
Mobile IPv6 with Linux
Free software is freedom, and so is mobility. In an age of embedded devices, nomadic users and omnipresent wireless connectivity, augmenting the venerable Internet Protocol (IP) with movement awareness and adaptability is due. IP's founding architects designed it with the assumption that the Internet node is static. This simplified the design by enabling a single field, the IP address, to signify both location and identity. A sending machine refers to a receiving one by the IP address (the identification role), and routers in the network use the IP address to direct traffic to the right path (the topological role). In this age of portability and nomadicity, this conflation of functions introduces a contradiction. For routing to do its job, the address needs to change according to the location; for the address to be used as an identifier, it must remain fixed.
Mobile IP (MIP), an extension of IP, provides a solution for that problem. The Internet Engineering Task Force (IETF) has been actively developing MIP for both IPv4 and IPv6 since the 1990s. The Mobile IPv6 (MIPv6) standard advanced from draft status to Proposed Standard (PS) status in 2004. Since then, optimizing and securing MIPv6 has become an active standardization and development area. A cost-effective, flexible and insightful vehicle for getting hands-on experience with MIPv6 is to experiment with the Mobile IPv6 for Linux (MIPL) package that the Helsinki University of Technology (HUT) has been developing since 1999.
The purpose of this article is to get you, the brave roamer, primed in MIPv6 by experimenting with MIPL. It assumes basic understanding of IPv6 and wireless LAN networking, and it consists of two parts: the first introduces MIPv6, and the second introduces MIPL.
IP mobility means the ability to handle movement gracefully. Movement, in the context of MIP, is an event or an operation that causes a machine to change its IP address. It is a movement from one IP subnet to another. Physical movement could cause it, but that isn't the only way a machine could “move” in the context of MIP. At the same time, physical movement doesn't necessarily translate to a network layer movement. Movement within a single wireless cell, for example, doesn't cause a subnet change and, thus, isn't movement from MIP's perspective. Movement is problematic for traditional IP. It forces a machine to change its IP address so as to belong to the new subnet to which it has just moved. Movement changes the machine's identification. It tears down TCP connections, such as Web-browsing sessions, because the IP address is one of the parameters that identifies a TCP connection. This makes for a rough roaming experience, as sessions have to be re-established each time a handover happens.
MIP deals with movement by decoupling identity from location. MIP provides each Mobile Node (MN) with two addresses: a permanent (long-term) address that embodies identity, called the Home Address (HoA), and a temporary (short-term) address that embodies location, called the Care-of Address (CoA). The HoA remains fixed, while the CoA freely changes according to the location of the node. MIP provides a mechanism to map between the two addresses dynamically. A moving machine (Mobile Node) changes its CoA each time it moves from one subnet to another, but it maintains its HoA and uses it to provide any node communicating with it, called a Correspondent Node (CN), with a stable destination address.
The mapping between the HoA and the CoA is called binding and is the central concept underlying MIP. The message that establishes the binding is called a Binding Update (BU). A table that tracks bindings is called a Binding Cache (BC). Sending Binding Updates and maintaining Binding Caches is the essence of MIP. All other aspects of the MIP protocol are to scale, secure, optimize and generally enhance the way bindings are established and used.
To provide a concrete description of MIP, let's look at the interactions between the participants in MIP in its most basic mode of operation (without Route Optimization). At its home network (home link), the MN uses its address (the HoA) in the standard fashion. MIPv6 kicks in upon movement detection. When the MN notices that its current default router has disappeared (it can no longer hear the router's advertisements) and that a new router is now chirping, it concludes that it has “moved” and uses the new prefix (subnet ID) to configure a new address (a new CoA) that belongs to the new subnet. It then sends a BU to a special router on the home link, called the Home Agent (HA), telling it that the HoA it “owns” is now bound to that new CoA. The HA records the mapping between the HoA and the CoA in its BC. Adding an entry to the BC is called registration. Traffic destined to the HoA, from any CN on the Internet, is routed to the home network because the HoA topologically belongs to it. There, the HA intercepts it and tunnels it to the MN's CoA address registered in the BC. Return traffic is reverse tunneled from the MN back to the HA and then sent from the HA to the CN. This way, the MN becomes always addressable by its HoA.
