
eVote Adds Elections to Mailing Lists
A specialized database server for keeping votes, combined with a conferencing system, can create a medium for a true nonhierarchical democracy (see the Ideal Democracy Sidebar). The work of administering the voting system would be shared by the users and the software, not the system administrator. When the correct architecture for the problem came to me, I could no longer simply advocate Electronic Democracy; I built it.
Ideal Democracy Includes Both Discussion and Voting
The specialized vote server, the Clerk, is written in C++ and provides many features for voters. Anyone can initiate a poll, and users can change their votes as long as the poll is open. Polls also can be public, allowing all the participants to view each other's votes, private, or if_voted, allowing us to know who voted but not how they voted. Several poll types are supported: yes/no, numeric and grouped. The software is easily enhanced to add new features and poll types by extending the existing classes. The Clerk maintains data on the fly, requiring no help from the administrator. True to the promise of object-oriented architecture, the addition of each new feature has made the code more robust.
The ballots are dynamic. When the user closes her poll and then drops it from the conference, and when the software is otherwise idle, the ballots are collapsed, rolling the storage bytes for other items toward the top and making space for new polls. The item objects recalculate their new places in the ballots, and everything is set to continue without any intervention from the administrator.
The Clerk's main() function is an infinite loop that watches for incoming messages on the interprocess communication messaging facility from eVote clients, i.e., user-interface processes with live voting users. The Clerk has one permanent message queue for incoming requests from users, and it is managed by the single instance of the InQ class. Each eVote process has a temporary message queue of its own for receiving messages from the Clerk. These are instantiations of the OutQ class.
Although the statistics about polls and the personal information requested by a voter are communicated via the OutQ objects, another interprocess communication facility, shared memory, is used for slow-moving data. The list of poll items and their properties are stored in shared memory so that all the eVote clients currently active in the same conference can see them. Properties of the poll items may include public, private or if_voted, where users can see if another voter has voted, but not how he voted; yes/no or numeric; visible or hidden, where the statistics are available only after the poll is closed; single or grouped; and the title.
The conference's ItemList object is responsible for maintaining the shared memory. When a new poll is created for a conference, if the growing list of poll items requires a new patch of shared memory, a message is sent to all active eVote clients. This dynamic notification feature enables the voters to conduct their meeting in real time.
The Clerk keeps three data files for each conference or e-mail list and one overall data file that lists all the e-mail addresses and a corresponding numerical ID. For the sample e-mail list, a sample.dat with the current ballots, keyed by the voter's numerical ID, is kept by the BallotBox object. The BallotBox also keeps sample.bnf, which contains a hash into sample.dat and some handy statistics. A sample.inf file storing the current map of items onto the ballots is maintained by the ItemList object.
eVote, the user interface, keeps a petition's signatures and comments in a flat file, one file per petition.
At this time, the Clerk has two user interfaces and invites more. The Clerk's first user interface is a simple text-based Telnet interface, designed with conferencing systems and BBSes in mind.
The explosion of the Internet dampened enthusiasm for conferencing systems. E-mail arose as the dominant form of communication, and e-mail lists became the community discussion medium. So the e-mail user interface was built to allow e-mail communities to make formal decisions, while still using the popular Mailman mailing-list software.
eVote's e-mail list interface provides three levels of participation:
Voter: users can vote and change their votes; they also have the same power to query the data, as does the administrator of the poll and the list's owner.
User/administrator: any user can initiate a poll. Under ordinary circumstances, only the user who starts a poll can close or drop it from the data.
List owner: some commands are password-protected. These provide overriding powers so the owner can close/drop any poll, change the voting privileges or move a participant's ballot to a new e-mail address. The list's owner also retains the same responsibilities and powers as owners of lists without eVote.
The overall architecture of the e-mail facility is shown in Figure 1. eVote is five programs that work together: eVote_Clerk, the Clerk; eVote_insert, the e-mail list user interface; eVote_mail, the mail administrator's utility interface; eVote_petition, the interface for signers of petitions; and eVote, the command center for controlling the Clerk.

