
Innovative Interfaces with Clutter
Meet one of the most revolutionary toolkits available for Linux: Clutter. Clutter is an OpenGL-based toolkit, described as an “open-source software library for creating fast, visually rich and animated graphical user interfaces”. Clutter provides a simple API for powerful three-dimensional and two-dimensional manipulation. Creating interactive games, 3-D media and animated applications for Linux systems with Clutter is cleaner, easier and quicker than coding an OpenGL application with more conventional methods.
Clutter comes with many built-in tools and effects. Rendering object rotation, scale, texture and opacity are built right in and can be accomplished with a few lines of code. Rendering and controlling the GStreamer multimedia API also is easy with an additional library. There even are Webkit bindings, so manipulating Web pages in a Clutter program is simple.
Clutter has been used in many successful applications and open-source projects. Take, for example, the open-source Elisa media center. Developed by Fluendo, Elisa is a 3-D media center—one of the most sophisticated alternatives to software such as Windows Media Center available for Linux. Elisa makes use of Clutter's animation and 3-D API in its elegant interface.
The Ubuntu Mobile Internet Device Edition, developed by the Ubuntu Mobile community, also uses Clutter for its main user interface. Additionally, the Moblin Project plans to use Clutter in its software platform. Clutter's use is widespread across Linux systems and is becoming more and more popular every day.
Figure 1. Elisa, Fluendo's media center application, utilizes Clutter's advanced library to add 3-D animation to its GUI.
Installing Clutter on Linux systems is extremely easy with the use of binary package managers. Install Clutter, the Cairo add-on, the GStreamer add-on and the Python bindings. Using your distribution's package manager, install the following packages: libClutter, libClutter-cairo, libClutter-gst and python-Clutter.
Different distributions will have different versions available, and it is recommended that you install the latest possible version. However, you need 0.8.0 or 0.8.2 of the libClutter packages to follow the examples and run the code given in this article. If the version number in your package manager is different from either 0.8.0 or 0.8.2, you should install Clutter from source. See Resources for the URL to Clutter's source files.
In this article, I'm using Clutter's Python bindings to work with Clutter. More can be done with Python in just a few lines of code, so using that language makes it easier to explore and understand Clutter. To test your install of Clutter, simply run Python and do the following:
import clutter
If you get a blank prompt back with no errors, the Clutter module was imported successfully, and you've installed python-Clutter correctly.
Now, let's start with a simple “Hello World!” Clutter application with Python. You probably should turn off any desktop effects or compositing window managers, such as Compiz Fusion. Most Linux video drivers will not allow multiple OpenGL or 3-D processes to run simultaneously with a compositing window manager, which includes Clutter, because of its 3-D capabilities.
What's Wrong with Compiz Fusion?
Compiz Fusion is an OpenGL compositing window manager, capable of delivering 3-D and smooth animation to the desktop. It is widespread on Linux desktops and is available on almost all modern Linux distributions. Often, Compiz Fusion is enabled by default.
However, Compiz Fusion does not play nice with Clutter. In fact, on almost all video cards, most OpenGL- or SDL-based applications are slow and prone to flickering if Compiz is running. Some of the programs affected include Google Earth, Blender and most 3-D games.
This is due to the X Window System's inability to render OpenGL applications along with a compositing window manager, such as Compiz Fusion, simultaneously on most video cards. However, DRI2 aims to fix this problem. DRI2 (Direct Rendering Infrastructure 2) will allow several OpenGL applications to run at once by directly rendering redirected windows. In time, DRI2 will ship along with most X.Org video drivers.
With the implementation of DRI2 in most video drivers, the X Window System finally will be able to handle OpenGL with a compositing manager. However, currently on most video cards and using most drivers, Clutter conflicts with Compiz Fusion.
To start the program, you need to import the Clutter module and define your main Class and an initialization function. Create a stage in the initialization function. The stage is the base of any Clutter interface. On the stage, objects called actors can be seen and manipulated. Clutter uses the term actors to describe any objects that exist on the stage.
The sample program is shown in Listing 1, and the output window is shown in Figure 2.
After creating the stage, set the stage's properties and some properties of the window containing it.
Set color of the stage to black by accessing Clutter's predefined colors using Clutter.color_parse().
Next, set the size of the stage, which will set the size of the window. Also set the title of the window.
To show our “Hello world” message on the stage, you need to create an actor—in this case, a label. Set the font type of the label, the text to display, and the color of the label. Here, let's set the color manually rather than using a predefined color. Once the label is set, add the actor (the label) to the stage.
