
Chapter 7: Static Meets Dynamic Adding Caches to Reduce Costs
This chapter excerpt is from "Scalable Internet Architectures", by Theo Schlossnagle, Copyright 2007 by Sams Publishing, ISBN 067232699x. Reprinted with permission, all rights reserved. To review a complete Table of Contents, please visit: www.samspublishing.com/title/067232699x
Chapter 6, "Static Content Serving for Speed and Glory," walked you through building a high-capacity static content serving system using a web caching system as the core technology. That software was responsible for fetching static content from "master" servers and peddling the cached content efficiently and inexpensively.
Why is the problem so different when the content is no longer static? Why can't we use the exact same solution presented in Chapter 6 for dynamic content?
Think of a website as if it were a phone book. A cache is a piece of paper that sits next to your phone book on which you record all the numbers you look up. Sounds like a good idea, right? So much so that you will probably tape that piece of notebook paper to the front of your phone book because you are likely to be interested only in a small subset of the information contained in the book and just as likely to be interested in the same information time and time again. Sounds perfect, right? But the analogy is flawed. Static content on a website is like a phone book, but imagine how difficult it would be to use your "paper cache" if the numbers inside the phone book constantly changed or if numbers differed based on who was looking them up. This is why caching dynamic content poses a more difficult problem than caching static content.
One misconception about caches is due to the misalignment of the computing-centric definition and the English definition of the word cache. In English, a cache is a place to store things often out of sight or in secret, and that definition assumes that it will be there when you return for it. A computer cache is only meant to speed acquisition of data; if it is missing when you look for it, you incur what is called a cache miss. This miss costs you nothing but time.
Caches are everywhere, from the "registers" on your CPU to L1/L2 CPU cache to disk drives to name servers to web systems–and the list goes on. Caches are fundamental engineering tools both inside and outside technology. If they are everywhere, how do you tell if a cache is a web cache? Let's define our web architecture as components directly creating browser-digestible content. This definition eliminates many architectural components that use caches: load balancers, databases, networking equipment, disk drives, and so on. This leaves us with web servers and application servers (glorified web servers).
Web servers are squished right in the middle of our spectacular architectural sandwich. Web caches are caching components of any type that operate directly on web servers or between web servers and their adjacent layers as depicted in Figure 7.1.
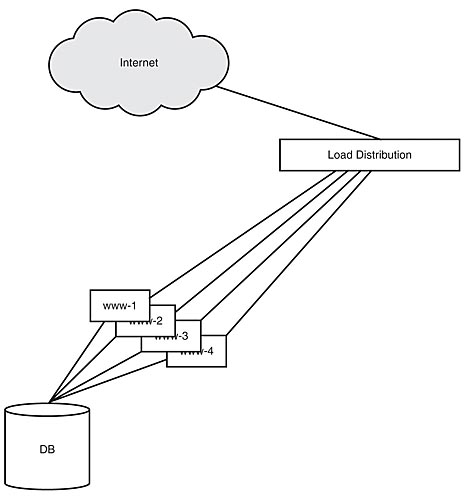
Figure 7.1: Typical architecture surrounding web servers.
Performance Tuning Has Its Limits - Why are we talking about caching and not application performance tuning? This is an important question and deserves attention. Our goal is to demonstrate techniques that can be used as building blocks for scalable systems–and caching is such a technique. Application tuning can only increase performance, and you'll note that the title of this book is not High Performance Internet Architectures. That is not to say that the concepts herein do not perform well, but rather that they focus on scalability and leave high-performance programming, tuning, and tweaking to other books.
Why are scalability and performance different? This is explored in detail in the introduction, but it deserves a few more words. No matter how fast you make your application, you will be limited if it does not scale horizontally.
To put it another way, if your application performance can be increased by 10%, 5%, or perhaps 1% by doubling your hardware, you are in big trouble. Moore's law says that your computer will be twice as fast in 18 months, so if you want to double your capacity, call me in a year and a half. On the other hand, if your application and architecture are designed to be able to leverage 60% or more performance by doubling your architecture, you can scale your system up today. Those percentages are arbitrary, and each architecture will have its own horizontal scaling efficiency. 100% means a perfectly (horizontally) scalable architecture, and 0% means an architecture that scales vertically, so performance tuning is your only option–so aim high.
There are five basic types of caching approaches when dealing with content distribution. Each has pros and cons, and more importantly each has its place. Often it is awkward, or simply impossible, to implement a specific caching approach due to the nature of the underlying data.
Layered/Transparent Cache
The transparent (or layered) cache should be well understood by now. This is the technology deployed to solve our image-serving problem in Chapter 6. The caching proxy is placed in front of the architecture and all requests arrive at the proxy. The proxy attempts to service the request by using its private cache. If the response to that request has not yet been cached (or the cache has expired or otherwise been destroyed), the cache is (re)populated by issuing a request for the content to the authoritative source and storing the response.
This technique is ideal for static content because it is often easy to build commodity proxy caches capable of holding the entire static content store (capacity-wise). This means that as time goes on, the cache will closely resemble the authoritative source, and nearly 100% of all requests issued to the cache can be satisfied on the spot from its local copy.
This technology is called transparent because many implementations allow you to place a cache in front of web servers without any configuration changes. In Chapter 6, we chose not to use the technology in this fashion because we wanted to play tricks with our domain name (images.example.com). In a local web environment, the cache can intercept data and proxy it back to web servers by acting as a bridge or as a configured part of the architecture in the form of an IP gateway. Either way, web clients have no knowledge of its placement in the architecture, and it has no noticeable side effects from their perspective.
