
IPv4 Anycast with Linux and Quagga
“DNS is down and nothing is working!” is not something anyone ever wants to hear at 3am. Virtually every service on a modern network depends on DNS to function. When DNS goes down, you can't send mail, you can't get to the Web, you can't do much—hopefully, your coffeemaker is not Web-enabled! Administrators do a lot of things to mitigate this risk. The traditional safeguard is to establish multiple DNS servers for a given site. Each DNS client on the network is configured with each of those servers' IP addresses. The chances of all of those servers failing in a catastrophic way are fairly small, so you have a margin of safety.
On the other hand, many stub resolvers will take only two DNS servers, making it nearly impossible to have any meaningful geographical dispersion in your DNS topology. DNS stub resolvers generally use the first of two configured DNS servers exclusively. Consequently, you end up with one server taking the entire query load and one idling, waiting for a failure. Not optimal, but hey, that's the price of redundancy...right? It doesn't have to be.
DNS redundancy and failover is a classic use case for anycast. Anycast is the concept of taking one IP address and sharing it between multiple servers, each unaware of the others. The DNS root nameservers make extensive use of anycast. There are currently 16 root nameserver IP addresses, only eight of which make use of anycast. There are 167 servers that respond to those 16 IP addresses.
Of course, anycast is not limited to DNS. It can be used to provide redundancy and failover for any number of stateless protocols and applications. Anycast might sound a little like multicast, but aside from the one-to-many, IP-to-endpoint relationship, they have very little in common. Multicast takes packets from one sender and delivers them to multiple endpoints, all of which subscribe to a single multicast address using a number of multicast-specific routing technologies. Anycast takes packets from one sender and delivers those packets to the “closest” of a number of possible endpoints using nothing more than standard unicast routing.
Let's start with some terminology:
An endpoint (also known as a node) is a server that responds to an anycast address and, by extension, provides services on that address.
An anycast address is an IP address that has multiple endpoints associated with it. Anycast addresses can be from any part of the normal IPv4 address space.
A service address is a unique IP address on a physical device on the system. Service addresses are used for administrative or monitoring access to anycast endpoints.
IGP anycast refers to an anycast scheme confined to a single network (typically a larger network with multiple physical sites). I cover IGP anycast in this article.
BGP anycast refers to an anycast scheme that spans multiple networks and can span the entire Internet. The DNS root servers use BGP anycast.
Anycast endpoints participate in whatever internal routing protocol is being run on your network. All endpoints for a given anycast IP advertise a host route (also known as a /32) for the anycast IP to the router. In other words, each endpoint announces that the anycast IP can be reached through it. Your routers will see the advertisements coming from the various servers and determine the best path to that IP address. Therein lies the magic. Because the IP address is advertised from multiple locations, your router ends up choosing the best path to that IP address, according to the metric in use by that routing protocol—meaning either the path with the fewest hops (RIP), the highest bandwidth path (OSPF) or some other measurement of network goodness. When you send a request to an anycast IP address, it will be routed to the single server with the best metric according to the routers between you and the server.
What if that server fails? If the host fails, it will stop sending out routing advertisements. The routing protocol will notice and remove that route. Traffic then will flow along the next best path. Now, the fact that the host is up does not necessarily mean that the service is up. For that, you need some sort of service monitoring in place and the capability to remove a host from the anycast scheme on the fly.
Naturally, myriad other details need to be worked out when designing an anycast scheme. The general concept is pretty simple, and small implementations are easy to set up. However, no matter what size implementation you're dealing with, proper IP address architecture is a must. Your anycast address should be on its own subnet, separate from any other existing subnets. The anycast subnet must never, ever, be included in a summary.
Many projects provide routing protocol dæmons for Linux, any number of which would be usable for this scenario. For this article, I use Quagga, which is a fork of GNU Zebra. Quagga is available both on the install media and from the standard package repositories of pretty much every enterprise-oriented Linux distribution.
For the following examples, I also use a network populated with Cisco routers, running OSPF version 2, for IPv4. Quagga also supports BGP, RIP, RIPng and OSPFv3. The remainder of this article assumes at least a basic familiarity with OSPF theory and configuration. (See Resources for links to basic primers.) Cisco also publishes a ton of very good reference material (again, see Resources). I cover the required configuration on the router side, but not in extensive detail.
Now, let's get down to the good stuff: setting up Quagga on Linux. To begin, I describe how to install Quagga, set up a loopback alias to hold the anycast IP address and configure Quagga to talk to your local routers. Then, I go over a few optional configuration extras.
