scheduling policies, two for real-time processing and two for conventional time-sharing processes, listed in order of decreasing precedence:
FIFO (first in, first out): a process marked FIFO runs until it relinquishes control of the CPU. This priority is used for short duration, real-time system processes. FIFO processes run ahead of others.
Round-robin: a process using this policy receives a 10-millisecond timeslice, in turn. It is available for real-time processing.
Synchronized: we added the synchronized policy to enable synchronized scheduling of processes in a multiprocessor batch job. The workload management system marks each process as using this policy when it is started. These processes and their offspring gain the benefits of synchronized scheduling.
Priority: priority scheduling is the familiar time-sharing mechanism known to Linux users. Processes using this scheduling policy have priorities associated with them and receive time proportional to their priority. All user processes and virtually all system processes run under this policy. The scheduler selects the next process to run from the policy class with the greatest precedence. FIFO and round-robin system processes run first. Processes marked for synchronized scheduling run before processes using the normal priority scheduler.
The new synchronized scheduling policy creates a scheduling frame that dictates when batch jobs and other user and system processes are executed. The frame includes a predefined number of time slots that are cycled through in sequence. A time slot represents 10 milliseconds (one system timer tick in Linux), during which the process assigned to the time slot is executed. The current implementation has 128 time slots, 120 for the execution of batch jobs and eight for other processes. During the latter time slots, the synchronized scheduling policy indicates there are no runnable batch processes, and the conventional priority scheduling policy takes over for all other housekeeping processes. When no batch jobs exist, the behavior of the Cray scheduler is indistinguishable from the conventional Linux scheduler.
The number of time slots in a scheduling frame is configurable, but it must be a power of two. The ratio of time slots reserved for batch processing versus other processes also may be adjusted. Figure 2 illustrates a typical scheduling frame, with the locations of batch time slots shown in red and housekeeping time slots in grey.
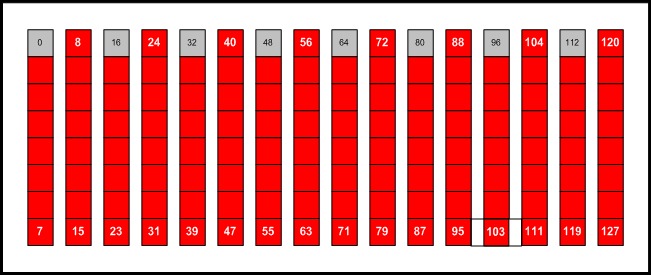
Figure 2. The Time Slots (128) with Eight Reserved Time Slots
A scheduling frame is created when the first batch process is started on a node. All batch time slots are assigned to that process. The creation of additional batch processes results in an even distribution of time slots across processes. If n batch processes are created, the first batch process receives the first 120/n time slots, the second receives the next 120/n time slots and so forth. The synchronized scheduler thus is able to support batch jobs that require multiple processes on each CPU.
A batch process executes to the end of its allotted time, as long as it makes no blocking or CPU-yielding system calls. If the batch process yields the CPU, perhaps as a result of making a blocking system call, another batch process is scheduled to run. If there are no runnable batch processes, control passes to the conventional priority scheduler to run housekeeping processes. Of course, batch processes regain the CPU if they are unblocked by the handling of an interrupt.
So far, we have discussed only scheduling of batch jobs and system processes within a single node. However, to stop the performance thievery, this synchronized scheduler must work across all processors. Here, we encounter a critical system design criteria that makes this synchronized scheduler approach possible—the availability of global time synchronization. In our design, global time synchronization is carried out by communications processors designed within the HPC system. These processors offload communications processing from the application processors. Communications processors also run a time synchronization protocol to achieve global clock synchronization. Tight time synchronization can be achieved because the communications processors have control over packet scheduling and jitter—the difference in time between any pair of processors is less than 1 microsecond. A further advantage of delegating time synchronization to the communications processors is this load is removed from the processors carrying the application workload, leaving more time for application processing and further reducing interrupts to the application processors.
The time synchronization protocol includes additional fields for time slot alignment. The protocol uses a master-slave paradigm, where one node acts as the source of the time and time slot information and all other nodes in the system synchronize themselves to the master node's clock. The time synchronization packets received from the master identify the time slot being executed and the time elapsed since the start of the time slot, enabling precise alignment of scheduling frames across the entire HPC system.
This synchronized scheduler delivers synchronized execution of the processes in a parallel application. How much performance degradation can be avoided or how much potential performance can be gained is a function of how frequently the application uses barriers and/or collective operations, how much time is taken by system housekeeping processes and the number of processors employed by the application.