These proxy caches have an additional added value discussed briefly in Chapter 6. This value is acceleration and it is appropriate to delve into it more deeply now. Web clients (users with browsers) will most certainly be connecting to the website over a long-haul link that has a distinctly poorer performance than the main egress point of the website to the Internet. This means that the website could push the request content back to the client very rapidly if it wasn't for the slow connection over which it must feed the data. This is often referred to as spoon-feeding clients.
Application servers differ from static content servers in that they have more work to do. A static server interprets a request and hands back the appropriate content to the client. A dynamic server interprets a request and is responsible for constructing the content and then handing it back to the client. The act of constructing the content often requires more expensive resources than simply serving it (more RAM and faster processors). This means that application servers sport a higher price tag than their static counterparts.
At the end of the day, you do not want to look back and find that you spent a considerable amount of resources on your application servers spoon-feeding clients. An application server should be generating content and delivering it as fast as possible so that it can proceed to the next dynamic content generation job in its queue. This is where proxy caches shine.
A proxy cache is an "accelerator" if it sits between the client and the application server. In this configuration, the connection between the proxy cache and application server is a local area one that boasts high throughput and low latency (shown in Figure 7.2). This means that the response from the application server can be completed quickly and stored on the proxy cache allowing the application server to proceed to the next request. The proxy cache then spoon-feeds the content to the slow client and acts as a cost-effective buffer preventing slow clients from affecting the application servers.
If most pages served from an application server are unique, it is clear that caching the data on a transparent cache will be of little value because the cache hit-rate will be nearly 0%. However, the accelerating aspect of the technology alone is often worth the investment.
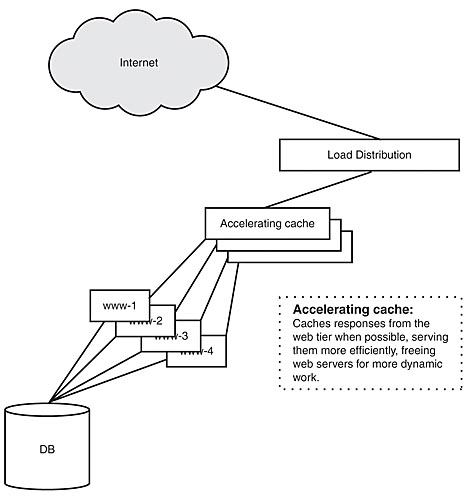
Figure 7.2: An accelerating web proxy cache.
Integrated (Look-Aside) Cache
An integrated cache steps far away from the transparent caching in both implementation and mentality. Transparent caching is simply a black-box architectural component that can be placed in front of an architecture for added benefit. Integrated caching is, as you might assume, integrated into the architecture–more specifically into the application. Integrated caching is most similar to the programming technique of computational reuse where we store the results of expensive computations on the side so that they don't need to be repeated.
Computational Reuse — is a programming technique that attempts to capitalize on situations where the cost of storing the results of a computation and later finding them again is less expensive than performing the computation again. The classic computer science example of computational reuse is the computation of Fibonacci numbers.
The nth Fibonacci number is defined as F(n) = F(n-1) + F(n-2) where F(0) = 0 and F(1) = 1. A small perl function to calculate the nth Fibonacci number would be as follows:
sub fib {
my $o = shift;
die "Only natural number indexes." if($o < 0 || $o != int($o));
return $o if ($o < 2);
return fib($o-2) + fib($o-1);
}
Running fib(30) on my laptop takes approximately 6.1 seconds. Why is this simple calculation so slow? When I calculate fib(28) and then proceed to calculate fib(29), I end up calculating fib(28) again. I calculate fib(28) twice, fib(27) three times, fib(26) five times, fib(25) eight times...and fib(2) 514229 times! (Do you see the sequence there? Math is fascinating.)
Let's make a simple attempt at storing the result of each calculation so that every subsequent time we are asked for fib(n) we look up the answer instead of calculating it:
my %fib_cache;
sub fib_cr {
my $o = shift;
die "Only natural number indexes." if($o < 0 || $o != int($o));
return $o if($o < 2);
# Here we return a cached result if one exists.
return $fib_cache{$o} if(exists($fib_cache{$o}));
# Here we cache the result and return it.
return $fib_cache{$o} = fib_cr($o-2) + $fib_cr($o-1);
}
Running fib_cr(30) on my laptop takes less than 0.01 seconds–roughly a 61000% speed up. This painfully obvious example demonstrates the value of computational reuse. This particular example's simplicity and obvious benefit are the reasons for its place as the "poster child" of computational reuse.
Real Application — Although the Fibonacci example may seem contrived, it illustrates a simple concept: It is often cheaper to store a previous calculation and retrieve it later than it is to perform the calculation again from scratch. This is true in all arenas of computer science, engineering, and life.
Integrated caches are most similar to computational reuse because the application itself attempts to remember (cache) any acquisition of data (or transformation of data) considered by the developer to be frequently used and sufficiently expensive.
Computational reuse itself can be applied directly to core application code, but when the problem is extrapolated to an architecture with multiple interdependent components, the technique evolves from computational reuse to integrated caching; and with that evolution comes complexity.
It is important to digress for a moment and understand that the gain from computation reuse is a performance gain and does not imply scalability. Computation reuse is an edict of high-performance computer programming, and although high-performance does not ensure scalability, low performance is a death warrant.
The gain from integrated caching is a step toward horizontal scalability (although not always a good step to take, as you will see). Integrated caching allows one component in an architecture to use another component less. A good example is the use of a database as the backing store for content on a website. You could query the database every time a specific page was requested, or you could cache the results and future requests would not require a database query.
The concept of an application code cache is to allow the application to store the result of an expensive operation and determine an answer to that query more quickly by referencing local data than by requerying the authoritative source (see Figure 7.3).
