
A Review of the Always Innovating Touchbook
The Netbook form factor is as boring as it is predictable: a 9–11" screen, an Atom processor, a small hard drive and about 1GB of RAM, all shoved into a small case with a cramped keyboard. Netbooks from Dell, HP, Acer, ASUS and others all fit this definition.
Fortunately, some companies are willing to try new ideas and form factors. One of these products is quite unlike anything else in the Netbook space and its called the Touchbook from a company named Always Innovating (Figures 1 and 2). True to the company name, the $399 Touchbook does have several innovating features that set it apart from other Netbooks.
For one thing, the Touchbook does not use an Atom processor. Instead, its hardware is based on the BeagleBoard Project and is built around the Texas Instruments OMAP3530 processor.
The Touchbook also has an interesting approach to expansion cards and onboard storage. The included Bluetooth and Wi-Fi adapters plug in to two of the Touchbook's four internal USB ports and the “hard drive” is a standard 8GB SDHC card like you might use in your digital camera.
The hardware design is the opposite of what you find in most Netbooks. Instead of trying to squeeze everything into the smallest, thinest, lightest package, AI has created a case where everything has plenty of space and is easily removable—usually without tools and in the worst scenario, with just a screwdriver. This results in a case that is curiously blocky and as thick as a standard notebook.
Another interesting design decision was to make the Touchbook a tablet first and a Netbook second. Because of that, the screen section is thicker and heavier than the keyboard section. This leads to a problem I've never had with a notebook-style computer before: if the screen is at more than a 90-degree angle the Touchbook will fall over backward.
The advantage of this design is that the keyboard can be completely removed from the Touchbook (Figure 3). The screen half has everything it needs, including a 6000 mAh battery. You even can save $100 off the cost of a Touchbook by purchasing it without a keyboard. The only things in the keyboard half are the keyboard, a touchpad and a 12000 mAh battery. Always Innovating claims ten hours of battery life for both batteries together.
The screen half also can be turned around and mounted to the keyboard backward. This could be useful in several situations: if you want to have the Touchbook in tablet mode but want to keep the keyboard with you, or if you want to prop the Touchbook up to watch a movie.
The screen measures 8.9" diagonally and has a resolution of 1024x600 pixels. True to its name, the screen is touch-sensitive. Unfortunately, it is a resistive touchscreen and not a more-accurate capacitive touchscreen.
Rounding out the hardware, the Touchbook comes with 256MB of RAM, 256MB of NAND Flash memory, three external USB ports, an accelerometer, stereo speakers and headphone/microphone jacks.

Figure 1. The entire contents of the box the Touchbook came in—no literature, no manuals, just the Touchbook, a stylus, three magnets and a power brick.

Figure 2. The Touchbook

Figure 3. The Touchbook Screen Detached
The hardware on the Touchbook is definitely not what I'm used to in the Netbook and notebook space. For one, it is more accessible and hackable. You slide one latch, and the entire back cover of the screen half comes off. Inside, everything is easy to get to and various parts can be either unplugged (the Wi-Fi and Bluetooth modules) or unscrewed (the motherboard and battery). There are some size and weight trade-offs that go along with this, but I can live with them. If you're looking for a thin and light Netbook, the Touchbook probably is not for you. But, if you like digging into the guts of your devices, the design of the Touchbook makes it easy to disassemble and hack.

Figure 4. The Touchbook with the Back Cover Off, Top View
The form factor lends itself to some interesting applications. For example, you could hang the Touchbook from the back of a headrest in a car and use a Bluetooth keyboard for a bit of word processing while on a trip. It would have been nice if the detachable bottom part of the Touchbook turned into a Bluetooth keyboard when unplugged. Then, when you detached the screen, you still could use the keyboard.
Probably the most unusual peripheral that ships with the Touchbook is a set of three magnets. They're each about the size of a US dollar coin (bigger than a quarter, smaller than a 50-cent piece). These strong magnets came stuck together and were very hard to take apart (I had to use the edge of a table). There's even a note on the Always Innovating Web site saying they're working on their packaging so that the magnets are easier to take apart when you first get them. Keep these magnets far away from any children as they will get their fingers pinched if they try to play with them.