MIPL consists of two components: a kernel-space component, in the form of a kernel patch, and a user-space component, in the form of a Mobility Dæmon (mip6d). The dæmon implements most of the functionality. It discovers location, detects movement, sends and processes BUs and maintains the BC. The MIPL patch provides the kernel support required for the dæmon to perform those functions. The MIPL patch adds, for example, support for the Mobility Header protocol (MH), which is the IPv6 extension header that transports BUs and Binding Acknowledgments (BAs) and other binding-related messages. In addition to the MIPL package, we'll need to install the Router Advertisement Dæmon (radvd), as MIPv6 relies on the auto-configuration provided by router advertisements to detect movement and configure CoA addresses among other mobility-related tasks.
To explore the basic operation of MIPv6, let's use MIPL to create a simple MIP network consisting of two MIPL-patched Linux machines: a router, called denali, and a laptop, called raven. The laptop is a typical x86 machine that has a single 802.11b wireless interface and will be our MN. The router is a fanless, headless, single-board computer (Soekris Net4521) that has two 802.11b wireless interfaces, each hosting a different wireless network (ESS/Extended Service Set) and a different subnet. One router interface will be acting as the HA, and the other will be acting as a visited (foreign) network. Figure 1 shows the two machines used, and Figure 2 shows the logical setup.

Figure 1. Mobile Node Laptop and Its Home Agent on Top of It
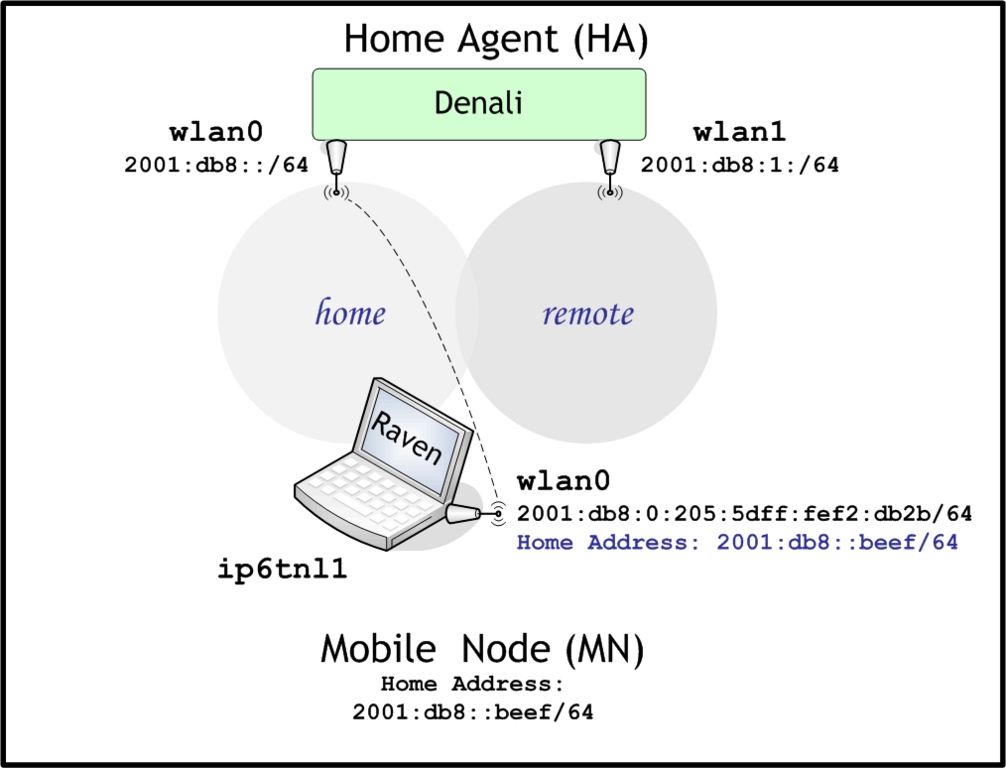
Figure 2. The MN on the Home Link (before Moving)
For simplicity, let's leave out advanced configurations, such as IP Security (IPsec) and Route Optimization (RO), and establish only the most basic MIP setup. We'll not use a standalone CN.