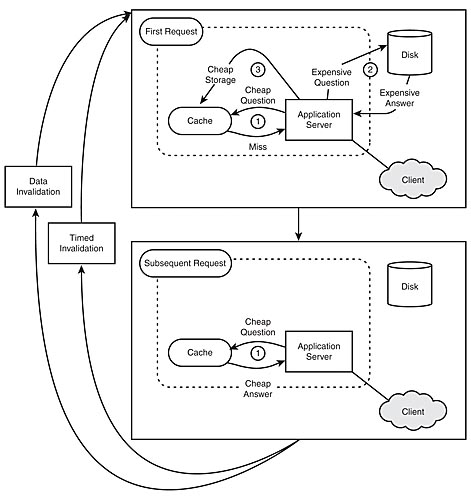
Figure 7.3: An integrated look-aside cache.
Although computational reuse is a good approach in computer programming, it makes the assumption that the result of a particular question will not change. The 19th Fibonacci number isn't going to change when we aren't looking. However, if we were to cache a user's preferences or another result of an expensive database query, the answer is likely to change when we aren't looking.
This leaves us with the challenge of architecting a cache invalidation infrastructure or "fudging it" by setting cache timeouts–basically accepting that an answer is good for some magical amount of time, and if it changes in that time, we will be stuck with the old incorrect answer.
A beautiful example of integrated caching is that which is inside recursive domain name system (DNS) servers. When I perform a lookup on www.example.com, I issue a simple question to my local recursive DNS server and expect a simple response. My DNS server must query root servers to determine who is responsible for the example.com domain and then query the responsible party–and this is the simplest case. If my DNS server did this every time I needed www.example.com, the Internet would be a wholly unsatisfying (slow) place. Instead, my DNS server caches the answer for some amount of time so that subsequent identical requests can be answered on the spot.
Why can't we use the same technique in our web applications? The technique clearly applies, but DNS has the advantage (called good engineering) that every piece of data is distributed with a time-to-live (TTL). Unlike web applications, every DNS system has insight into how long it is allowed to cache the result before it must throw away that answer as stale and then requery.
In web applications, the queries performed typically do not have an explicit TTL and the only implicit TTL for data is the life of the request itself. This means that the data changes, and we don't know how fast it will change. These circumstances make caching beyond the life of a single web request difficult to maintain and debug, and often lead to compromises that can be avoided by using data caches or write-thru caches.
Although integrated caches in their most simple form are an awkward fit for large-scale web architectures, we can use aspects of this technology combined with write-thru caches and distributed caches to realize true horizontal scalability.
Data Cache
The data cache is a simple concept. It is effectively computational reuse on a lower level than the integrated cache. With a data cache, we expect our core services (those on which the application relies) to employ computational reuse and extensive caching.
As we defined web caching, this doesn't exactly fit. The idea here is to have a database or other core service that efficiently uses a cache so that the web application can transparently benefit. The only reason that data caches are relevant is that it is possible to place a database replica on each web server and then we can more legitimately call data caching a form of web caching.
The intrinsic problem with integrated caching is that the cache is distributed and uncoordinated. If one node running the application performs an SQL query against a database and stores the answer, it has no sound way of determining whether the underlying data that formed the response has changed. As such, it has no good way of knowing whether it will receive the same answer if it issues the same question. However, one system does know whether the data has changed–the database.
We will just accept the fact that the vast majority of Internet architectures use a relational database management system (RDBMS) to store their data. All queries for that data are posed to the RDBMS, and it is responsible for answering them.
MySQL, for example, employs a data cache calling it a query cache. Essentially, it caches the complete answers to questions that are asked of it. Along with those answers it stores a reference to the data on which their accuracy depends. If that data changes, the answer is efficiently invalidated.
This is a simpler solution than an integrated cache on the web application level because a single product is in complete control of both the caching infrastructure and the authoritative data.
What does this buy you? The vast majority of data that powers Internet sites has a high read-to-write ratio, meaning that questions are asked of the database far more often than data is placed in the database. Although databases are fast and robust, they still must spend time answering queries, and that time is precious.
Write-Thru and Write-Back Caches
Write-back caches are classic computer engineering. You will find this technology in every computer processor, code optimizer, and disk drive. Any time that it is expensive to save a piece of data that is also commonly accessed, you will find a write-back cache. A write-back cache means that all modifications of data are performed on the cache. When the cache is full and entries are removed, they are then written to the backing store if needed. This simple design is depicted in Figure 7.4.
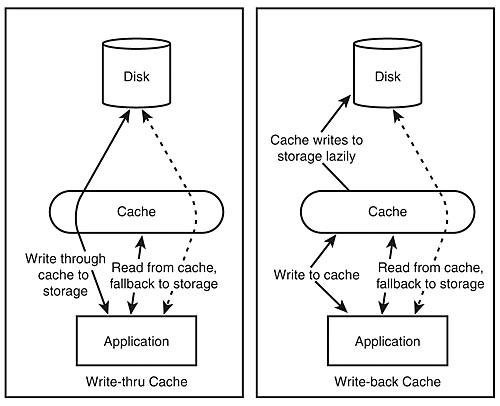
Figure 7.4: Write-thru and write-back caches.
If you stop reading here and get a cup of coffee, you should be able to come up with a few catastrophic problems with the write-back architecture.
A cache on most systems is a faster storage medium than the authoritative source for which it caches. In a web proxy cache, it is the cheap disk drive on the cheap box serving static content–no data is modified on those drives, so a failure cannot incur data loss. In a disk drive, volatile memory (DRAM) is faster than the physical disk drives. If data is written to the volatile cache on a drive and that cache operates in write-back mode, what happens when the power fails? Data does not make it back to disk, and you have inconsistency, corruption, and lost data.