The purpose of the magnets is to allow you to stick the Touchbook to a metal surface, like your fridge. The back cover of the Touchbook has three metal rectangles, and you stick the foam-covered sides of the magnets to the outside of the back cover opposite the rectangles (it helps to take the cover off while doing this). The theory is that you then can stick the Touchbook to your fridge and watch a movie or play some music or surf the Web while cooking or washing dishes (watch out for soapy hands). It's sadly just a theory in my case. I don't know if my fridge is too slick or if the magnets aren't strong enough, but the Touchbook tends to slide down the side of my fridge and not stay put. I had better luck when I turned the magnets over so that the foam-covered side was toward the fridge. It probably would work perfectly if both sides of the magnets were covered in foam.
My only strong complaint about the Touchbook hardware is the keyboard—more specifically, how the keys are arranged. I'm right-handed, and I've gotten very used to using my right thumb to press the spacebar. On the Touchbook, the spacebar is off-center to the left, and my right thumb sits directly over the Alt key. There's no comfortable way to stretch my right thumb over to press the spacebar, so I'm forced to use my left thumb, which is very awkward for me.
Keyboard issues aside, I am quite happy with the Touchbook's hardware. It's refreshingly different, surprisingly accessible and doesn't look half bad (if you don't mind the rounded boxy look).
On the software side, things are not quite as rosy at present. In its defense, Always Innovating clearly states on the Web site that the operating system and other software are of beta quality. Hopefully, that will improve by the time you read this.
One issue I ran into a lot is the screen is not very responsive, especially in tablet mode. It seems more responsive in keyboard-attached mode, so I suspect the software is responsible for the difference, and it is not a flaw with the touchscreen hardware itself.
The base Linux OS also has several issues. It's a customized distribution made just for the Touchbook. One issue I had was that when errors happened during the launching of an app (and they often did), the app would silently fail to start and leave me staring at the desktop wondering if the app would ever start. This happened mainly in tablet mode.
Software updates are also hit and miss at present. When I first received the Touchbook, the Check Update menu item reported that I had an update to install and that it would download it in the background and let me know when it was ready to install. It never notified me, and there was no progress widget or dialog box to let me know how things were going. About an hour after I started the update, I managed to get the Touchbook to lock up completely, and I had to do a forced reboot by pressing the power button for three seconds. After I rebooted and got back to the desktop and checked on the update, it said I was up to date. Not wanting to operate with a system that possibly was not upgraded cleanly, I took the SD card out and followed the instructions on the Touchbook Wiki to install a fresh copy of the OS onto the card.
The basic procedure for this is as follows (replace /dev/sdX with the correct value on your system):
Download the latest sd-card.gz OS image from Always Innovating.
Take the SD card out of the Touchbook and put it into your desktop or laptop.
Unmount any mounted partitions from the card if your distribution mounts them automatically (take note of the /dev/sdX letter).
Wipe the card using dd -if /dev/zero -of /dev/sdx.
Install the OS to the card using gunzip -dc sd-card.gz | dd of=/dev/sdX.
After going through this procedure, I didn't really notice much of a difference stability-wise, but at least I knew the procedure worked.
Software on the Touchbook includes AbiWord, Gnumeric, three different Web browsers (Firefox, Fennec and Midori), a painting program called MyPaint, The GIMP (confusingly named Image Workshop in the menu), the Xournal graphical note-taking application, Evince for reading PDFs, GNOME MPlayer for playing audio and video content, gThumb for viewing photos, the FBReader e-book application, the Pidgin IM client, a Hulu client, a selection of card and puzzle games, and Crazy Tanks (a 3-D tank combat game that uses the accelerometer for steering).
I tried playing Crazy Tanks, and it seemed to play fine. I could drive around by tilting the display and shoot at other tanks by tapping on the screen. However, there is no obvious way to quit the game apart from dying or holding in the power button until the Touchbook turns itself off.
