
Role-Based Single Sign-on with Perl and Ruby
Portland, Oregon, is a city that takes pride in managing its resources wisely. So, maybe it's natural that this article describes how to make computer resources and legacy CGI scripts much more manageable. This is accomplished by an elegant, easy-to-build system that provides benefits in three different areas. For starters, it gives programmers a one-line solution for controlling access to any script. Meanwhile, on the back end, it provides administrators with a friendly Web-based application for managing access. Finally, and maybe most important, the system creates an experience for end users that's logical and simple. For example, people are required to log in only once when they first attempt to access a protected script. Afterward, they'll have uninterrupted access to any other protected areas if they're authorized to enter.
Here's a little bit of context to see why this kind of system might be needed. I work at Lewis & Clark College, nestled in 137 deeply wooded acres. While I sit on one end of campus with the aroma of wet Douglas Fir trees drifting in through the window, our Web applications are increasingly being used by staff members in new ways and in far-flung locations. We have an excellent LDAP-based authentication system that's managed by IT. People can log in to dozens of different applications, from many places on the hilly campus with their one user name and password. The programmers have well-tested Perl and PHP libraries that tie into this system.
You might be wondering, So what's the problem? Why build another layer on top of something that's working? And actually, for a long time, there was no need. The existing setup was just fine. But over time, we began having growing pains, coming from several sources.
The number of Perl CGI applications for internal users has been growing steadily. These apps are increasingly tailored for very specific tasks and are intended to be used by only a small group of people.
These legacy applications were developed over a period of years by many different developers. Although they each used the LDAP system described above, they handled sessions, cookies and access in different ways.
A whole set of new scripts required protected access for certain user groups. We had no good way of keeping track of or managing who would be able to access what.
As a software engineer, my first thought was to create a small reusable library of some kind so that code wouldn't be duplicated. I would write the code for logging in and session management just once and use it in many places. But, before I got started, I realized there were a couple deeper issues I should address.
We ought to handle and support the notion of roles directly. Up to this point, our software had focused on users, the actual people who would be using the software. But in fact, our users each have many roles, and one role may be performed by many people as well.
The existing scripts combined two distinct functions that would be better kept separate: authentication and authorization. Authentication is the process of determining whether users are who they say they are. Authorization is the process of deciding should user X be able to do thing Y?
The plan for the new system features three independent pieces: a database containing the knowledge of users and their roles, a Ruby on Rails application for administrators to manage the database, and a set of adapter libraries for each application programming environment in use. For our scenario, I wrote a Perl module to connect our legacy applications to the new framework (Figure 1).

Figure 1. System Architecture
It was fairly simple to create an appropriate knowledge base for this project. We used MySQL, but any relational database supported by both Ruby on Rails and Perl would be fine. The database schema is the standard solution for handling a many-to-many relationship (Figure 2). The admin_users table is simply a list of user names. Simple inclusion in the table doesn't grant a user any rights. It provides only the possibility for that user to be linked with roles. Similarly, the admin_roles table enumerates and describes only the roles that users may or may not be assigned to. I included a description field so that administrators could document the intended use of a role. In this simple schema, a role name might be office manager or news editor.

Figure 2. Database Schema
While the first two tables are essentially static, the final table, admin_roles_admin_users, captures the dynamic information about which users have been assigned to which roles. For each instance of a particular user having a particular role, a new record will be created in this table. This kind of schema is very pure and flexible, but the flipside is that it makes it nearly impossible to enter data by hand, and somewhat of a chore to write an application to manage it. This is where Ruby on Rails comes in.
Ruby on Rails (RoR) shines in the area of database applications that need to provide CRUD (Create, Retrieve, Update, Delete) functionality. It was a simple and easy task to get our database management application up and running (Figure 3). Plenty of good tutorials are available for creating a basic RoR Web application, so in this article I describe only the necessary customizations. As it turned out, there weren't many.

Figure 3. Admin Application, Role Listing
The first thing to note is that I carefully chose the names of the tables and columns to comply with Ruby on Rails naming conventions (Figure 2). This turned out to be a bit tricky; I couldn't find a single source for all the conventions and their implications. In this situation with a join table (admin_roles_admin_users), it was important to concatenate the names in alphabetical order and not to include an id column.
The main customization necessary was to tell RoR about the many-to-many relationship. This was accomplished with a single line added to admin_role.rb:
class AdminRole < ActiveRecord::Base has_and_belongs_to_many :admin_users end
and an equivalent one in admin_user.rb:
class AdminUser < ActiveRecord::Base has_and_belongs_to_many :admin_roles end
With these changes, RoR could work with the data correctly and maintain all the proper relationships. In order actually to display and edit the join information, a bit more work was required in the view and controller classes (see Resources). When finished, I had nice screens, such as the one shown in Figure 4.
