
Overcoming the Challenges of Developing Programs for the Cell Processor
In June 2008, Los Alamos National Lab announced the achievement of a numerical goal to which computational scientists have aspired for years—its newest Linux-powered supercomputer, named Roadrunner, had reached a measured performance of just over one petaflop. In doing so, it doubled the performance achieved by the world's second fastest supercomputer, the Blue Gene/L at Lawrence Livermore National Lab, which also runs Linux. [See James Gray's “The Roadrunner Supercomputer: a Petaflop's No Problem” on page 56 of this issue.]
The competition for prestigious spots on the list of the world's fastest supercomputers (www.top500.org) is serious business for those involved and an intriguing showcase for new technologies that may show up in your data center, on your desk or even in your living room.
One of the key technologies enabling Roadrunner's remarkable performance is the Cell processor, collaboratively designed and produced by IBM, Sony and Toshiba. Like the more-familiar multicore processors from Intel and others, the Cell incorporates multiple cores so that multiple streams of computation can proceed simultaneously within the processor. But unlike multicore, general-purpose CPUs, which typically include a set of four, eight or more cores that behave essentially like previous-generation processors in the same family, the Cell has two different kinds of processing cores. One is a general-purpose processor, referred to as the Power Processing Element (PPE), and the remaining (eight in the current configurations) are highly optimized for performing intensive single-precision and double-precision floating-point calculations. These eight cores, called Synergistic Processing Elements (SPEs), are capable of performing about 100 billion double-precision floating-point operations per second (100 Gflops).
The Cell processor also powers the Sony PlayStation 3 and is available from IBM in blade format for clusters and the data center. With a wide range of systems using the Cell, it is interesting to speculate on the importance it will have on the market. Although a number of significant factors beyond flop ratings will contribute to its success or failure, traditional considerations, such as price, availability and reliability, still will be important. Power efficiency and the difficulty or ease of adapting applications to take advantage of the architecture also are critical factors. If only a slim subset of applications can take advantage of a processor, or if application adaptation requires an investment of time and energy disproportionate to its benefits, how widely will it be adopted?
Recognizing the significant interest in the Cell and the accompanying concern about programmability, TotalView Technologies recently introduced a version of the TotalView debugger specifically adapted for debugging on the Cell. Doing so required significant changes to the way that the debugger models what takes place within threads and processes in order to provide computational scientists and developers with a clear representation of what is happening in a Cell program.
This article outlines the challenges faced in writing or porting applications to the Cell, some of the elements of the Cell environment and typical Cell programs that make understanding what is happening especially difficult, and specific actions users can take to develop and troubleshoot Cell programs effectively. Many of the same issues encountered in debugging Cell applications also arise with other techniques, such as general-purpose computing on graphics processing units (or GPGPU programming).
The architecture of the Cell presents two general challenges software developers must solve when writing new software or porting existing software to the Cell. The first challenge is breaking the key components of a program into small chunks that can execute on the eight SPEs. In numerical programs, this often means dividing the data into small independent units. In other cases, individual tasks or pipeline stages may be delegated to specific SPEs. This issue of problem decomposition is similar to that of adapting an application to a distributed memory cluster environment, although the granularity is different due to the limited memory space directly available to each SPE.
Each of the eight SPE cores that is part of the Cell processor has its own independent registers and a small amount of local memory (256KB) used for storing instructions and data. This memory acts similarly to a cache in a general-purpose processor, in that it has a limited size and can be read and written very quickly. Unlike a cache, however, its contents are managed directly by the application. The code units running on the SPE elements are allowed to initiate direct memory access operations that can copy chunks of data from the main memory into the SPE local store or back to main memory from the local store. The same memory is used for the machine instructions and global memory, heap memory and stack. The heap and the stack change size over time, and the programmer must take care to avoid collisions between these different memory ranges, because there is no memory protection. This explicit management of memory is the second major challenge in designing Cell implementations. Because each processor has a completely separate local store, the structure of a program for the Cell is very different from the structure of a traditional multithreaded application, where all the threads share the same memory.