First, install Quagga. For example, on Red Hat Enterprise Linux (RHEL), run yum install quagga. Substitute the appropriate package-management command for your distribution, as needed.
Next, create a loopback interface alias on the system. Configure the anycast IP address on this loopback interface. Using a loopback interface alias instead of a physical interface alias allows you to do a number of cool things. You could segment your service traffic from your administrative traffic. You could add some redundancy by responding to the anycast address on two physical interfaces, each attached to a different router or switch (although I won't go into that kind of configuration here). You also could take down the anycast interface (and, therefore, remove that interface from the anycast scheme) without affecting your ability to administer the system remotely. On RHEL, the interface configuration files are located in /etc/sysconfig/networking-scripts/. Create a file in that directory named ifcfg-lo:0 with the following contents:
# cat /etc/sysconfig/networking-scripts/ifcfg-lo:0 DEVICE=lo:0 IPADDR=10.0.0.1 NETMASK=255.255.255.255 BOOTPROTO=none ONBOOT=yes
That file's format is fairly self-explanatory. You can control the lo:0 interface with your normal interface control commands (ifup, ifdown, ifconfig and so on).
Some versions of Fedora use NetworkManager to control eth0 by default. This may cause strange things to happen when you try to bring up a loopback alias. If that happens to you, add the line NM_CONTROLLED=no to /etc/sysconfig/networking-scripts/ifcfg-eth0, and restart your network. At this point, you should be able to bring up your new interface with ifup lo:0.
Now, you need to configure Quagga. By default, the Quagga configuration files are in /etc/quagga and /etc/sysconfig/quagga. There are a number of example configuration files in /etc/quagga: one for each routing protocol that Quagga supports; one for zebra, the main process; and one for the vtysh configuration. We primarily are interested in the ospfd.config and zebra.config files. The syntax in those files is similar to the standard Cisco configuration syntax, but with important differences. Also note that, by default, all routing processes bind to a dæmon-specific port on 127.0.0.1. If you configure a password for that routing process and Telnet to that port, you can monitor and configure the process on the fly using the same Cisco-like syntax. In these files, ! is the comment character:
# cat zebra.conf hostname Endpoint1 ! interface eth0 ip address 10.0.1.2/24 ! interface lo:0 ip address 10.0.0.1/32
The above file is pretty quick and easy. It contains the IP addresses and netmasks of the physical adapters and the loopback adapter that has the anycast address. This file is much more complex:
# cat ospfd.conf hostname Endpoint1 ! interface eth0 ip ospf authentication message-digest ip ospf message-digest-key 1 md5 foobar ip ospf priority 0 ! router ospf log-adjacency-changes ospf router-id 10.0.1.2 area 10.0.1.2 authentication message-digest area 10.0.1.2 nssa network 10.0.1.0/24 area 10.0.1.2 redistribute connected metric-type 1 distribute-list ANYCAST out connected ! access-list ANYCAST permit 10.0.0.1/32
Let's go over the above section by section, starting with the following:
interface eth0 ip ospf authentication message-digest ip ospf message-digest-key 1 md5 foobar
The first thing in the file is the OSPF MD5 authentication configuration. Always configure MD5 authentication on your OSPF sessions. Replace foobar with the appropriate key for your environment.
Next, we have:
ip ospf priority 0
Also set the OSPF priority to 0, which prevents the server from being elected as the Designated Router on that link.
Next come the router configuration directives:
router ospf log-adjacency-changes
log-adjacency-changes is a great configuration directive that gives you more details when there is a change in neighbor relationships between your server and any other OSPF-speaking device.
Then:
ospf router-id 10.0.1.2
Here the router ID is set to the server's service address. Router IDs must be unique within the routing domain.
We then configure this server to be in its own Not So Stubby Area (NSSA):
area 10.0.1.2 authentication message-digest area 10.0.1.2 nssa redistribute connected metric-type 1 distribute-list 5 out connected
NSSA areas are a form of stub area that limits the routes sent into the area to summary routes, but still allows external routes to come from that area. We need to allow external routes because we advertise our anycast IP address by redistributing our connected interfaces and running that through a distribute list to confine our advertised interfaces to just the anycast IP address. However, we don't want this server to have to deal with all the routes in area 0.0.0.0.
The following statement selects the interfaces that will participate in OSPF:
network 10.0.1.0/24 area 10.0.1.2
We want our eth0 interface to participate in OSPF, so we specify 10.0.1.0/24, and we put those interfaces in area 10.0.1.1.