I also tried to watch an episode of The A-Team using the Hulu client. I was able to search for the show and select an episode, but it never played. I tried several other shows but none of them played either.
The other applications were along the lines of what I expected based on my experiences with them in the past.
The desktop runs Xfce4, which, although not exciting, seems to run well (Figure 5). Some applications tended to crash a lot. AbiWord, for example, tended to freeze up whenever I tried to print. I attribute this in general to the unfinished and unstable nature of the beta OS and in particular to the CUPS software.
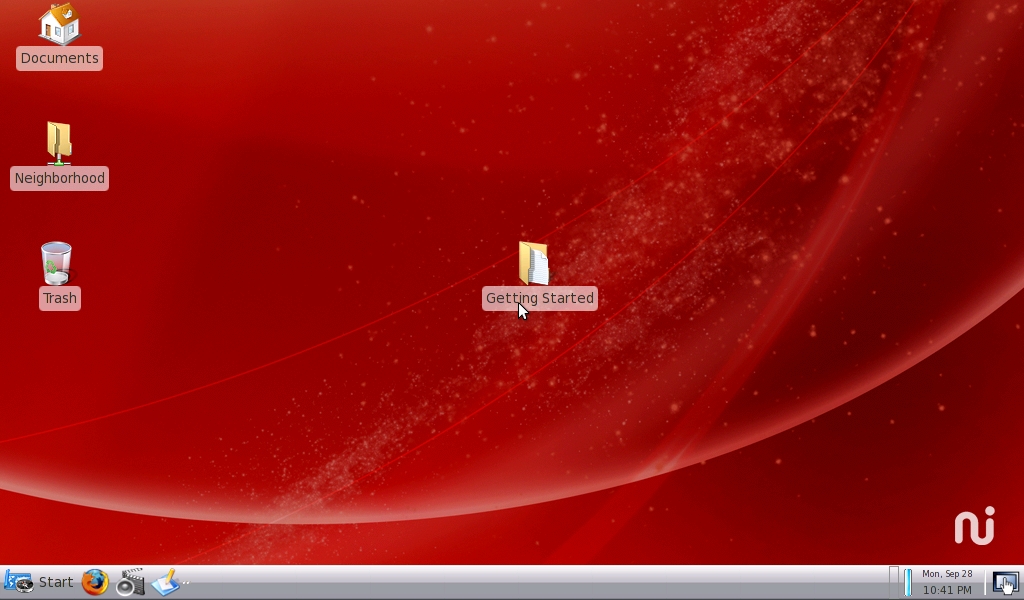
Figure 5. The Touchbook Default Desktop
The display properties window (Figure 6) lets you specify whether the display will rotate automatically, and you can further specify if you want automatic rotation only when the Touchbook is in tablet mode. The screen does rotate automatically, but the Only in tablet mode check box does not change the behavior. The screen always rotates when you physically rotate the Touchbook if the Auto rotation check box is checked, tablet mode or no.

Figure 6. The Display properties dialog is very sparse.
Speaking of tablet mode (Figure 7), I almost never had anything launch successfully when using it. In the rare instances when something did launch successfully in tablet mode, the Touchbook automatically resized everything to full screen, which makes sense.