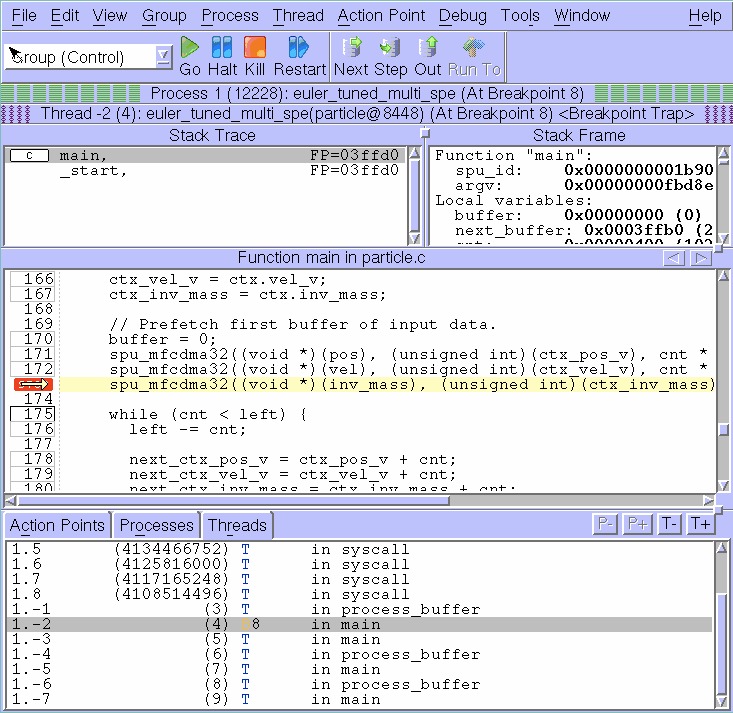
Figure 1. A simple display of code running on a Cell processor. In this example, one of the SPE threads is requesting data from main memory in preparation for a computation. Other SPE and PPE threads are stopped in a variety of states.
Developers who want to write code for the Cell processor will need to find ways to address these two issues in their programs. Architecture abstraction layers, like the one provided by RapidMind, may allow developers to write code that will run on a range of processors, including the Cell. If developers are going to obtain the best possible performance, however, they need to make use of the control obtained by programming for the SPEs themselves, at the expense of longer and more complex code.
The Cell provides exceptional performance by making it possible to achieve and sustain a high level of concurrent execution. Each SPE element can execute simultaneously and asynchronously, and has 128-bit wide registers and support for vectorized instructions that can apply a mathematical operation synchronously to more than one number at a time. Performance gains do come with trade-offs, however, including increased complexity and unpredictability. When working with a serial application in which all computations happen in a single sequence, the system tends to be highly predictable. Given a set of input conditions, a serial program tends to behave the same way every time, even if it is malfunctioning.
Concurrent applications, especially malfunctioning concurrent applications, may behave in different ways if the sequence of operations in the various threads differs from run to run. These differences lead to elusive race conditions when only some sequences provide the correct behavior. In order to eliminate race conditions, developers can use synchronization constructs, such as barriers, to constrain the set of execution sequences whenever two or more threads need to read or write the same data. Synchronization needs to be applied very carefully, as its misuse will result in reduced performance or deadlocks.
TotalView is a highly interactive graphical source code debugger that provides developers working in C, C++ or FORTRAN with a way to explore and control their programs. Originally designed to debug one of the first distributed memory architectures, the BBN Butterfly, TotalView has since been enhanced continually with a focus on multiprocess and multithreaded applications. Today, TotalView is used to develop, troubleshoot and maintain applications in a wide range of situations. One group uses it to develop Linux-based commercial embedded computing applications consisting of a single process with a hundred or more separate threads that simultaneously interact with a graphical user interface (GUI), sensors, on-line databases and network services. Other users troubleshoot sophisticated mathematical models of complex physical systems in astrophysics, geophysics, climate modeling and other areas. These models typically consist of thousands of separate processes that run on large-scale high-performance computing (HPC) clusters on the top 500 list. In both cases, TotalView provides users with a debugging session in which they can examine in detail any one of the many threads or processes that make up the application, control each thread or process singly or as a part of various predefined and user-defined groups, and display multiple types of data and state information from across many processes and threads.
The version of TotalView for the Cell applies these same user-interface techniques and capabilities to the multiple threads of execution that are running on the PPE and SPEs within each Cell processor. It also extends to Cell applications that run as distributed memory parallel applications on clusters of Cell BE blades. In order to extend this interface, however, it was necessary to extend significantly the definitions and models of processes and threads that the debugger uses internally to represent what is happening.
TotalView's traditional model for programs has three tiers: threads, processes and groups of processes. A thread is a single execution context, with its own stack (and, therefore, its own copy of any automatic or local variables) and its own state (either running or stopped). A thread also may have additional characteristics, such as a handle to “thread private” memory, an identity related to a specific OpenMP construct in another thread that is part of the application, or an operating system-assigned thread ID. A thread shares a single virtual memory address space, including both text (instructions) and data (global variables, heap memory and stack memory) sections, with the other threads that may make up a process.
A process is made up of one or more threads that are all executing a single executable “image” that represents a program. The image involves the base program and a list of library images that are loaded either at launch or during runtime. A process also has a number of resources attached to it that are managed by the operating system, including a virtual memory address space (shared with its threads), file handles, parent and/or child relationship with other processes and an operating system-assigned process ID.
Groups are made up of one or many processes running on one or more machines. These processes can be all executing copies of the same program image or, more rarely, even a different image. TotalView notes which processes in a group share the same image and shares and/or reuses information wherever possible. When the user sets a breakpoint on a line of code within a group, TotalView ensures that the breakpoint appears at the right place in each process that shares the same image, even if those images have different offsets (which can happen due to randomized library load addresses across the many nodes of a cluster).
