
High-Performance Networking Programming in C
TCP/IP network programming in C on Linux is good fun. All the advanced features of the stack are at your disposal, and you can do lot of interesting things in user space without getting into kernel programming.
Performance enhancement is as much an art as it is a science. It is an iterative process, akin to an artist gingerly stroking a painting with a fine brush, looking at the work from multiple angles at different distances until satisfied with the result.
The analogy to this artistic touch is the rich set of tools that Linux provides in order to measure network throughput and performance. Based on this, programmers tweak certain parameters or sometimes even re-engineer their solutions to achieve the expected results.
I won't dwell further upon the artistic side of high-performance programming. In this article, I focus on certain generic mechanisms that are guaranteed to provide a noticeable improvement. Based on this, you should be able to make the final touch with the help of the right tools.
I deal mostly with TCP, because the kernel does the bandwidth management and flow control for us. Of course, we no longer have to worry about reliability either. If you are interested in performance and high-volume traffic, you will arrive at TCP anyway.
Once we answer that question, we can ask ourselves another useful question, “How can we get the best out of the available bandwidth?”
Bandwidth, as defined by Wikipedia, is the difference between the higher and lower cutoff frequencies of a communication channel. Cutoff frequencies are determined by basic laws of physics—nothing much we can do there.
But, there is a lot we can do elsewhere. According to Claude Shannon, the practically achievable bandwidth is determined by the level of noise in the channel, the data encoding used and so on. Taking a cue from Shannon's idea, we should “encode” our data in such a way that the protocol overhead is minimal and most of the bits are used to carry useful payload data.
TCP/IP packets work in a packet-switched environment. We have to contend with other nodes on the network. There is no concept of dedicated bandwidth in the LAN environment where your product is most likely to reside. This is something we can control with a bit of programming.
Here's one way to maximize throughput if the bottleneck is your local LAN (this might also be the case in certain crowded ADSL deployments). Simply use multiple TCP connections. That way, you can ensure that you get all the attention at the expense of the other nodes in the LAN. This is the secret of download accelerators. They open multiple TCP connections to FTP and HTTP servers and download a file in pieces and reassemble it at multiple offsets. This is not “playing” nicely though.
We want to be well-behaved citizens, which is where non-blocking I/O comes in. The traditional approach of blocking reads and writes on the network is very easy to program, but if you are interested in filling the pipe available to you by pumping packets, you must use non-blocking TCP sockets. Listing 1 shows a simple code fragment using non-blocking sockets for network read and write.
Listing 1. nonblock.c
/* set socket non blocking */
fl = fcntl(accsock, F_GETFL);
fcntl(accsock, F_SETFL, fl | O_NONBLOCK);
void
poll_wait(int fd, int events)
{
int n;
struct pollfd pollfds[1];
memset((char *) &pollfds, 0, sizeof(pollfds));
pollfds[0].fd = fd;
pollfds[0].events = events;
n = poll(pollfds, 1, -1);
if (n < 0) {
perror("poll()");
errx(1, "Poll failed");
}
}
size_t
readmore(int sock, char *buf, size_t n) {
fd_set rfds;
int ret, bytes;
poll_wait(sock,POLLERR | POLLIN );
bytes = readall(sock, buf, n);
if (0 == bytes) {
perror("Connection closed");
errx(1, "Readmore Connection closure");
/* NOT REACHED */
}
return bytes;
}
size_t
readall(int sock, char *buf, size_t n) {
size_t pos = 0;
ssize_t res;
while (n > pos) {
res = read (sock, buf + pos, n - pos);
switch ((int)res) {
case -1:
if (errno == EINTR || errno == EAGAIN)
continue;
return 0;
case 0:
errno = EPIPE;
return pos;
default:
pos += (size_t)res;
}
}
return (pos);
}
size_t
writenw(int fd, char *buf, size_t n)
{
size_t pos = 0;
ssize_t res;
while (n > pos) {
poll_wait(fd, POLLOUT | POLLERR);
res = write (fd, buf + pos, n - pos);
switch ((int)res) {
case -1:
if (errno == EINTR || errno == EAGAIN)
continue;
return 0;
case 0:
errno = EPIPE;
return pos;
default:
pos += (size_t)res;
}
}
return (pos);
}
Note that you should use fcntl(2) instead of setsockopt(2) for setting the socket file descriptor to non-blocking mode. Use poll(2) or select(2) to figure out when the socket is ready to read or write. select(2) cannot figure out when the socket is ready to write, so watch out for this.