Some IDE drives enable write-back cache that cannot be turned off! External RAID arrays often use write-back caches and have expensive battery units capable of keeping all the drives up and running long enough to completely journal its cache back to permanent storage.
You may be wondering how in the world you would incorporate a write-back cache paradigm in a distributed/cluster web application architecture? Well, there is certainly no good concrete example I can find. The concept does not adapt well to web systems; but, let's jump to write-back's brother named write-thru.
Write-thru caches operate in an interesting fashion. They exploit the fact that reads and writes in many systems are temporally relative. What does this mean? Reads often occur on data most recently written. A concrete example is the addition of a news article to a database. New news is read more often than old news. The news most recently added to the system will be the news most frequently requested from the system.
A write-thru cache writes the data to the cache and to the backing store knowing that a read request (or many read requests) are likely to follow for that data.
Distributed Cache
Distributed caching is a loosely defined term. Any time more than a single machine is being used to cache information you can argue that the solution is distributed. Herein, we refine our view of distributed caches to those that are collaborative. What does this really mean?
In a distributed cache, when a particular node computes and stores the results in its cache, other nodes will benefit. In effect, it is no longer "its" cache, but rather "the" cache. All the nodes participating in the cluster share a common cache where information is shared.
This sounds a lot like putting the cache in a centralized database. However, there is one distinct difference. Distributed caches are distributed, which means that the data is not stored in any single place. Typically, all data is stored at every node. Chapter 8, "Distributed Databases Are Easy, Just Read the Fine Print," touches on more complicated data replication techniques that will have information placed on some plural subset of machines within a cluster. In both situations, the data is available on the nodes that use the cache, and any single system failure will not pose a threat to availability.
Distributed systems are pretty tricky in general. What seem like simple problems at first, turn out to be complicated to solve in a general case. Let's look at a simple distributed cache that operates like a dictionary of keys and values both of which are simple strings. Caching techniques apply directly to countless technologies, but we will look at stock quotes and SSL session caching as two acutely different examples.
Simple Distributed Information Caches — For simplicity's sake, we will assume that we have real-time stock quotes feeding in from ACME Tickers. One of the services on our news site is real-time stock quotes on every page if the user opts for that in her personal preferences. We want all the information on these stock quotes on every web server so as not to stress or rely on any single point for the information. If we were to use a centralized database and it were to go down, all stock quotes would be unavailable. However, if we were to keep a cached copy on every box, and the main distribution point were to become unavailable, information would be stale but available until the distribution point was once again operational. This is a spectacular example of why people think distributed caches are easy.
In this example, changes are effected at a single point in the architecture and propagated from there. It is not the generalized case of distributed caching. It is a specific, distributed cache that operates on a one-to-many replication paradigm shown in Figure 7.5.
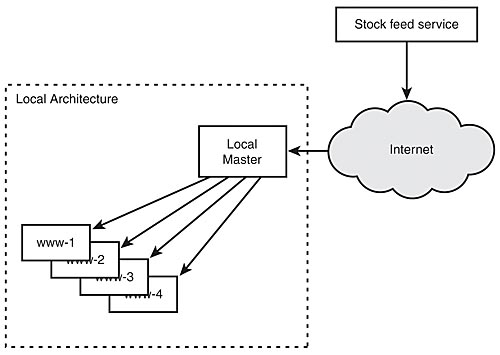
Figure 7.5: One-to-many replication for stock quotes.
This sort of information dissemination can be accomplished via asynchronous database replication (discussed in Chapter 8), as well as a simple, reliable multicast approach using a technology such as Spread.
Not-So-Simple Distributed Information Caches — Now look at an SSL session cache. When an SSL connection is established, a session key and a corresponding session context are established. When a browser has a session ID and initiates another request, if it is found in the server's session cache, an expensive asymmetric key negotiation can be avoided.
In a clustered environment where we want to capitalize on all of our resources as efficiently as possible, we want to be able to allocate a request to the machine that has the most sufficient resources to satisfy it. In a typical SSL environment, subsequent requests are often sent back to the same server to avoid expensive cryptographic computations–even if that server is overloaded.
Alternatively, the SSL session information can be placed in a distributed cache (shown in Figure 7.6) so that subsequent requests can be serviced by any machine in the cluster without unnecessary overhead induced by an "absent" SSL session.
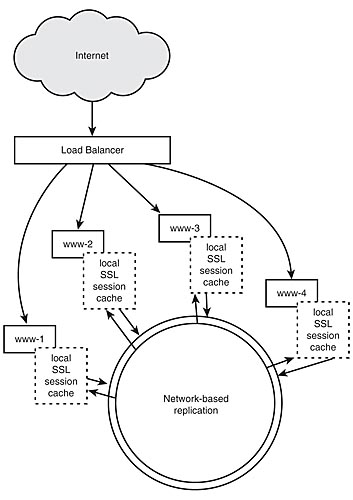
Figure 7.6: Commutative replication of SSL sessions.
This problem is distinctly different from the stock quote problem. In this system, we must publish from all participating nodes and as such, the issues of partitions and merges of the network arise.
Ben Laurie's Splash! SSL session caching system based on Spread tackles some of these issues, and Spread Concept's Replicated Hash Table (RHT) product, although it doesn't integrate directly with SSL session caching systems, tackles all the commutative replication requirements for such a distributed caching architecture.
There are two aspects of deploying caches. First, you must choose the right technology or combination of technologies to fit the problem at hand. Then you must place it in the architecture.
The true beauty of a cache is that it isn't needed for operation, just performance and scalability. As seen in Chapter 6, with the static cache, images could be served of the main site, but a cache was used for performance and scalability. If such immense scalability is no longer required, the architecture can easily be reverted to one without a caching system.