Labels work similarly to GTK+ widgets, but Clutter is not widget-based in the same way GTK+ is. Although both have similar functions and parts, Clutter contains only a handful of built-in “widgets”, which are called actors. Clutter's actors are limited to rectangles, labels, images, video textures and a few other items.
To finish the example, tell the stage to show all of its contents and call the main Clutter loop, which will display the interface. The last step is to tell Python to create an instance of your class.
Listing 1. “Hello World” Using Clutter
import clutter
class HelloWorld:
def __init__ (self):
# Create stage and set its properties.
self.stage = clutter.Stage()
self.stage.set_color(clutter.color_parse('Black'))
self.stage.set_size(500, 400)
self.stage.set_title('Clutter Hello World')
# Create label and set its properties.
color = clutter.Color(0xff, 0xcc, 0xcc, 0xdd)
hello = clutter.Label()
hello.set_font_name('Mono 32')
hello.set_text("Hello There!")
hello.set_color(color)
hello.set_position(100, 200)
# Add label to stage.
self.stage.add(hello)
# Start main clutter loop.
self.stage.show_all()
clutter.main()
# Run program.
main = HelloWorld()
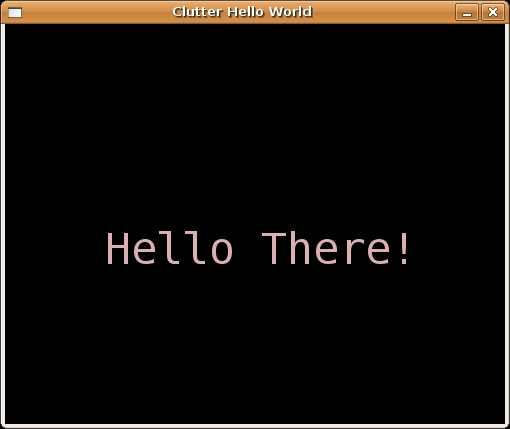
Figure 2. The simple “Hello World” Clutter Program Running on Ubuntu
Now, let's take a look at a more useful Clutter program. Our program will use the Clutter GStreamer library to display and control a video file on the stage. Connect GStreamer's video output to a video texture, which is then displayed on the stage and can be manipulated as an actor.
There are three main actors on the stage: the play button, the pause button and the GStreamer video. When the pause button is pressed, the video pauses, and it will continue playing when the play button is pressed. The program is shown in Listing 2, and the window is shown in Figure 3.
After the initial setup, define a signal for responding to mouse clicks. Clutter uses signals to respond to events in the same way GTK+ does. The signal dictates that when any button on the mouse is clicked, the specified function is called.
Next, create the buttons by creating rectangle actors for the button shape and text actors for the button text. Remember that Clutter is not widget-based, and there are no default button widgets as part of the API.
To create the video, you need a video texture. A video texture is a physical plane on which GStreamer can display the video. The video texture can be manipulated on the stage like an ordinary actor.
You also need two other GStreamer elements to play the video: a playbin and a pipeline. Clutter-Gstreamer will play any file type that GStreamer can play. After creating the playbin, set the location of the video to play and add the playbin to the pipeline.
Then, set the position of the video texture, add it to the stage and tell GStreamer to start playing the video.
Finally, create the mouseClick function. This function is called when the mouse is clicked anywhere on the stage. Check to see if the left mouse button was clicked inside one of the buttons and if it was, change the size and color of the buttons to give visual feedback of the click. Tell GStreamer to start or stop the video depending on which button was pressed.
Listing 2. Clutter-Based Video Player
import clutter
import gst
from clutter import cluttergst
class HelloWorld:
def __init__ (self):
# Create stage and set its properties.
self.stage = clutter.Stage()
self.stage.set_color(clutter.color_parse('Black'))
self.stage.set_size(500, 400)
self.stage.set_title('Clutter Basic Video Player')
# Create signal for handling mouse clicks.
self.stage.connect('button-press-event', self.mouseClick)
# Create play button shape.
self.playBtn = clutter.Rectangle()
self.playBtn.set_color(clutter.Color(66, 99, 150, 0x99))
self.playBtn.set_size(50, 30)
self.playBtn.set_position(118, 34)
self.stage.add(self.playBtn)