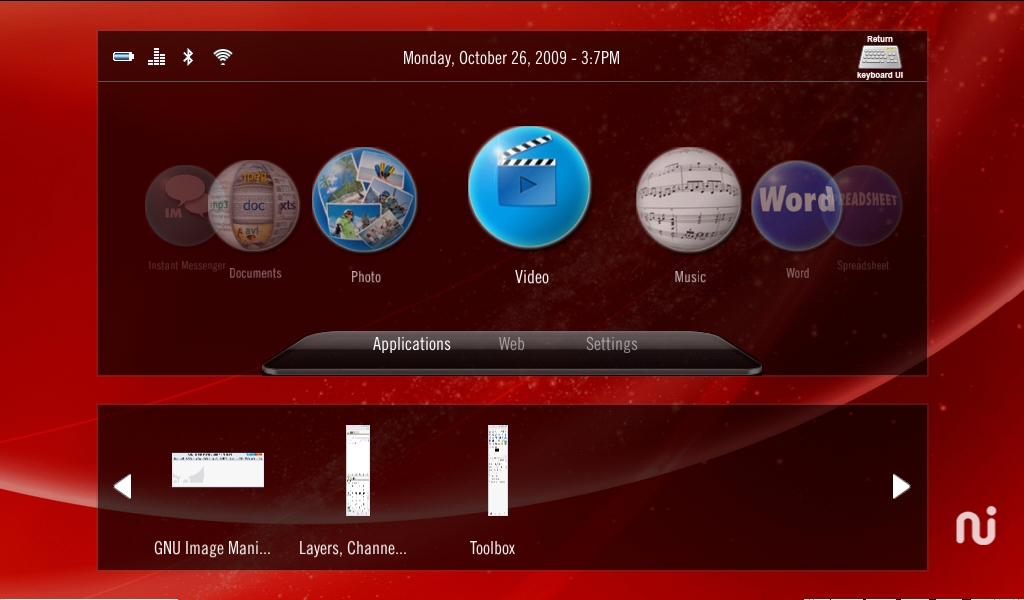
Figure 7. Tablet Mode

Figure 8. Using Xournal to Write a Note
The instability goes deeper than that with large pieces like AbiWord. Even simple things, like pressing the prtsc (aka Print Screen) button to take a screenshot didn't work most of the time. In fact, it usually worked exactly once per reboot.
The processor in the Touchbook seems quite capable for ordinary word-processing and Web-browsing tasks, but the filesystem is really slow. This stems, I suspect, from its use of an SD card for primary storage.
I ran two content tests, one for video and one for audio. For video, I tested performance with multiple sizes of the Big Buck Bunny movie from the Peach Open Movie Project. The Touchbook did fine with the 480P (854x480) sized MP4 movie but couldn't handle the extra processing required for the 480P h.264 file, a smaller 640x360 h.264 file or any of the larger files.
For audio, I used the same batch of test files I use when testing audio players. These include audio files in AIFF, MP3, WAV, M4A, Ogg and FLAC format. The Touchbook played all of them fine. I've also recently added some high-definition FLAC files to my test suite. These files include ones at the following bit/kHz combinations: 24/88, 24/176.4 and 24/192, with anywhere from two to six channels of audio. This is an unfair test, especially because ALSA down-sampled the dual-channel files to 48KHz and because the speakers on the Touchbook aren't anywhere close to being audiophile quality. However, I was impressed that the Touchbook actually was able to play the files. The only time it obviously messed up was with my surround-sound test file, which has someone saying “left”, “right”, “center”, “back” and so on. Not only was the audio present only for the “left” and “right” portions of the test, but they also were switched so that they were coming from the wrong sides—not a big deal but interesting. And, for those who want to standardize their music libraries on a single format, the Touchbook should be able to play them, even if the format is high-definition FLAC.
Finally, the Touchbook has an annoying habit of going to sleep after letting it sit for a minute or so. Sometimes I don't even have to let it sit, it will just go to sleep while I'm typing—at least, I think it's sleeping. The screen turns off, and I can press the power button once and then count to ten, and the screen will come back on. This happens even when the Touchbook is plugged in. It's annoying.
In the final analysis, I like the hardware much more than I like the software, and I like the Touchbook's potential more than I like its current state. If you just want a Netbook that works, stay away for now. If, however, you like tinkering and don't mind a bumpy road, there's a lot to like.
Resources
Always Innovating: alwaysinnovating.com
BeagleBoard: www.beagleboard.org
Re-install Instructions: www.alwaysinnovating.com/wiki/index.php/Reinstall_OS
Big Buck Bunny: www.bigbuckbunny.org
Daniel Bartholomew lives with his wife and children in North Carolina. His on-line home is at daniel-bartholomew.com.