Most caching systems (except for transparent layered caches) do not have substantial operational costs, so their removal would not provide a substantial cost savings. In these cases, after an effective and efficient caching mechanism is deployed, it is senseless to remove it from the architecture unless it will be replaced by a better solution.
After that long-winded explanation of different caching technologies, we can concentrate on the only one that really applies to scalable web architectures: distributed caching. However, the concepts from write-thru caching can be cleverly applied to distributed caching for further gain.
As mentioned previously, increasing performance isn't our primary goal. Caching solutions speed up things by their very nature, but the goal remains scalability. To build a scalable solution we hope to leverage these caches to reduce contention on a shared resource. Architecting a large site with absolutely no shared resources (for example, a centralized database or network attached storage) is challenging and not always feasible.
Let's go back to our wildly popular news site www.example.com. In Chapter 6 we tackled our static content distribution problem, which constitutes the bulk of our bandwidth and requests. However, the dynamic content constitutes the bulk of the work.
So far we have talked about our news site in the abstract sense. Let's talk about it now in more detail so that you know a bit more about what it is and what it does.
Figure 7.7 displays a sample article. This page shows two elements of dynamic content:
The main article content–Including author, publication time, title, content, and reader feedback.
The left navigation bar–Each user can choose what he wants in that bar and the order in which it should be displayed.
Figure 7.7: Screenshot from our news website.
All information for the site must be stored in some permanent store. This store is the fundamental basis for all caches because it contains all the original data.
First let's look at this architecture with no caching whatsoever. There is more complete code for the examples used throughout this chapter on the Sams website. We will just touch on the elements of code pertinent to the architectural changes required to place our caches.
Note - Remember that this book isn't about how to write code; nor is it about how to build a news site. This book discusses architectural concepts, and the coding examples in this book are simplified. The pages are the bare minimum required to illustrate the concepts and benefits of the overall approach being discussed.
The concepts herein can be applied to web architectures regardless of the programming language used. It is important to consider them as methodologies and not pure implementations. This will help you when you attempt to apply them to an entirely different problem using a different programming language.
For no reason other than the author's intimate familiarity with perl, our example news site is written in perl using Apache::ASP, and an object-oriented approach was used when developing the application code. Apache::ASP is identical to ASP and PHP with respect to the fashion in which it is embedded in web pages.
Three important classes (or packages in perl) drive our news pages that display articles:
An SIA::Article object represents a news article and has the appropriate methods to access the article's title, author, publication date, content, and so on.
An SIA::User object represents a visitor to the website and has the methods to retrieve all of that visitor's personal information including website preferences such as the desired structure of the left navigation bar.
An SIA::Cookie object represents the cookie and can fetch and store information in the cookie such as the user's ID.
Simple Implementation
With these objects, we can make the web page shown in Figure 7.7 come to life by creating the following Apache::ASP page called /hefty/art1.html:
1: <%
2: use SIA::Cookie;
3: use SIA::Article;
4: use SIA::User;
5: use SIA::Utils;
6: my $articleid = $Request->QueryString('articleid');
7: my $article = new SIA::Article($articleid);
8: my $cookie = new SIA::Cookie($Request, $Response);
9: my $user = new SIA::User($cookie->userid);
10: %>
11: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
12: "http://www.w3.org/TR/html4/st
13: rict.dtd">
14: <html>
15: <head>
16: <title>example.com: <%= $article->title %></title>
17: <meta http-equiv="Content-Type" content="text/html">
18: <link rel="stylesheet" href="/css/main.css" media="screen" />
19: </head>
20: <body>
21: <div id="leftnav">
22: <ul>
23: <% foreach my $toplevel (@{$user->leftNav}) { %>
24: <li class="type"><%= $toplevel->{group} %></li>
25: <% foreach my $item (@{$toplevel->{type}}) { %>
26: <li><a href="/sia/news/page/<%= $item->{news_type} %>">
27: <%= $item->{type_name} %></a></li>
28: <% } %>
29: <% } %>
30: </ul>
31: </div>
32: <div id="content">
33: <h1><%= $article->title %></h1>
34: <h2><%= $article->subtitle %></h2>
35: <div id="author"><p><%= $article->author_name %>
36: on <%= $article->pubdate %>:</p>
37: <div id="subcontent">
38: <%= $article->content %>
39: </div>
40: <div id="commentary">
41: <%= SIA::Utils::render_comments($article->commentary) %>
42: </div>
43: </div>
44: </body>
45: </html>
Before we analyze what this page is doing, let's fix this site so that article 12345 isn't accessed via /hefty/art1.html?articleid=12345. This looks silly and prevents search indexing systems from correctly crawling our site. The following mod_rewrite directives will solve that:
RewriteEngine On RewriteRule ^/news/article/(.*).html \ /data/http://www.example.com/hefty/art1.html?articleid=$1 [L]
Now article 12345 is accessed via www.example.com/news/articles/12345.html, which is much more person- and crawler-friendly. Now that we have that pet peeve ironed out, we can look at the ramifications of placing a page like this in a large production environment.
The left navigation portion of this page is a simple two-level iteration performed on lines 22 and 24. The method $user->leftNav performs a single database query to retrieve a user's preferred left navigation configuration.
The main content of the page is completed by calling the accessor functions of the $article object. When the $article object is instantiated on line 6, the article is fetched from the database. From that point forward, all methods called on the $article object access information that has already been pulled from the database with the noted exception of the $article->commentary call on line 38. $article->commentary must perform fairly substantial database queries to retrieve comments posted in response to the article and comments posted in response to those comments, and so on.