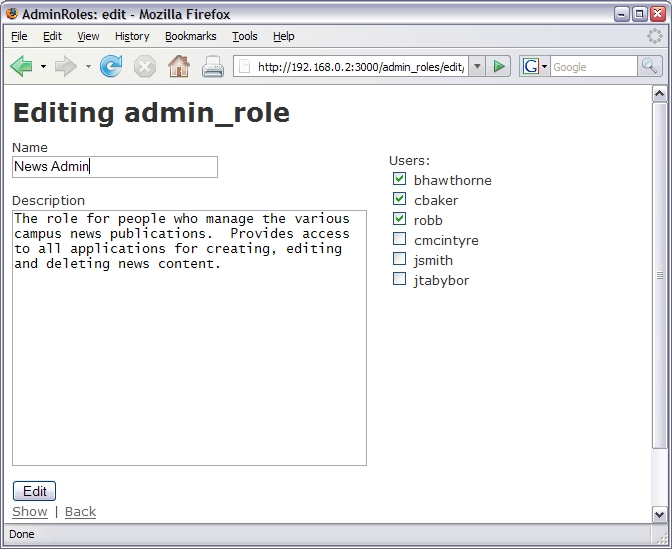
Figure 4. Admin Application, Editing a Role
With the administrative application in place, we could begin populating the database. But for this information actually to be used, an adapter would have to be written for our Perl/CGI runtime environment.
I'm a big fan of declarative (as opposed to procedural) programming, when it can be used. What does this mean? Well, one way to check for authorization might look like this:
my $username = $auth->currrent_user;
if (! $username) {
# Handle the login form
} elsif (! $auth->user_has_role($username, news editor)) {
# Show error message and exit
}
Sure, that could be simplified a bit—for example, by implementing a current_user_has_role() method. But it's still procedural, telling the computer what to do. Instead, we can reduce this to one line by telling the computer (declaring) what we want:
$auth->require_role(news editor);
This require_role() method means this role is required to get any further, and it gives a very simple guarantee: execution will proceed beyond this point only if the current user should be able to. If the user 1) already has logged in and 2) has the given role, then require_role() will simply return and the script will continue executing normally. Otherwise, the $auth object will take whatever steps are necessary to first authenticate and then either grant or deny access to users based on their assigned roles.
This makes a lot of things easier. For application programmers, it means they don't have to worry about how the $auth object does its job. Nor do they have to worry about whether they got their ifs and elsifs written correctly. All they need to worry about is what role is appropriate for that script. It was honestly a lot of fun to implement the Auth.pm Perl module and watch so much happen with so little effort required by the application programmer. Figure 5 is a flowchart that shows what happens when require_role is invoked.
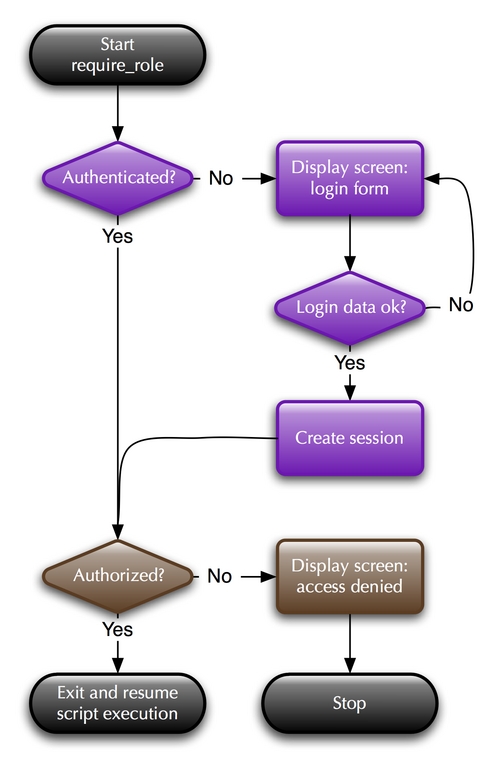
Figure 5. Auth.pm Flowchart
Concretely, my implementation required only four short files:
Auth.pm: the gatekeeper for the system. It implements the business logic of checking first for authentication and second for authorization.
login.tt2 (using Template Toolkit): renders a login form with embedded hidden values to keep track of the originally requested destination page. The results of the login attempt are sent to auth_login.cgi.
auth_error.tt2: renders an error page, letting users know that they don't have the required authorization to access the script.
auth_login.cgi: responsible for the simple task of authenticating the user and restarting the access checking. In our case, it connects to the LDAP system and looks to see if the given login information is correct. If it is, then this fact is saved in a session/cookie, and the originally requested CGI script is re-executed.
Here are the most important sections of each file:
auth.pm: The heart of this module is the require_role() method. It contains the control logic for the whole process. In my implementation, I use CGI.pm in the OO style, so I pass it in as a parameter. Notice how the use of return vs. exit controls the user's experience:
sub require_role { # # Ensure that the user is logged in and has the # specified role. # my $self = shift; my $role = shift; my $cgi = shift; if (! $role) { confess("No role was specified"); } if (! $cgi) { confess("No CGI object was given"); } my $uname = $self->get_authentication_info(); if ($uname) { # The user has been authenticated. if ($self->user_has_role($uname, $role)) { # Success - continue. return; } else { # Failure - the user does not have # the specified role. $self->_display_error_page($cgi); exit; } } else { # The user has NOT been authenticated. $self->_display_login_page($cgi); exit; } }login.tt2: Template Toolkit is an awesome way to create HTML pages. I could have achieved the same thing with a here document in Perl, but this is much cleaner. It also allows the template to be executed from both Auth.pm and auth_login.cgi.