The following line defines the access list that will allow route advertisements out:
access-list ANYCAST permit 10.0.0.1/32
Now that Quagga is configured, we need to open up the proper IP protocol number on our firewall. OSPF uses protocol number 89. The details of opening that particular protocol number will vary significantly with the firewall configuration you're using.
In general, you'll use a command like this:
# iptables -I INPUT -p 89 -j ALLOW
which inserts the rule permitting IP protocol 89 at the start of the INPUT chain. That command will work with most any standard firewall configuration. After all of this, you finally can get Quagga going. Start it with service zebra start and service ospfd start. Your system now should be participating in your OSPF routing scheme.
You can confirm that with a quick look at your router's routing table:
R1>show ip route 10.0.0.1
Routing entry for 10.0.0.1/32
Known via "ospf 1", distance 110, metric 21, type NSSA extern 1
Last update from 10.0.1.2 on FastEthernet0/0, 00:00:14 ago
Routing Descriptor Blocks:
* 10.0.1.2, from 10.0.1.2, 00:00:14 ago, via FastEthernet0/0
Route metric is 21, traffic share count is 1
To enable remote administration, you must set a password in ospfd.conf as follows:
password YOUR-PASSWORD enable password YOUR-ENABLE-PASSWORD
If you are feeling paranoid about your server establishing neighbor relationships with devices other than your router, you can disable OSPF automatic neighbor discovery on your server with the following additional commands in ospfd.conf:
interface eth0 ip ospf network non-broadcast router ospf neighbor ROUTER-ID-OF-ROUTER
This configuration has each endpoint in its own OSPF NSSA area. You just as easily could have the endpoints become part of whatever area is already in existence, as long as that area allows external routes. Having each server in its own area gives you a little more control over what kind of routes propagate to and from each endpoint. It is a bit more work, both initially and when you move a server to a different router. It also means your servers have to be able to connect directly to an ABR with access to area 0, which may or may not be possible in your network.
Anycast with one endpoint is fairly useless, so let's take a look at a simple deployment scenario. Each endpoint is configured exactly like the endpoint we just configured, with the exception of the service address and the OSPF area number.
In this scenario, let's say we have anycast running between two sites (for instance, a main office and a satellite office) connected over a WAN. There is one anycast endpoint at each site. The main office is 10.0.1.0/24, the satellite office is 10.0.2.0/24, and our anycast address is 10.0.0.1, from our anycast subnet, 10.0.0.0/25 (Figure 1).
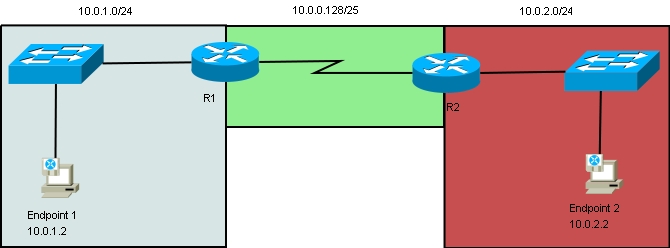
Figure 1. Two-Site, Two-Server Environment
OSPF on R1 is configured as follows:
router ospf 1 log-adjacency-changes network 10.0.1.0 0.0.0.255 area 10.0.1.2 network 10.0.0.128 0.0.0.128 area 0.0.0.0 area 10.0.1.2 nssa no-summary default-information-originate area 10.0.1.2 authentication message-digest area 0.0.0.0 authentication message-digest
OSPF on R2 is configured as follows:
router ospf 1
log-adjacency-changes
network 10.0.2.0 0.0.0.255 area 10.0.2.2
network 10.0.0.128 0.0.0.128 area 0.0.0.0
area 10.0.2.2 nssa no-summary default-information-originate
area 10.0.2.2 authentication message-digest
area 0.0.0.0 authentication message-digest
R1>show ip route 10.0.0.1
Routing entry for 10.0.0.1/32
Known via "ospf 1", distance 110, metric 21, type NSSA extern 1
Last update from 10.0.1.2 on FastEthernet0/0, 00:00:14 ago
Routing Descriptor Blocks:
* 10.0.1.2, from 10.0.1.2, 00:00:14 ago, via FastEthernet0/0
Route metric is 21, traffic share count is
R2>show ip route 10.0.0.1
Routing entry for 10.0.0.1/32
Known via "ospf 1", distance 110, metric 21, type NSSA extern 1
Last update from 10.0.2.2 on FastEthernet0/0, 00:05:07 ago
Routing Descriptor Blocks:
* 10.0.2.2, from 10.0.2.2, 00:05:07 ago, via FastEthernet0/0
Route metric is 21, traffic share count is 1
Traffic from each of the sites is flowing to the local anycast endpoint. Here's what happens if we take out the main office endpoint:
Endpoint1# ifdown lo:0
Endpoint1#
R1>show ip route 10.0.0.1
Routing entry for 10.0.0.1/32
Known via "ospf 1", distance 110, metric 85, type extern 1
Last update from 10.0.0.130 on Serial0/0, 00:00:21 ago
Routing Descriptor Blocks:
* 10.0.0.130, from 10.0.2.2, 00:00:21 ago, via Serial0/0
Route metric is 85, traffic share count is 1
R2>show ip route 10.0.0.1
Routing entry for 10.0.0.1/32
Known via "ospf 1", distance 110, metric 21, type NSSA extern 1
Last update from 10.0.2.2 on FastEthernet0/0, 00:05:07 ago
Routing Descriptor Blocks:
* 10.0.2.2, from 10.0.2.2, 00:05:07 ago, via FastEthernet0/0
Route metric is 21, traffic share count is 1
All traffic starts to flow to the remaining endpoint, as designed and desired.