In order to support the Cell processor correctly, several changes to this model were necessary. Most significant, the SPE threads that make up a Cell process have a more distinct identity than threads created on a traditional processor. The SPE core uses a different instruction and register set from the PPE core, so the Cell version of TotalView can handle both, transparently switching between them depending on the kind of thread under operation. The SPE thread actually executes in a separate local memory space, so all the characteristics of memory space traditionally associated with processes are now associated in TotalView with threads on the Cell. As a result, looking up a variable or function in any specific SPE thread or in the PPE thread will give very different results, depending on the variables and functions that exist within the memory local to that thread.
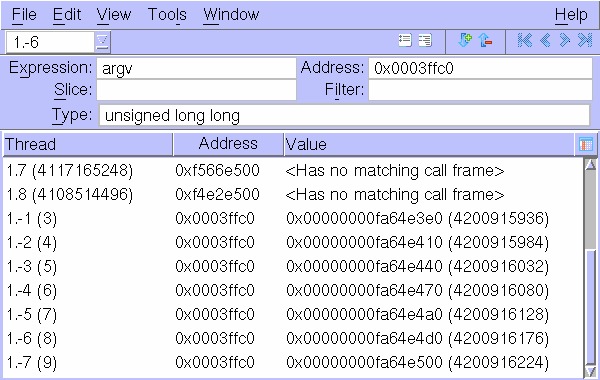
Figure 2. A simple display of variable data as seen by the SPE threads of a Cell program. In this example, there are eight SPE threads executing the same bit of code. All eight have a variable named args at 0x3ffc0, but because each SPE has its own local store, the value of this variable can be different for each thread.
And, this is important to represent clearly what actually is happening in the program. Depending on the Cell executable's construction, the SPE threads may look like separate programs (which happen to do all of their IO via DMA calls) with their own main() routine. Much of the key information about the code running in the SPE threads is different from the PPE process that contains it. User-defined data types, functions and global variables that accidentally or intentionally have the same name in both the SPE and PPE probably refer to distinct things, and the code may be different between two different SPE threads that are part of the same process.
A single Cell program may load many distinct images at the same time to run on different SPEs, and a breakpoint set on a specific line of a specific SPE thread may or may not need to be duplicated across other threads (the user can choose). It certainly shouldn't be set at that same address in threads that don't execute that line of code there. Because the threads are executing and issuing DMA memory read and write requests and synchronization operations around those requests, there is a significant opportunity for race conditions and deadlocks. TotalView provides a set of thread control commands that allow developers to approach these problems systematically by exploring specific sequences of execution among the various SPE and PPE threads.
The intensive explicit memory management required for each unit of data moved in and out of the SPE local memory means that developers are concerned with low-level issues of data representation, layout and alignment. As they are moving units of memory from the PPE to the SPE and back again, it is quite common to want to examine the data on both sides of the transfer. TotalView provides the ability to explore the data in any thread in exactly the same terms as it is being used within that thread. This is a significant benefit. One computational scientist noted that before TotalView was available on the Cell, he had to perform offset calculations with a calculator every time he wanted to look at a variable on the SPE.
To understand the data that has been transferred to or from the SPE threads, scientists and programmers can navigate data structures and large arrays, following pointers as if they were HTML links in a browser, and sort, filter and graph the data they find.
The TotalView process group model applies to the version on the Cell with very little modification. Users can work freely with large groups of processes running on one or many blades. The only change is a more nuanced model that allows breakpoints to be shared between threads that are all executing the same image, rather than between processes executing the same image.
The changes made to TotalView in order to provide for clear troubleshooting on the Cell processor highlight the architectural distinctions that are uniquely challenging for scientists and programmers writing software for the Cell. The capabilities that were developed in response to these distinctions make the process of adapting software to the Cell a bit less daunting for those scientists and programmers.
These lessons may apply in other situations. For example, a program written for the Cell somewhat resembles a program written to take advantage of graphics co-processors as computational accelerators. This technique, called GPGPU (General-Purpose Graphics Processing Unit) programming, also involves writing small bits of code, called kernels, which will execute independently on specialized hardware using a separate device memory for local store. GPGPU programming introduces the additional notion of extremely lightweight context swapping and encourages developers to think of creating thousands of threads, where each might operate on a single element of a large array (a stream, in GPGPU context). Many of the same programming and debugging challenges exist for this model, and future debuggers for GPGPU should give developers clear ways of examining the stream data in both main memory and the GPU store by accurately representing what is happening in the GPU, and displaying the state of thousands of threads to the user.
Developers who work with multithreaded applications on other platforms can thank their caches that they don't need to deal with explicitly loading data into and out of each thread. They can concentrate instead on the challenge of finding the right level of concurrency for their application, their processor and its cache.
Chris Gottbrath is Product Manager for the TotalView debugger and MemoryScape product lines at TotalView Technologies, where he focuses on making it easier for programmers, scientists and engineers to solve even the most complex bugs and get back to work. He welcomes your comments at chris.gottbrath@totalviewtech.com.