Installing the kernel part of MIPL for both the HA and the MN is exactly the same. First, download the kernel source tree against which the latest MIPL patch was taken (2.6.16, in my case), and patch it with the MIPL patch (version 2.0.2, in my case). Configure the kernel with the features needed for each machine, ensuring that the following configuration features are included (the script chkconf_kernel.sh, included in the MIPL user space tarball, can do the checking for you):
NET_KEY, NET_KEY_MIGRATE, XFRM and XFRM_USER XFRM_ENHANCEMENT: those add Internet Key Exchange (IKE) support that is needed for dynamically configuring IPsec. IPsec can be used optionally to secure MIPv6.
IPV6_MIP6: this adds support for the Mobility Header (MH) protocol and the other IPv6 protocol extension headers MIPv6 demands.
IPV6_ADVANCED_ROUTER: this enables the selection of advanced routing capabilities, such as policy routing.
IPV6_MULTIPLE_TABLES: this adds support for policy routing, an advanced routing feature that enables routing based on fields other than the destination address.
IPV6_SUBTREES: this adds source routing support, which is needed for sending traffic directly to the Mobile Node (without passing through the Home Network) when MIP is operating the Route Optimization (RO) mode.
IPV6_TUNNEL: IPv6 in IPv6 tunnel, which is needed for the HA to MN communication.
Build, install and reboot into the new kernel:
[raven]# wget http://www.kernel.org/pub/linux/kernel/v2.6/linux-2.6.16.tar.bz2 && tar -jxf linux-2.6.16.tar.bz2 && gzip -d mipv6-2.0.2-linux-2.6.16.patch.gz && cd linux-2.6.16 && patch -p1 < ../mipv6-2.0.2-linux-2.6.16.patch && make menuconfig [raven]# make && make install
To build the Mobility Dæmon, follow the steps you would do for any autotools built package: unzip, untar, cd to the directory of the package, ./configure, make and then make install (read the included INSTALL document for the details). Follow the same procedure for building and installing the Router Advertisement Dæmon, radvd. With that finished, you should have both MIPL components (kernel and user-space) and radvd installed, and you now are ready to start configuring.
To start off simply, let's begin without Route Optimization (RO), without IPsec and with a manually configured HA address in the MN. Once we have the basic setup working, we can enhance and expand it incrementally. Keep in mind that in the real world, like on the Internet or in enterprise networks, RO and IPsec are essential. In production networks, you also might desire other extensions, such as Fast Mobile IPv6 (FMIPv6) or Hierarchical Mobile IPv6 (HMIPv6), although those aren't implemented by MIPL.
Let's configure local parameters first, then Layer 2 parameters and finally Layer 3 parameters.
First, let's do the Home Agent configuration (denali), Host State (sysctl). At the outset, we need to put the HA in the right state of mind and configure the HA machine to operate as a router, so we need to turn on packet forwarding. We'll do this by setting the variable /proc/sys/net/ipv6/conf/all/forwarding, using one of the following two commands:
[denali]# echo "1" > /proc/sys/net/ipv6/conf/all/forwarding [denali]# sysctl -w net.ipv6.conf.all.forwarding=1
You could make those settings permanent across reboots by editing /etc/sysctl.conf.
Now, let's configure Layer 2 (the Data Link Layer) parameters (Listing 1). We'll assign each wireless interface a different wireless network ID (ESSID) and sufficiently space their frequency channels apart to avoid inter-cell interference.
Listing 1. Configuring the Data Link Layer—Home Agent
[denali]# iwconfig wlan0 essid "home" channel 3
[denali]# iwconfig wlan0 essid "remote" channel 8
[denali]# iwconfig wlan0 ; iwconfig wlan1
wlan0 IEEE 802.11b ESSID:"home"
Mode:Master Frequency:2.422 GHz Access Point: 00:02:6F:06:0B:CF
Bit Rate:11 Mb/s Sensitivity=1/3
Retry min limit:8 RTS thr:off Fragment thr:off
Encryption key:off
Power Management:off
Link Quality:0 Signal level:0 Noise level:0
Rx invalid nwid:0 Rx invalid crypt:0 Rx invalid frag:0
Tx excessive retries:97 Invalid misc:342 Missed beacon:0
wlan1 IEEE 802.11b ESSID:"remote"
Mode:Master Frequency:2.447 GHz Access Point: 00:02:6F:06:46:10
Bit Rate:11 Mb/s Sensitivity=1/3
Retry min limit:8 RTS thr:off Fragment thr:off
Encryption key:off
Power Management:off
Link Quality:0 Signal level:0 Noise level:0
Rx invalid nwid:0 Rx invalid crypt:0 Rx invalid frag:0
Tx excessive retries:10 Invalid misc:6767 Missed beacon:0
Our next step is to configure the Layer 3 (Network Layer) parameters. This includes addressing, configuring the Router Advertisement Dæmon and configuring the Mobility Dæmon. To configure addressing, use the commands shown in Listing 2.