How does non-blocking I/O provide better throughput? The OS schedules the user process differently in the case of blocking and non-blocking I/O. When you block, the process “sleeps”, which leads to a context switch. When you use non-blocking sockets, this problem is avoided.
The other interesting technique is scatter/gather I/O or using readv(2) and writev(2) for network and/or disk I/O.
Instead of using buffers as the unit of data transfer, an array of buffers is used instead. Each buffer can be a different length, and this is what makes it so interesting.
You can transfer large chunks of data split between multiple sources/destinations from/to the network. This could be a useful technique, depending upon your application. Listing 2 shows a code snippet to illustrate its use.
Listing 2. uio.c
#include <sys/types.h>
#include <sys/uio.h>
#include <unistd.h>
size_t
writeuio(int fd, struct iovec *iov, int cnt)
{
size_t pos = 0;
ssize_t res;
n = iov[0].iov_cnt;
while (n > pos) {
poll_wait(fd, POLLOUT | POLLERR);
res = writev (fd, iov[0].iov_base + pos, n - pos);
switch ((int)res) {
case -1:
if (errno == EINTR || errno == EAGAIN)
continue;
return 0;
case 0:
errno = EPIPE;
return pos;
default:
pos += (size_t)res;
}
}
return (pos);
}
When you combine scatter/gather I/O with non-blocking sockets, things get a little complex, as shown in Figure 1. The code for tackling this hairy issue is shown in Listing 3.
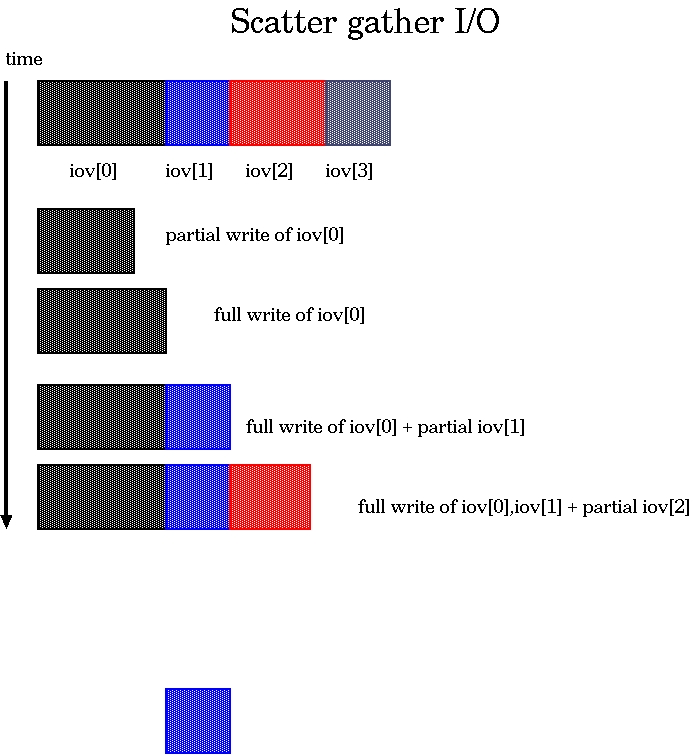
Figure 1. Possibilities in Non-Blocking Write with Scatter/Gather I/O
Listing 3. nonblockuio.c
writeiovall(int fd, struct iov *iov, int nvec) {
int i, bytes;
i = 0;
while (i < nvec) {
do
{
rv = writev(fd, &vec[i], nvec - i);
} while (rv == -1 &&
(errno == EINTR || errno == EAGAIN));
if (rv == -1) {
if (errno != EINTR && errno != EAGAIN) {
perror("write");
}
return -1;
}
bytes += rv;
/* recalculate vec to deal with partial writes */
while (rv > 0) {
if (rv < vec[i].iov_len) {
vec[i].iov_base = (char *)
vec[i].iov_base + rv;
vec[i].iov_len -= rv;
rv = 0;
}
else {
rv -= vec[i].iov_len;
++i;
}
}
}
/* We should get here only after we write out everything */
return 0;
}
A partial write of any buffer can occur, or you can get any combination of a few full writes and few partial writes. Therefore, the while loop has to take care of all such possible combinations.