# Create play button text
# and overlay the rectangle.
playTxt = clutter.Label()
playTxt.set_text("Play")
playTxt.set_color(clutter.color_parse('Black'))
playTxt.set_position(130, 40)
self.stage.add(playTxt)
# Same for stop button.
self.stopBtn = clutter.Rectangle()
self.stopBtn.set_color(clutter.Color(66, 99, 150, 0x99))
self.stopBtn.set_size(50, 30)
self.stopBtn.set_position(218, 34)
self.stage.add(self.stopBtn)
StopTxt = clutter.Label()
StopTxt.set_text("Pause")
StopTxt.set_color(clutter.color_parse('Black'))
StopTxt.set_position(225, 40)
self.stage.add(StopTxt)
# Create video texture.
video_tex = cluttergst.VideoTexture()
self.pipeline = gst.Pipeline("mypipe")
playbin = video_tex.get_playbin()
# Specify video file to play.
movfile = "file:///home/user/Videos/Video.mov"
playbin.set_property('uri', movfile)
# Add to playbin to the pipeline.
self.pipeline.add(playbin)
# Set position and start playing the video.
video_tex.set_position(90,100)
self.stage.add(video_tex)
self.pipeline.set_state(gst.STATE_PLAYING)
self.stage.show_all()
clutter.main()
def mouseClick (self, stage, event):
# Mouse click function, called when the moused
# is clicked *anywhere* on the stage, we check
# the mouse coordinates manually to see if the
# click occurred inside a button.
# Check for left mouse button.
if event.button == 1:
# Check to see if stop button was pressed.
if event.x > 218 and event.x < 268 and \
event.y > 34 and event.y < 64:
self.stopBtn.set_color(clutter.Color(33,50,150,0x89))
self.playBtn.set_color(clutter.Color(66,99,150,0x99))
self.stopBtn.set_size(49, 29)
self.playBtn.set_size(50, 30)
self.pipeline.set_state(gst.STATE_PAUSED)
# Check to see if the play button was pressed.
if event.x > 118 and event.x < 168 and \
event.y > 34 and event.y < 64:
self.playBtn.set_color(clutter.Color(33,50,150,0x89))
self.stopBtn.set_color(clutter.Color(66,99,150,0x99))
self.playBtn.set_size(49, 29)
self.stopBtn.set_size(50, 30)
self.pipeline.set_state(gst.STATE_PLAYING)
# Run program.
main = HelloWorld()
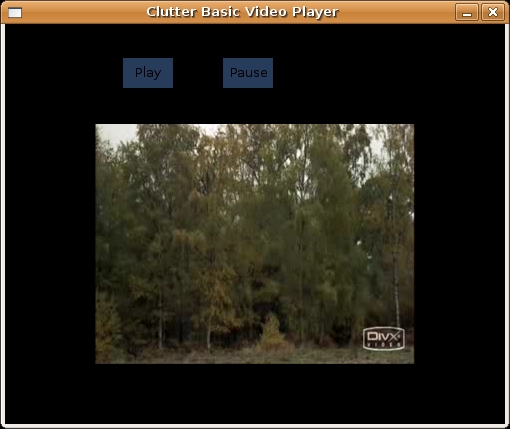
Figure 3. Clutter Video Player Playing the Monty Python Skit “How Not to Be Seen”
An important feature of Clutter is its animation API. Animating any actors on the stage is easy with Clutter. Using the animation API, you can add smooth animations and effects to your Clutter application.
In the next example, let's take the GStreamer video texture and manipulate it in three dimensions. The GStreamer texture is rotating on the y-axis constantly.
The program is shown in Listing 3, and the window is shown in Figure 4.
After the initial setup, create a timeline. Timelines are used in Clutter to control animation and time events. The example timeline lasts for 100 frames at ten frames per second, and the timeline is set to loop forever.
Next create an alpha (see The Alpha Functions sidebar) for the animation, assign it to your timeline and give it a smooth step decreasing function. In simplest terms, the alpha is used to control the speed of the animation. The smooth step function causes the animation to speed up, then slow down, come to a halt, and then start up again. Clutter has several functions built in that you can use with the alpha, including sine, exponential and ramp functions.
Next, define the Rotation behavior the animation uses. Clutter uses behavior effects to describe animations. The Opacity behavior, for example, can change the visual alpha of an actor, making it transparent or opaque. Other behaviors include Scale, Path, Depth, B-Spline and Ellipse.