Listing 2. Configuring the Network Layer Parameters—Home Agent
[denali]# ifconfig wlan0 inet6 add 2001:db8::/64
[denali]# ifconfig wlan1 inet6 add 2001:db8:1::/64
[denali]# ifconfig wlan0 ; ifconfig wlan1
wlan0 Link encap:Ethernet HWaddr 00:02:6F:06:0B:CF
inet6 addr: 2001:db8::/64 Scope:Global
inet6 addr: fe80::202:6fff:fe06:bcf/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:205 overruns:0 frame:0
TX packets:204 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:27604 (26.9 Kb)
Interrupt:11 Base address:0x100
wlan1 Link encap:Ethernet HWaddr 00:02:6F:06:46:10
inet6 addr: 2001:db8:1::/64 Scope:Global
inet6 addr: fe80::202:6fff:fe06:4610/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:64 overruns:0 frame:0
TX packets:207 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:28068 (27.4 Kb)
Interrupt:11 Base address:0x140
To configure router advertisements, edit the /etc/radvd.conf file, as shown here:
interface wlan0
{
AdvSendAdvert on;
AdvIntervalOpt on;
MaxRtrAdvInterval 10;
MinRtrAdvInterval 1;
MinDelayBetweenRAs 1;
AdvHomeAgentFlag on;
prefix 2001:db8::/64
{
AdvOnLink on;
AdvAutonomous on;
AdvRouterAddr on;
};
};
interface wlan1
{
AdvSendAdvert on;
AdvIntervalOpt on;
MaxRtrAdvInterval 10;
MinRtrAdvInterval 1;
MinDelayBetweenRAs 1;
AdvHomeAgentFlag off;
prefix 2001:db8:1::/64
{
AdvOnLink on;
AdvAutonomous on;
AdvRouterAddr on;
};
};
In the stanza pertaining to wlan0, you can see that we have enabled router advertisements on the interface by setting AdvSendAdvert. We also have configured the interface to operate as an HA by setting AdvHomeAgentFlag. The other wireless interface, wlan1, is configured similarly, except that AdvHomeAgentFlag isn't set. Note that the more frequent the router advertisements are, the faster movement can be detected but they generate more overhead.
Now launch the router advertisement dæmon, radvd:
[denali]# radvd -C /etc/radvd.conf
To configure the Mobility Dæmon, we need to edit the /etc/mip6d.conf file, as follows:
NodeConfig HA; ## If set to > 0, will not detach from tty DebugLevel 0; ## List of interfaces where we serve as Home Agent Interface "wlan0"; UseMnHaIPsec disabled;
Notice that we merely indicated that the machine is an HA and specified the interface that will be operating as an HA. By launching the Mobility Dæmon, the router is set to fulfill its duty as a faithful HA:
[denali]# mip6d -c /etc/mip6d -d 7
Now, let's move on to the Mobile Node Configuration (raven), Host State (sysctl). Just as with the HA, we'll start by establishing the mindset of the MN. First, we must configure the MN to accept Router Advertisements (RAs) to be able to configure a CoA and discover and track default routers on the link automatically:
[raven]# echo "1" > /proc/sys/net/ipv6/conf/all/accept_ra [raven]# sysctl -w net.ipv6.conf.all.accept_ra=1
To make the changes permanent across reboots, edit /etc/sysctl.conf.