Our research indicates significant speedup can be achieved. Figures 3 and 4 show the theoretical speedup that can be achieved through the use of the synchronized scheduler, relative to the conventional priority scheduler. Figure 3 assumes that background processing requires 1.5% of the CPU, and Figure 4 assumes that 6.25% of the CPU is consumed by background processing—this is a realistic metric on most clusters. Curves are shown for applications encountering an average of 100, 200 and 300 barriers per second.
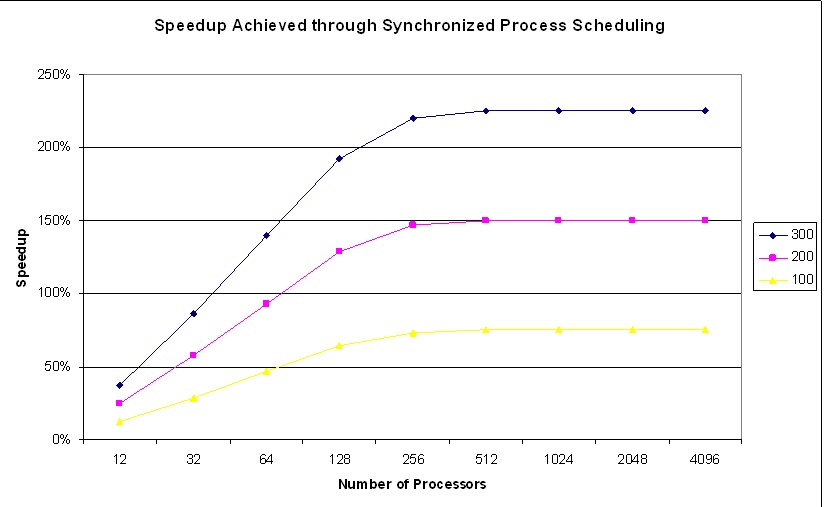
Figure 3. Theoretical Speedups with Process Synchronization with 1.5% Dæmon CPU Utilization
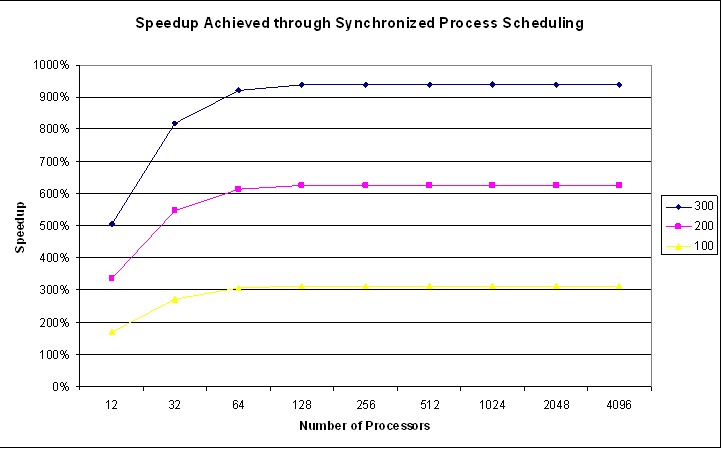
Figure 4. Theoretical Speedups with Process Synchronization with 6.25% Dæmon CPU Utilization
As the number of processors increases, the performance gain from the synchronized scheduler increases and asymptotically approaches a maximum value. This reflects the fact that performance doesn't continue to degrade with the conventional scheduler. After a certain processor count is reached, the probability of at least one processor being delayed by housekeeping increases to 100%. The addition of more processors does not significantly add to the application delay encountered at barriers.
By focusing on the interactions between the HPC application and the system background processes, HPC researchers identified a major culprit for performance losses in parallel applications. Additional research identified ways of preventing this thievery, but none to date have provided successful, real-life implementations. Global process synchronization using the Linux scheduler eliminates wait time due to noise and promises significant performance gains. By looking beyond the application and into the role of the rest of the HPC system, we believe we have found a scalable, real-life implementation. With Linux process synchronization using a global clock synchronization and Linux running on each processing node, the Cray implementation ensures application processes run concurrently on all processors and housekeeping is performed concurrently on all processors and bounded in time. Our process synchronization solution can prevent performance theft and increase application performance for fine-grained highly parallel applications running on 32 processors or more by up to 50%.
Resources for this article: /article/7756.
Dr Paul Terry is the Chief Technology Officer for Cray Canada, Inc., previously OctigaBay Systems, which was acquired by Cray in April 2004. He is a technology strategist for innovative computing architectures and is responsible for establishing the company's technology vision and leadership.
Amar Shan, Director of Product Management, Cray, Inc., is responsible for introducing Cray's leading-edge technical innovations and creative business solutions into the marketplace. He has more than 20 years' experience in the computing and telecommunications industries in product management, development and architecture roles.
Pentti Huttunen, Benchmarking Specialist at Cray, Inc., is responsible for researching parallel computing technologies and optimizing applications to ensure that they are running efficiently on a variety of platforms at Cray, Inc.