In this example, we tell our Rotation behavior to rotate over the x-axis, rotate clockwise, start rotating at an angle of zero, end at 360, and finally, tell it to use the alpha created earlier, respectively. After that, the rotational center, or the point the actor rotates around, is set to the approximate center of the GStreamer texture and the Rotation behaviour is applied to the video texture.
In addition to the normal startup steps, the timeline must be started.
Listing 3. Clutter Rotating a Video
import clutter
import gst
from clutter import cluttergst
class HelloWorld:
def __init__ (self):
self.stage = clutter.Stage()
self.stage.set_color(clutter.color_parse('Black'))
self.stage.set_size(500, 400)
self.stage.set_title('Clutter 3-D Video Player')
# Setup video.
video_tex = cluttergst.VideoTexture()
self.pipeline = gst.Pipeline("mypipe")
playbin = video_tex.get_playbin()
movfile = "file:///home/user/Videos/Video.mov"
playbin.set_property('uri', movfile)
self.pipeline.add(playbin)
video_tex.set_position(90,80)
self.stage.add(video_tex)
self.pipeline.set_state(gst.STATE_PLAYING)
# Create timeline that lasts for 100 frames
# at ten frames per second.
timeline = clutter.Timeline(100, 10)
# Set timeline to loop forever.
timeline.set_loop(True)
# Create an alpha.
alpha = clutter.Alpha(timeline, clutter.smoothstep_dec_func)
# Set up rotation.
Rotation = clutter.BehaviourRotate(
axis=clutter.Y_AXIS,
direction=clutter.ROTATE_CW,
angle_start=0,
angle_end=360,
alpha=alpha)
Rotation.set_center(160, 160, 0)
Rotation.apply(video_tex)
# Start it all up.
timeline.start()
self.stage.show_all()
clutter.main()
# Run program.
main = HelloWorld()
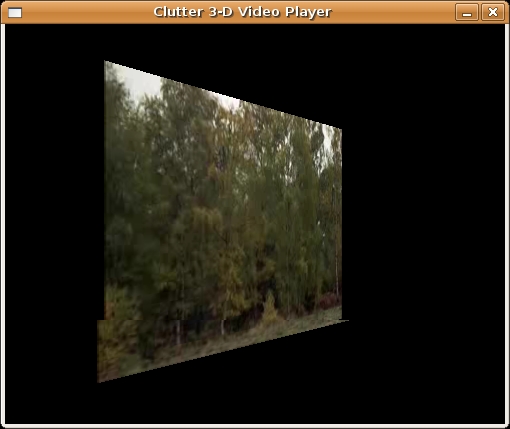
Figure 4. The 3-D Clutter Video Player, Partway through Rotating the Video
The Alpha Functions
At first, especially to those who've forgotten their Calculus and Algebra, the alpha functions may seem unpredictable or confusing. There is a large list of the number of available functions: exp_dec_func, exp_inc_func, ramp_dec_func, ramp_func, ramp_inc_func, sine_dec_func, sine_func, sine_half_func, sine_inc_func, smoothstep_dec_func, smoothstep_inc_func and square_func. Here's a brief explanation of each type:
Exponential functions: depending on whether you're using a decaying function or an increasing function, exponential functions make the animation speed up or slow down at an exponential rate.
Ramp functions: ramp functions animate at a constant speed. However, the full ramp function animates at both a negative and a positive constant speed by switching directions.
Sine functions: sine functions make the animation reverse. Like the graph of a sine function, the animation would speed up, slow down, change directions, speed up in the reverse direction, and then slow down again.
Smooth step functions: the smooth step function works logistically. It starts slowly, then quickly increases and finally slows down toward the end of the animation.
Square functions: square functions follow a step pattern, which results in quick changes between two constant animation speeds.
Hopefully, you've learned a good deal about how Clutter works, and you can start developing and programming using the Clutter API. Using just the features you've seen here, you'll be able to create any interface that uses text, buttons, images and video with Clutter. Of course, after learning the basics, the more advanced UI elements will become easier to understand and work with.
In the future, the Clutter developers will continue to improve and update the API, and many new improvements are expected in the Clutter 1.0 release. You can learn more about the Clutter development process from the Web site (see Resources). Clutter is going to power many innovative open-source applications in the future.
Resources
Clutter Home Page: clutter-project.org
Elisa Project Page: elisa.fluendo.com
Clutter Source Files: www.clutter-project.org/sources
Alex Crits-Christoph has been working with Linux for some time now. He enjoys developing and designing open-source graphical user interfaces.