Next, let's configure Layer 2 parameters. We'll configure the MN as a wireless client (a managed wireless node) of the Home network:
[raven]# iwconfig wlan0 mode managed essid "home"
[raven]# iwconfig wlan0
wlan0 IEEE 802.11b ESSID:"home"
Mode:Managed Frequency:2.422 GHz Access Point:
00:02:6F:06:0B:CF
Bit Rate:11 Mb/s Sensitivity=1/3
Retry min limit:8 RTS thr:off Fragment thr:off
Encryption key:off
Power Management:off
Link Quality=48/92 Signal level=-63 dBm Noise level=-100 dBm
Rx invalid nwid:0 Rx invalid crypt:0 Rx invalid frag:0
Tx excessive retries:0 Invalid misc:175 Missed beacon:0
And, finally, let's configure Layer 3 parameters. We'll start by assigning the HoA to the wireless interface:
[raven]# ifconfig wlan0 inet6 add 2001:db8::beef/64
[raven]# ifconfig wlan0 ; ifconfig ip6tnl1
wlan0 Link encap:Ethernet HWaddr 00:05:5D:F2:DB:2B
inet6 addr: 2001:db8::beef/64 Scope:Global
inet6 addr: fe80::205:5dff:fef2:db2b/64 Scope:Link
inet6 addr: 2001:db8::205:5dff:fef2:db2b/64 Scope:Global
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:141 errors:0 dropped:0 overruns:0 frame:0
TX packets:51 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:16094 (15.7 Kb) TX bytes:5592 (5.4 Kb)
Interrupt:17 Base address:0x2100
ip6tnl1 Link encap:UNSPEC
↪HWaddr 20-01-0D-B8-00-00-00-00-00-00-00-00-00-00-00-00
inet6 addr: fe80::205:5dff:fef2:db2b/64 Scope:Link
UP POINTOPOINT RUNNING NOARP MTU:1460 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
On the MN, an automatically created tunnel interface, called ip6tnl1 (IPv6 Tunnel 1), represents the tunneling process described above. This interface claims no global addresses when the MN is in the Home network and assumes the HoA when the MN is away.
The primary mobility configuration parameters are the Home Address (HoA) and the Home Agent (HA) address. To configure them, we need to edit the /etc/mip6d.conf file as follows:
NodeConfig MN;
DebugLevel 7;
UseMnHaIPsec disabled;
DoRouteOptimizationMN disabled;
DoRouteOptimizationCN disabled;
Interface "wlan0";
MnHomeLink "wlan0" {
HomeAddress 2001:db8::beef/64;
HomeAgentAddress 2001:db8::;
Now the scene is complete, and we can start experimenting with mobility. Before we start, remember the following about MIP: movement detection is the trigger; binding updating (registration) is the action. We'll start by letting the MN move, then check whether movement was detected. Upon witnessing movement detection, we'll check whether a BU was established successfully. Figure 2 shows the network's state before moving. To simulate movement, we use iwconfig to switch the MN's wireless interface from one ESS (wireless cell) to another:
[raven]# iwconfig wlan0 essid "remote"
Upon moving, the wireless interface should acquire a new address, and a new default gateway should appear (Listing 3).