Network programming is not all about sockets, however. We still haven't solved the problem of having to use hard disks, which are mechanical devices and consequently are much slower than main memory and even the network in many, if not most, cases (especially high-performance computing environments).
You can use some other form of persistent storage, but today, none matches the huge storage capacity that hard disks offer. Currently, most applications on the Internet push several gigabytes of data, and you end up with heavy storage needs anyway.
To test disk performance, type this:
$ hdparm -rT /dev/sda (/dev/hda if IDE)
Check whether you are getting good throughput. If not, enable DMA and other safe options using this command:
$ hdparm -d 1 -A 1 -m 16 -u 1 -a 64 /dev/sda
We also need to be able to avoid redundant copies and other time-consuming CPU operations to squeeze the maximum bandwidth from the network. A very effective tool for achieving that is the versatile mmap(2) system call. This is a very useful technique for avoiding the copy-to-buffer cache and, hence, improves performance for network I/O. But, if you use mmap(2) with NFS, you are asking for trouble. Listing 4 shows a code snippet that illustrates the use of mmap(2) for both reading and writing files.
Listing 4. mmap.c
/******************************************
* mmap(2) file write *
* *
*****************************************/
caddr_t *mm = NULL;
fd = open (filename, O_RDWR | O_TRUNC | O_CREAT, 0644);
if(-1 == fd)
errx(1, "File write");
/* NOT REACHED */
/* If you don't do this, mmapping will never
* work for writing to files
* If you don't know file size in advance as is
* often the case with data streaming from the
* network, you can use a large value here. Once you
* write out the whole file, you can shrink it
* to the correct size by calling ftruncate
* again
*/
ret = ftruncate(ctx->fd,filelen);
mm = mmap(NULL, header->filelen, PROT_READ | PROT_WRITE,
MAP_SHARED, ctx->fd, 0);
if (NULL == mm)
errx(1, "mmap() problem");
memcpy(mm + off, buf, len);
off += len;
/* Please don't forget to free mmap(2)ed memory! */
munmap(mm, filelen);
close(fd);
/******************************************
* mmap(2) file read *
* *
*****************************************/
fd = open(filename, O_RDONLY, 0);
if ( -1 == fd)
errx(1, " File read err");
/* NOT REACHED */
fstat(fd, &statbf);
filelen = statbf.st_size;
mm = mmap(NULL, filelen, PROT_READ, MAP_SHARED, fd, 0);
if (NULL == mm)
errx(1, "mmap() error");
/* NOT REACHED */
/* Now onward you can straightaway
* do a memory copy of the mm pointer as it
* will dish out file data to you
*/
bufptr = mm + off;
/* You can straightaway copy mmapped memory into the
network buffer for sending */
memcpy(pkt.buf + filenameoff, bufptr, bytes);
/* Please don't forget to free mmap(2)ed memory! */
munmap(mm, filelen);
close(fd);
TCP sockets under Linux come with a rich set of options with which you can manipulate the functioning of the OS TCP/IP stack. A few options are important for performance, such as the TCP send and receive buffer sizes:
sndsize = 16384; setsockopt(socket, SOL_SOCKET, SO_SNDBUF, (char *)&sndsize, (int)sizeof(sndsize)); rcvsize = 16384; setsockopt(socket, SOL_SOCKET, SO_RCVBUF, (char *)&rcvsize, (int)sizeof(rcvsize));
I am using conservative values here. Obviously, it should be much higher for Gigabit networks. These values are determined by the bandwidth delay product. Interestingly, I have never found this to be an issue, so I doubt if this would give you a performance boost. It still is worth mentioning, because the TCP window size alone can give you optimal throughput.
Other options can be set using the /proc pseudo-filesystem under Linux (including the above two), and unless your Linux distribution turns off certain options, you won't have to tweak them.
It is also a good idea to enable PMTU (Path Maximum Transmission Unit) discovery to avoid IP fragmentation. IP fragmentation can affect not just performance, but surely it's more important regarding performance than anything else. To avoid fragmentation at any cost, several HTTP servers use conservative packet sizes. Doing so is not a very good thing, as there is a corresponding increase in protocol overhead. More packets mean more headers and wasted bandwidth.