As I mentioned previously, the fact that a host is up does not mean that the service that host provides is up. When a host running Quagga goes down, any routes that host inserted into OSPF will be withdrawn. We need to do the same thing when a service does down. Any piece of monitoring software that can run a handler script in response to a monitoring event can be used for this task. The basic idea is to execute a test against the anycast IP from each anycast endpoint. If a test fails, you need to run ifdown lo:0 on the failed endpoint. Quagga will detect the downed interface and withdraw the route to that interface from OSPF. Administrators then can fix the box at their leisure and place the box back into service with a simple ifup lo.
Application/Router Configuration Notes
1. Adjusting the cost of a link can be a great way to prepare an endpoint for removal gracefully. Using any other method, especially in a high-traffic environment, can result in dropped connections and other transient issues until OSPF reconverges. Setting the link cost very high before removal, on the other hand, avoids any transient problems during the brief reconvergence period. Once the endpoint in question is no longer receiving traffic, you can disable the anycast loopback and do whatever work needs to be done. Adjust the cost of a link on the router connected to your server with the following commands (in the example above that would be R1 or R2):
interface WHATEVER-INTERFACE-CONNECTS-THE-ROUTER-TO-QUAGGA ip ospf cost NUMBER
Replace {number} with some large number that is greater than the cost of the replacement anycast endpoint.
2. Make sure nonresponse traffic is not sourced from the anycast address. One example is in configuring DNS. You want DNS replies to come from the anycast IP address, but you do not want DNS zone transfers to come from or go to anycast IP addresses. In the case of a caching nameserver, you also don't want recursive queries originated from the server to be sourced from the anycast address.
3. Applications that maintain state in some way are not good candidates for anycast addressing, even if the underlying transport protocol is stateless. The exception to that rule would be if all the anycast endpoints got their application-level state information from the same place.
4. UDP is the de facto standard for the anycast transport-layer protocol. Use any other transport-layer protocol at your own risk. See Resources for a detailed review of issues associated with using other transport-layer protocols.
Anycast is a great technique to enhance the reliability and fault tolerance of applications and services on your network. When designing your anycast topology, keep several rules and guidelines in mind. I've shown a very basic use case and deployment of anycast here. You can take the same concepts covered in this article, along with a fair bit of networking knowledge, and scale them to a worldwide deployment. If you do it right, you can have redundancy without nearly as many idle machines sitting around.
Resources
root-servers.org: www.root-servers.org
OpenBGPD: www.openbgpd.org
GNU Zebra: www.zebra.org
“IP Routing Primer, Part One”: www.networkcomputing.com/netdesign/1122ipr.html
“Cisco administration 101: What you need to know about OSPF”: articles.techrepublic.com.com/5100-10878_11-6132046.html
“Open Shortest Path First (OSPF)”: www.cisco.com/en/US/docs/internetworking/technology/handbook/OSPF.html
“Architectural Considerations of IP Anycast”: tools.ietf.org/html/draft-mcpherson-anycast-arch-implications-00
Philip Martin has been working and playing with Linux for about ten years and is currently a Systems Engineer for a large on-line retailer. When he is not working with computers, he spends his days trying to be more like Alton Brown and in an ongoing quest to get invited to an Iron Chef America filming. He can be reached at phillip.martin@gmail.com.