Listing 3. Moving
... Before Moving (At the Home Network) ... [raven]# iwconfig wlan0 | grep ESSID wlan0 IEEE 802.11b ESSID:"home" [raven]# ifconfig wlan0 | grep inet6 inet6 addr: 2001:db8::beef/64 Scope:Global inet6 addr: fe80::205:5dff:fef2:db2b/64 Scope:Link inet6 addr: 2001:db8::205:5dff:fef2:db2b/64 Scope:Global [raven]# ifconfig ip6tnl1 | grep inet6 inet6 addr: fe80::205:5dff:fef2:db2b/64 Scope:Link [raven]# route -A inet6 | grep ::/0 ::/0 fe80::202:6fff:fe06:bcf UGDA 1024 0 0 wlan0 ... Triggering Movement ... [raven]# iwconfig wlan0 essid remote ... After Moving (At the Foreign Network) ... [raven]# iwconfig wlan0 | grep ESSID wlan0 IEEE 802.11b ESSID:"remote" [raven]# ifconfig wlan0 | grep inet6 inet6 addr: 2001:db8:1:0:205:5dff:fef2:db2b/64 Scope:Global inet6 addr: fe80::205:5dff:fef2:db2b/64 Scope:Link [raven]# ifconfig ip6tnl1 | grep inet6 inet6 addr: 2001:db8::beef/128 Scope:Global inet6 addr: fe80::205:5dff:fef2:db2b/64 Scope:Link [raven]# route -A inet6 | grep ::/0 ::/0 :: U 128 0 0 ip6tnl1 ::/0 fe80::202:6fff:fe06:4610 UGDA 1024 4 2 wlan0 [raven]#
Using a packet capturing tool (sniffer), such as tcpdump, we should see a different router appearing on the link. The Mobility Dæmon log messages should indicate movement detection (md in the logs stands for movement detection). Now that the MN has detected movement and acquired a new CoA address, it should send a BU to its HA. A sniffer should be able to display the BU message as:
IP6 2001:db8:1:0:205:5dff:fef2:db2b > 2001:db8::: ↪DSTOPT mobility: BU seq#=54814 AH lifetime=262140 IP6 2001:db8:: > 2001:db8:1:0:205:5dff:fef2:db2b: srcrt ↪(len=2, type=2, segleft=1, [0]2001:db8::beef) ↪mobility: BA status=0 seq#=54814 lifetime=262140
In addition, the Mobility Dæmon should have a BU List Entry (BULE) that shows the HoA, CoA and HA addresses:
[raven]# telnet localhost 7777 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. mip6d> bul mip6d> bul == BUL_ENTRY == Home address 2001:db8:0:0:0:0:0:beef Care-of address 2001:db8:1:0:205:5dff:fef2:db2b CN address 2001:db8:0:0:0:0:0:0 lifetime = 262140, delay = 249033000 flags: IP6_MH_BU_HOME IP6_MH_BU_ACK ack ready dev wlan0 last_coa 2001:db8:1:0:205:5dff:fef2:db2b lifetime 262136 / 262140 seq 19428 resend 0 delay 249033(after 249030s) expires 262136 mps 2 / 3 mip6d>
We can see whether the BU was received and accepted by looking at the HA's Mobility Dæmon log messages and by displaying the HA's BC:
[denali]# telnet localhost 7777 mip6d> bc mip6d> bc hoa 2001:db8:0:0:0:0:0:beef status registered coa 2001:db8:1:0:205:5dff:fef2:db2b flags AH-- local 2001:db8:0:0:0:0:0:0 lifetime 262068 / 262140 seq 19429 unreach 0 ↪mpa 13133 / 13221 retry 0 mip6d>
As shown above, the Mobility Dæmon provides a virtual terminal interface to its internal data structures that you can access by a establishing a Telnet session to port 7777. Figure 3 shows the network's state after moving.
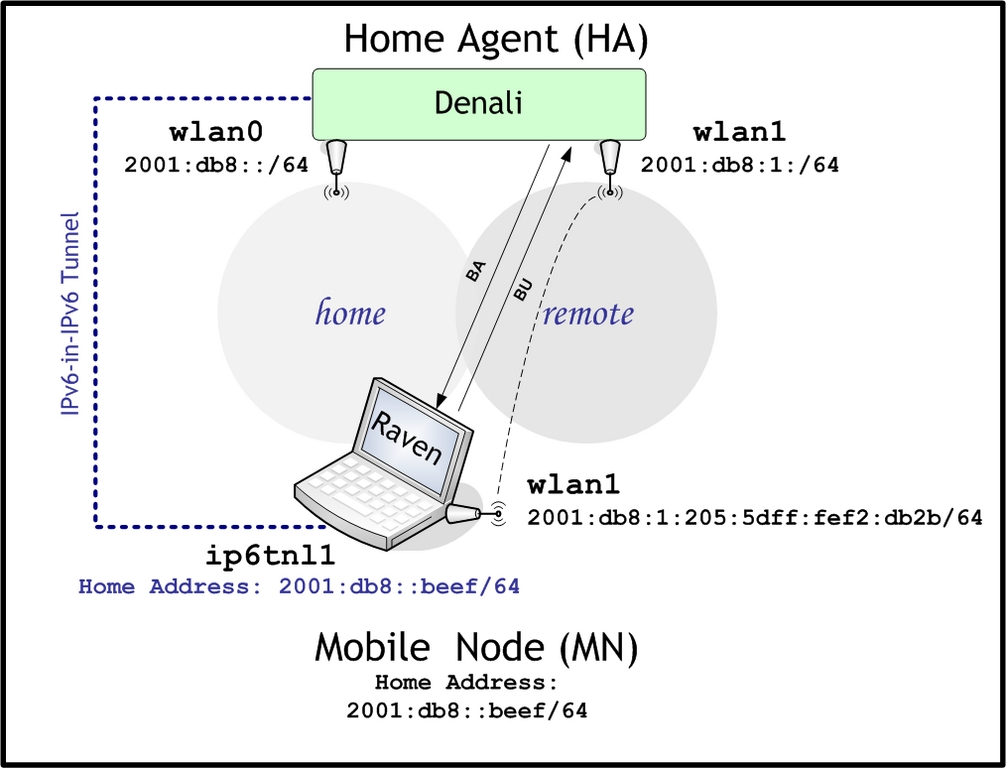
Figure 3. The MN on the Remote Link (after Moving)