<p>Please login to access <b>[% target_page %]</b>:</p> <form method="POST" action="/cgi-bin/auth_login.cgi"> <table> <tr> <td>User name:</td><td><input name="username"></td> </tr> <tr> <td>Password:</td><td><input name="password" type="password"></td> </tr> <tr> <td colspan="2" align="right"> <input type="hidden" name="target_url" value="[% target_url %]"> <input type="hidden" name="target_page" value="[% target_page %]"> <input type="submit" value="Login"> </td> </tr> </table> </form> [% IF error_message %] <p style="color: #ff0000"> <b>[% error_message %]</b> </p> [% END %]auth_login.cgi: finally, here is the key section from the login form handler. This is a very simple script:
if (&ldapauth($name, $pass)) { # Success: Create a session, and # redirect to the target page. &create_session($name); print "<html><head>"; print '<meta http-equiv="refresh" content="0;url=' . $target_url . '">'; print "</head></html>"; } else { # Failure: Re-display the login form with an # error message. print $q->header; &redisplay_page("Login failed: password incorrect.", $target_page, $target_url); }
With all the pieces in place, we're ready to go. Here's a simple Perl CGI script that we want to try to protect:
#!/usr/bin/perl
use CGI;
my $q = CGI->new();
print $q->header;
print <<EOF;
<html>
<body bgcolor="#ee3333">
<p align="center" style="color: white">This
is a TOP SECRET page.</p>
</body>
</html>
EOF
It creates the output shown in Figure 6. But, now let's modify it to use the new framework:
#!/usr/bin/perl
use CGI;
use Auth;
my $q = CGI->new();
my $a = LC::Auth->new;
$a->require_role( 'top-secret stuff', $q);
print $q->header;
print <<EOF;
<html>
<body bgcolor="#ee3333">
<p align="center" style="color: white">This
is a TOP SECRET page.</p>
</body>
</html>
EOF
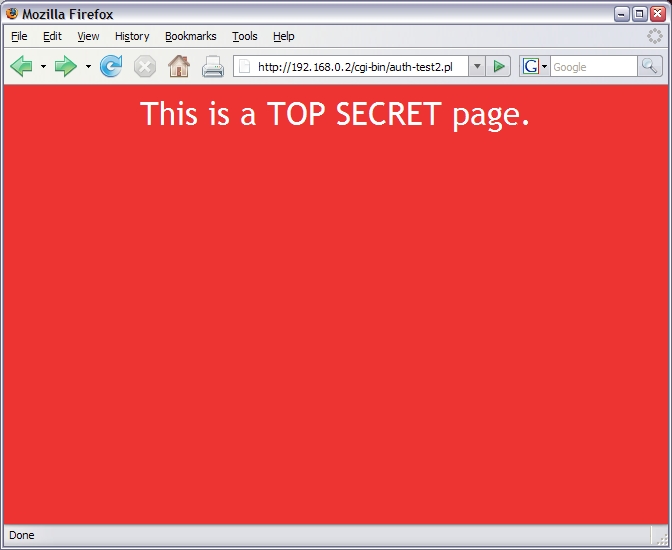
Figure 6. Unprotected Page
After making this simple change, reloading the browser now shows the same URL, but instead of the top-secret contents, we see a login form (Figure 7). Logging in correctly will do several things in the blink of an eye: send the information to auth_login.cgi, which will verify it, and then store the logged-in state in a session; redirect to the initial page, which will re-execute require_role(), which now finds the session, verifies role membership with the MySQL database; and then returns, allowing the script to display the content. But, as far as users are concerned, after submitting the login form, their application simply appears.

Figure 7. Login Form
This simple collection of a few short Web scripts provides a surprising array of benefits. Login functionality is factored out into a reusable module for Web scripts. Users and roles are now understood by the system. Authorization is separated from authentication. Single sign-on is provided, because one session/cookie is checked by all scripts. The functionality is language- and environment-independent. Easy-to-add custom login templates provide a seamless user experience. And, changes in role assignments take effect in real time, because the role database is consulted every time a script is invoked.
I see this as the payoff for putting in a little bit of time up front to investigate the problem, and plan a good solution. Another factor that contributed to this project's success is the use of Ruby on Rails for back-end data management. I envision that in the future, we'll have suites of application components such as this that adapt to the needs of our users on the front end. And behind the scenes, we'll quickly deploy management applications with tools such as Rails.
Resources
A Many-to-Many Tutorial for Rails by Jeffrey Hicks (9/4/2005): jrhicks.net/Projects/rails/has_many_and_belongs_to_many.pdf
Rails Framework Documentation: api.rubyonrails.com
Robb Shecter is a software engineer at Lewis & Clark College in Portland, Oregon. He's responsible for Web application development and software engineering processes. He's particularly interested in programming languages and software design. He can be reached at robb@lclark.edu.