To recap, three major database interactions occur to render this page for the user. So what? Well, we now have this code running on a web server...or two...or twenty. The issue arises that one common resource is being used, and because it is required every time article pages are loaded, we have a contention issue. Contention is the devil.
Don't take my word for it. Let's stress this system a bit and get some metrics.
Looking at Performance — We don't need to go into the gross details of acquiring perfect (or even good) performance metrics. We are not looking for a performance gain directly; we are looking to alleviate pressure on shared resources.
Let's run a simple ab (Apache Benchmark) with a concurrency of 100 against our page and see what happens. The line we will take note of is the average turn-around time on requests:
Time per request: 743 - (mean, across all concurrent requests)
This tells us that it took an average of 743ms to service each request when serving 100 concurrently. That's not so bad, right? Extrapolating this, we find that we should be able to service about 135 requests/second. The problem is that these performance metrics are multifaceted, and without breaking them down a bit, we miss what is really important.
The resources spent to satisfy the request are not from the web server alone. Because this page accesses a database, some of the resources spent on the web server are just time waiting for the database to perform some work. This is where performance and scalability diverge.
The resources used on the web server are easy to come by and easy to scale. If whatever performance we are able to squeeze out of the system (after performance tuning) is insufficient, we can simply add more servers because the work that they perform is parallelizable and thus intrinsically horizontally scalable. Figure 7.8 illustrates scalability problems with nonshared resources.
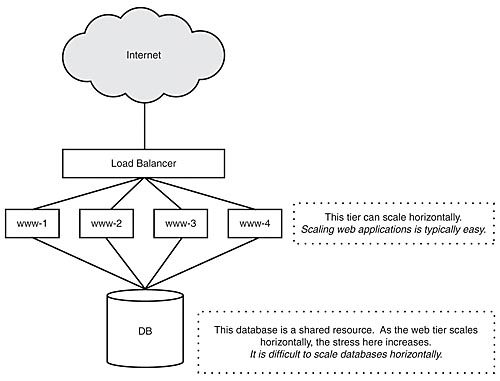
Figure 7.8: A web tier using a shared, nonscalable database resource.
On the other hand, the database is a shared resource, and, because requests stress that resource, we can't simply add another core database server to the mix. Chapter 8 discusses why it is difficult to horizontally scale database resources.
The performance metrics we are interested in are those that pertain to components of the architecture that do not scale. If we mark up our database abstraction layer a bit to add time accounting for all query preparation, execution, and fetching, we run the same test and find that, on average, we spend 87ms performing database operations. This isn't necessarily 87ms of stress on the database, but then again, that depends on perspective. One can argue that the database isn't actually working for those 87ms and that much of the time it is waiting for packets to fly across the network. However, there is a strong case to be made that during those 87ms, the client still holds a connection to the database and thus consumes resources. Both statements are true, especially for databases such as Oracle where an individual client connection requires a substantial amount of memory on the database server (called a shadow process). MySQL, on the other hand, has much less overhead, but it is still quantifiable.
Where are we going with this? It certainly isn't to try to tune the database to spend less resources to serve these requests. Although that is an absolute necessity in any large environment, that is a performance issue that sits squarely on the shoulders of a DBA and should be taken for granted when analyzing architectural issues. Rather, our goal is to eliminate most (if not all) of the shared resource usage.
Each request we passed through the server during our contrived test required 743ms of attention. Of that time, 87ms was not horizontally scalable, and the other 656ms was. That amount–87ms–may not seem like much, and, in fact, it is both small and completely contrived. Our tests were in a controlled environment with no external database stress or web server stress. Conveniently, we were simply attempting to show that some portion of the interaction was dependent on shared, nonscalable resources. We succeeded; now how do we fix it?
Introducing Integrated Caching
There are a variety of implementations of integrated caching. File cache, memory cache, and distributed caches with and without replication are all legitimate approaches to caching. Which one is the best? Because they all serve the same purpose (to alleviate pressure on shared resources), it simply comes down to which one is the best fit in your architecture.
Because our example site uses perl, we will piggyback our implementation of the fairly standard Cache implementation that has extensions for file caching, memory caching, and a few other external caching implementations including memcached.
With integrated caching, you need to make a choice up front on the semantics you plan to use for cached data. A popular paradigm used when caching resultsets from complicated queries is applying a time-to-live to the data as it is placed in the cache. There are several problems with this approach:
The result set often carries no information about the period of time over which it will remain valid.
The arbitrary timeouts provided by application developers are not always accurate.
The underlying data may be changed at any time, causing the cached result set to become invalid.
Let's look at the alternative and see what complications arise. If we cache information without a timeout, we must have a cache invalidation infrastructure. That infrastructure must be capable of triggering removals from the cache when an underlying dataset that contributed to the cached result changes and causes our cached view to be invalid. Building cache invalidation systems can be a bit tricky. Figure 7.9 shows both caching semantics.
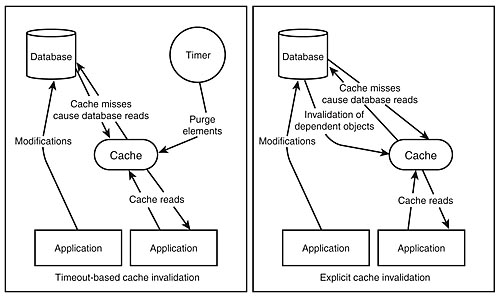
Figure 7.9: Timeout-based caches (left) and explicitly invalidated caches (right).
Basically, the two approaches are "easy and incorrect" or "complicated and correct." But "incorrect" in this case simply means that there is a margin of error. For applications that are tolerant of an error-margin in their caching infrastructures, timeout-based caches are a spectacularly simplistic solution.