We can't conclude a networking experiment without some action from our old crony ping. From the MN, we'll start by sending ping requests to the HA interface, while the MN is on the home link. We'll then move and see what happens. This exercise is shown as follows:
[raven]# ping6 2001:db8:: 64 bytes from 2001:db8::: icmp_seq=7 ttl=64 time=3.72 ms 64 bytes from 2001:db8::: icmp_seq=8 ttl=64 time=3.70 ms ping: sendmsg: Invalid argument ping: sendmsg: Invalid argument ping: sendmsg: Invalid argument ping: sendmsg: Operation not permitted 64 bytes from 2001:db8::: icmp_seq=13 ttl=63 time=142 ms 64 bytes from 2001:db8::: icmp_seq=14 ttl=63 time=122 ms
Note that in responding to ping requests, the HA interface is actually acting as a CN. Note how, upon the handover, the MN loses connectivity for some time, called the handover latency, and then re-establishes it. Note also how the delay increases tremendously as the MN moves.
A more interesting test is to use a program that sends video like VLC or GnomeMeeting and visually assess how smooth the handover is. Although the ultimate goal of MIPv6 is to achieve smooth and lossless handover, in reality, there is a blackout period during which packets are lost or delayed. Much of the effort put into developing and standardizing MIPv6 is to enhance the smoothness of the handover and ultimately achieve seamless handover. As with any other technology, realizing the limitations is as crucial as recognizing the value.
The Internet Protocol, merged nets into the global metanet we called the Internet. IP provided connectivity that is independent on the underlying hardware and the served applications. The homogeneous addressing of IP and its simplicity enabled it to scale. MIP's goal is to bring to mobility the merits IP brought to connectivity. This means mobility that can scale to the size of the Internet, is application-independent and is available across heterogeneous wired and wireless access technologies. MIPL provides a free and flexible platform for you to participate in pursuing that vision. Happy and seamless roaming!
Resources
RFC 3775, Mobility Support in IPv6 (the Base MIPv6 Standard): www.ietf.org/rfc/rfc3775.txt
RFC 3849, IPv6 Address Prefix Reserved for Documentation: www.ietf.org/rfc/rfc3849.txt
MIPL Home Page: www.mobile-ipv6.org
Linux MIPv6 HOWTO: tldp.org/HOWTO/Mobile-IPv6-HOWTO
Peter Bieringer's Linux IPv6 HOWTO: ldp.linux.no/HOWTO/Linux_IPv6-HOWTO
Linux IPv6 Router Advertisement Dæmon (radvd): www.litech.org/radvd
Updated, but Not Finalized, Linux MIPv6 HOWTO: gnist.org/~lars/doc/Mobile-IPv6-HOWTO/Mobile-IPv6-HOWTO.html
Linux Kernel Archives: www.kernel.org
Sysctl Documentation: /usr/src/linux-2.6.16/Documentation/networking/ip-sysctl.txt in the kernel source tree
Salah M. S. Al-Buraiky is a communication engineer working for the Data Network Engineering Division (DNED) of Saudi Aramco. His interests include UNIX systems and datagram networks. He is particularly interested in “beyond connectivity services”, such as multicast, mobility, quality of service and IP security. He welcomes your comments at salah.buraiky.1@aramco.com.