Figure 1. eVote's Mail Interface
eVote_Clerk runs continuously in the computer's background, establishing new polls, dropping old items, accepting, tallying, storing and reporting votes and statistics. eVote_Clerk has no direct user interface. It is started, controlled and stopped by the eVote executable.
Many Possibilities: eVote's Poll Types
The eVote_insert executable is the e-mail interface that coordinates with Mailman, the popular open-source e-mail list server. Mailman provides the discussion medium; eVote provides the voting facility. This cooperation is configured in the alias file of the mail transfer agent (MTA). Exception: if the MTA is Exim and the listserver is Mailman, Exim's configuration file handles lists and the cooperation with eVote.
eVote_mail allows the site administrator to synchronize the Clerk's list of subscribers to Mailman's list. The site administrator can use this program to block voting from a specific address or to drop an address from all lists. Similarly, this program can delete stale messages that have been awaiting confirmation.
Two facilities are present in eVote's e-mail interface: polling in e-mail lists and petition support. The petition facility allows anyone to participate, while the e-mail list facility allows only addresses on the e-mail list to participate. Petitions are administered collaboratively by members of a petition list, which is any list whose name starts with the word petition, say, petitiona, petitionb and so on. Polls initiated in petition lists have the option of being open to nonmembers.
The eVote executable is the command center for eVote and can be called with various arguments. Depending on the argument, eVote will start, stop or check the Clerk, check and synchronize data, or flush or restart the log.
Mailman can be invoked by any MTA such as sendmail, Exim or Postfix. Normally, mail directed to the e-mail list address is piped to Mailman's wrapper program to control permissions on the process and to limit the programs executed through the pipe. The wrapper then calls Mailman's post script to broadcast the mail to the list's addresses.
The alias entry for the regular Mailman list called sample might look like:
sample: "|/home/mailman/bin/wrapper post sample" sample-admin: "|/home/mailman/bin/wrapper mailowner sample" sample-request: "|/home/mailman/bin/wrapper mailcmd sample" sample-owner: sample-admin
The mailcmd program needs a few new lines of code to tell it to send e-mail notification to eVote whenever someone successfully subscribes or unsubscribes from the list.
Mail to be broadcast to list members is piped to Mailman's post program by the sample: alias.

Figure 2. Mailman without eVote
eVoting is turned on by inserting eVote_insert in the pipe:
sample: "|/home/mailman/bin/wrapper eVote_insert post sample"
Wrapper's C source code gets a few modifications so it will allow eVote_insert to be run. Now eVote gets a first look at all the mail coming into the list's broadcasting address. If the first word in the incoming message is eVote, eVote_insert intercepts the message for vote processing. Otherwise, it sends the message on to post (Figure 3).
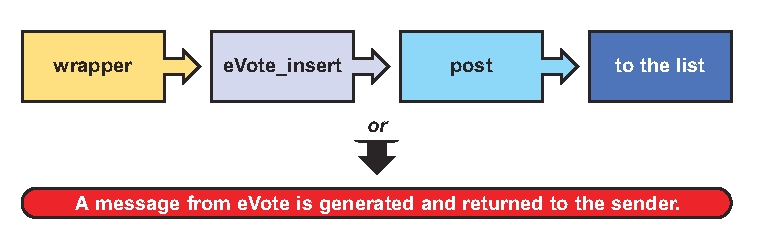
Figure 3. eVote Checks Mail
Petition lists are set up exactly as other eVote lists. As previously mentioned, eVote recognizes them as special because their names start with “petition”. These are intended to be used for collaborating on the administration of a petition. Members of a petition list can discuss and poll themselves, and they also have the power to set up a petition for the whole world to sign. These petitions can include any of eVote's vote types, and they always invite a comment from the signers.
The petition facility has an additional alias for receiving signatures:
eVote: "|/home/mailman/mail/wrapper eVote_petition"

Figure 4. Petition Facility
The one eVote_petition alias processes signatures for all petition lists at the facility.
As it is, the eVote/Clerk system is not designed for and is not suitable for presidential elections. With two major enhancements, however, it could be the most secure and accurate solution. The required enhancements are:
A networking layer so networked Clerks manage the distributed data. The network would also facilitate a check on other Clerks' data and calculations. For example, if a voter votes with one Clerk and is sent a receipt from that Clerk, and later, a second receipt is sent to the voter from a different, randomly chosen Clerk, this process would ensure the integrity of all the Clerks.
A secure encryption layer so only the software and the voter can see that voter's ballot.
With these enhancements, the Clerk could provide more security than generalized database servers because Clerks can redundantly and geographically distribute the votes to many small computers running a GNU system. In addition, the individual administrators have minimal responsibility and minimal power, and each administrator is watched by the network of Clerks. Finally, the Clerk involves voters in facilitating not only recounts and redundant checks but revotes as well. With a system such as this one, we can go confidently into our electro-democratic age.
Marilyn Davis (marilyn@deliberate.com) earned her PhD in Theoretical Radio Astronomy in the ancient past. Now she waits tables and teaches Python, C and the GNU development tools at UCSC Extension in Sunnyvale, California.
email: marilyn@deliberate.com