If we choose a timeout for our cached elements, it means that we must throw out our cached values after that amount of time, even if the underlying data has not changed. This causes the next request for that data to be performed against the database, and the result will be stored in the cache until the timeout elapses once again.
It should be obvious after a moment's thought that if the overall application updates data infrequently with respect to the number of times the data is requested, cached data will be valid for many requests. On a news site, it is likely that the read-to-write ratio for news articles is 1,000,000 to 1 or higher (new user comments count as writes). This means that the cached data could be valid for minutes, hours, or days.
However, with a timeout-based cache, we cannot capitalize on this. Why? We must set our cache element timeout sufficiently low to allow for newly published articles to be "realized" into the cache. Essentially, the vast majority of cache purges will be wasted just to account for the occasional purge that results in a newer replacement.
Ideally, we want to cache things forever, and when they change, we will purge them. Because we control how articles and comments are published through the website, it is not difficult to integrate a cache invalidation notification into the process of publishing content.
We had three methods that induced all the database costs on the article pages: $user->leftNav, $article->new, and $article->comments. Let's revise and rename these routines by placing an _ in front of each and implementing caching wrappers around them:
sub leftNav {
my $self = shift;
my $userid = shift;
my $answer = $global_cache->get("user_leftnav_$userid");
return $answer if($answer);
$answer = $self->_leftNav($userid);
$global_cache->set("user_leftnav_$userid", $answer);
return $answer;
}
Wrapping SIA::Article methods in a similar fashion is left as an exercise for the reader.
In the startup code for our web server, we can instantiate the $global_cache variable as so:
use Cache::Memcached;
$global_cache = new Cache::Memcached {
'servers' => [ "10.0.2.1:11211", "10.0.2.2:11211",
"10.0.2.3:11211", "10.0.2.4:11211" ],
'debug' => 0,
};
Now we start a memcached server on each web server in the cluster and voila! Now, as articles and their comments are requested, we inspect the cache. If what we want is there, we use it; otherwise, we perform the work as we did before, but place the results in the cache to speed subsequent accesses. This is depicted in Figure 7.10.
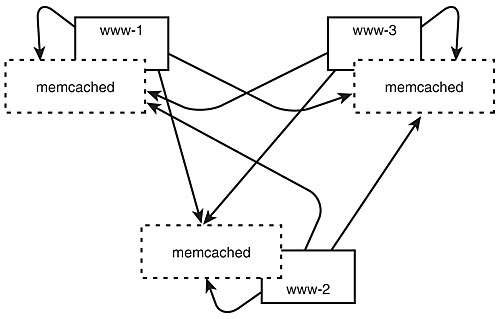
Figure 7.10: A memcached cluster in use.
What do we really gain by this? Because our data is usually valid for long periods of time (thousands or even millions of page views), we no longer have to query the database on every request. The load on the database is further reduced because memcached is a distributed caching daemon. If configured as a cluster of memcached processes (one on each machine), items placed into the cache on one machine will be visible to other machines searching for that key. Because it is a cache, if a machine were to crash, the partition of data that machine was caching would disappear, and the cache clients would deterministically failover to another machine. Because it is a cache, it was as if the data was prematurely purged–no harm, no foul.
We have effectively converted all the article queries to cache hits (as we expect our cache hit rate for that data to be nearly 100%). Although the cache hit rate for the user information is not as high, the data is unique per user, and the average user only visits a handful of pages on the site. If the average user visits five pages, we expect the first page to be a cache miss within the $user->leftNav method. However, the subsequent four page views will be cache hits, yielding an 80% cache hit rate. This is just over a 93% overall cache hit rate. In other words, we have reduced the number of queries hitting our database by a factor of 15–not bad.
How Does memcached Scale? — One of the advantages of memcached is that it is a distributed system. If 10 machines participate in a memcached cluster, the cached data will be distributed across those 10 machines. On a small and local-area scale this is good. Network connectivity between machines is fast, and memcached performs well with many clients if you have an operating system with an advanced event handling system (epoll, kqueue, /dev/poll, and so on).
However, if you find that memcached is working a bit too hard, and your database isn't working hard enough, there is a solution. We can artificially segment out memcached clusters so that the number of nodes over which each cache is distributed can be controlled (see Figure 7.11).
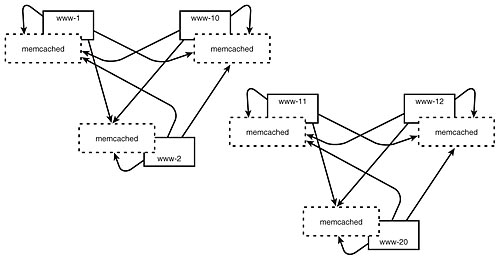
Figure 7.11: An artificial segmented memcached system.
This administrative segmentation is useful when you have two or more clusters separated by an expensive network link, or you have too many concurrent clients.
Healthy Skepticism — We could stop here. Although this is an excellent caching solution and may be a good stopping point for some caching needs, we have some fairly specialized data that is ripe for a better caching architecture. The first step is to understand what is lacking in our solution up to this point. Two things are clearly missing: We shouldn't have to go to another machine to fetch our article data, and the cache hit rate on our user preferences data is abysmally low.
Unfortunately, memcached isn't replicated, so these accesses still require a network access. If N machines participate in the memcached cluster, there is only 1/N chance that the cached item will reside on the local machine, so as the cluster size grows, the higher the probability that a cache lookup will visit a remote machine. Memcached counts on local network access to another machine running memcached is cheaper than requerying the database directly. Although this is almost always true, "cheaper" doesn't mean "cheapest," and certainly not free.