Instead of using write(2) or send(2) for transfer, you could use the sendfile(2) system call. This provides substantial savings in avoiding redundant copies, as bits are passed between the file descriptor and socket descriptor directly. Be aware that this approach is not portable across UNIX.
Applications should be well designed to take full advantage of network resources. First and foremost, using multiple short-lived TCP connections between the same two endpoints for sequential processing is wrong. It will work, but it will hurt performance and cause several other headaches as well. Most notably, the TCP TIME_WAIT state has a timeout of twice the maximum segment lifetime. Because the round-trip time varies widely in busy networks and networks with high latency, oftentimes this value will be inaccurate. There are other problems too, but if you design your application well, with proper protocol headers and PDU boundaries, there never should be a need to use different TCP connections.
Take the case of SSH, for instance. How many different TCP streams are multiplexed with just one connection? Take a cue from it.
You don't have to work in lockstep between the client and the server. Simply because the protocols and algorithms are visualized in a fixed sequence does not imply that the implementation should follow suit.
You can make excellent use of available bandwidth by doing things in parallel—by not waiting for processing to complete before reading the next packet off the network. Figure 2 illustrates what I mean.

Figure 2. Pipelining
Pipelining is a powerful technique employed in CPUs to speed up the FETCH-DECODE-EXECUTE cycle. Here, we use the same technique for network processing.
Obviously, your wire protocol should have the least overhead and should work without relying much on future input. By keeping the state machine fairly self-contained and isolated, you can process efficiently.
Avoiding redundant protocol headers or fields that are mostly empty or unused can save you precious bandwidth for carrying real data payloads. Header fields should be aligned at 32-bit boundaries and so should the C structures that represent them.
If your application already is in production and you want to enhance its performance, try some of the above techniques. It shouldn't be too much trouble to attack the problem of re-engineering an application if you take it one step at a time. And remember, never trust any theory—not even this article. Test everything for yourself. If your testing does not report improved performance, don't do it. Also, make sure your test cases take care of LAN, WAN and, if necessary, satellite and wireless environments.
TCP has been a field of intense research for decades. It's an extremely complex protocol with a heavy responsibility on the Internet. We often forget that TCP is what holds the Internet together without collapse due to congestion. IP connects networks together, but TCP ensures that routers are not overloaded and that packets do not get lost.
Consequently, the impact of TCP on performance is higher than any other protocol today. It is no wonder that top-notch researchers have written several papers on the topic.
The Internet is anything but homogeneous. There is every possible physical layer of technology on which TCP/IP works today. But, TCP is not designed for working well through wireless networks. Even a high-latency satellite link questions some of TCP's assumptions on window size and round-trip time measurement.
And, TCP is not without its share of defects. The congestion control algorithms, such as slow start, congestion avoidance, fast retransmit, fast recovery and so on, sometimes fail. When this happens, it hurts your performance. Normally, three duplicate ACK packets are sufficient for triggering congestion control mechanisms. No matter what you do, these mechanisms can drastically decrease performance, especially if you have a very high-speed network.
But, all else being equal, the above techniques are few of the most useful methods for achieving good performance for your applications.
Gunning for very high performance is not something to be taken lightly. It's dependent on heuristics and empirical data as well as proven techniques. As I mentioned previously, it is an art best perfected by practice, and it's also an iterative process. However, once you get a feel for how things work, it will be smooth sailing. The moment you build a stable base for a fast client/server interaction like this, building powerful P2P frameworks on top is no great hassle.
Resources
Polipo User Manual: www.pps.jussieu.fr/~jch/software/polipo/manual
TCP Tuning and Network Troubleshooting: www.onlamp.com/pub/a/onlamp/2005/11/17/tcp_tuning.html
Wikipedia's Definition of Bandwidth: en.wikipedia.org/wiki/Bandwidth
Advanced Networking Techniques: beej.us/guide/bgnet/output/html/multipage/advanced.html
TCP and Congestion Control Slides: www.nishida.org/soi1/mgp00001.html
Girish Venkatachalam is an open-source hacker deeply interested in UNIX. In his free time, he likes to cook vegetarian dishes and actually eat them. He can be contacted at girish1729@gmail.com.