Why is lack of replication unfortunate? The article data will have nearly a 100% cache hit rate, and it is accessed often. This means that every machine will want the data, and nearly every time it gets the data, it will be identical. It should be a small mental leap that we can benefit from having that data cached locally on every web server.
For Those Who Think Replication Is Expensive - Many argue that replicating data like this is expensive. However, both active and passive replications are possible in this sort of architecture.
The beauty of a cache is that it is not the definitive source of data, so it can be purged at will and simply be "missing" when convenient. This means that replication need not be atomic in many cases.
Simply propagating the cache by publishing the cache operations (add/get/delete) to all participating parties will work most of the time. Propagation of operations as they happen is called active replication.
Alternatively, in a nonreplicated distributed system such as memcached, we find that one machine will have to pull a cache element from another machine. At this point, it is essentially no additional work to store that data locally. This is passive replication (like cache-on-demand for caches). Passive caching works well with timeout-based caches. If the cached elements must be explicitly invalidated (as in our example), active replication of delete and update events must still occur to maintain consistency across copies.
Because we are not dealing with ACID transactions and we can exercise an "if in doubt, purge" policy, implementing replication is not so daunting.
As an alternative to memcached, Spread Concept's RHT (Replicated Hash Table) technology accomplishes active replication with impressive performance metrics.
These simplistic replication methods won't work if operations on the cache must be atomic. However, if you are using a caching facility for those types of operations, you are likely using the wrong tool for the job–in Chapter 8 we will discuss replicated databases.
What else isn't optimal with the integrated caching architecture? The user information we are caching has an abysmally low cache hit rate–80% is awful. Why is it so bad? The problem is that the data itself is fetched (and differs) on a per-user basis. In a typical situation, a user will arrive at the site, and the first page that the user visits will necessitate a database query to determine the layout of the user's left navigation. As a side effect, the data is placed in the cache. The concept is that when the user visits subsequent pages, that user's data will be in the cache.
However, we can't keep data in the cache forever; the cache is only so large. As more new data (new users' navigation data, article data, and every other thing we need to cache across our web architecture) is placed in the cache, we will run out of room and older elements will be purged.
Unless our cache is very large (enough to accommodate all the leftnav data for every regular user), we will end up purging users' data and thereby instigating a cache miss and database query upon subsequent visits by those users.
Tackling User Data
User data, such as long-term preferences and short-term sessions state, has several unique properties that allow it to be cached differently from other types of data. The two most important properties are use and size:
The use of the data usually only has the purpose of shaping, transforming, or selecting other data. In our left navigation system, the user's preferences dictate which of the navigation options should be displayed and in what order to display them. This does not change often and is specific to that user.
The size of the data is usually less than a few kilobytes, often between 100 and 500 bytes. Although it can take some creative measure to compact the representation of the data into as little space as possible, you will soon see how that can be wonderfully beneficial.
Now, because this is still the chapter on application caching, we still want to cache this. The problem with caching this data with memcached is that each piece of user data will be used for short bursts that can be days apart. Because our distributed system is limited in size, it uses valuable resources to store that data unused in the cache for long periods of time. However, if we were to increase the size of our distributed system dramatically, perhaps the resources will be abundant and this information can be cached indefinitely...and we just happen to have a multimillion node distributed caching system available to us–the machine of every user.
The only tricky part about using a customer's machine as a caching node is that it is vital that only information pertinent to that customer be stored there (for security reasons). Cookies give us this.
The cookie is perhaps the most commonly overlooked jewel of the web environment. So much attention is poured into making a web architecture's load balancing, web servers, application servers, and databases servers fast, reliable, and scalable that the one layer of the architecture that is the most powerful and very scalable is simply overlooked.
By using a user's cookie to store user-pertinent information, we have a caching mechanism that is user-centric and wildly scalable. The information we store in this cache can also be semipermanent. Although we can't rely on the durability of the information we store there, we can, in most cases, rely on a long life. Again, this is a cache; if it is lost, we just fetch the information from the authoritative source and replace it into the cache.
To accomplish this in our current article page, we will add a method to our SIA::Cookie class that is capable of "acting" just like the leftNav method of the SIA::User class, except that it caches the data in the cookie for the user to store locally. We'll need to pass the $user as an argument to leftNav in this case so that method can run the original action in the event of an empty cookie (also known as a cache miss). We'll add the following two methods to our SIA::Cookie package:
sub setLeftNav {
my ($self, $ln) = @_;
my $tight = '';
foreach my $toplevel (@$ln) {
$tight .= "\n" if(length($tight));
$tight .= $toplevel->{group}."$;";
$tight .= join("$;", map { $_->{news_type}.",".$_->{type_name} }
@{$toplevel->{type}});
}
($tight = encode_base64($tight)) =~ s/[\r\n]//g;
$self->{Response}->Cookies('leftnav', $tight);
return $ln;
}
sub leftNav {
my ($self, $user) = @_;
my $tight = $self->{Request}->Cookies('leftnav');
return $self->setLeftNav($user->leftNav) unless($tight);
$tight = decode_base64($tight);
my @nav;
foreach my $line (split /\n/, $tight) {
my ($group, @vals) = split /$;/, $line;
my @types;
foreach my $item (@vals) {
my ($nt, $tn) = split /,/, $item, 2;
push @types, { news_type => $nt, type_name => $tn };
}
push @nav, { group => $group, type => \@types };
}
return \@nav;
}
We now copy /hefty/art1.html to /hefty/art2.html and change it to use these new SIA::Cookie methods by replacing the original line 22:
22: <% foreach my $toplevel (@{$user->leftNav}) { %>
with one that incorporates the $cookie->leftNav method invocation:
22: <% foreach my $toplevel (@{$cookie->leftNav($user)}) { %>
You don't really need to understand the code changes as long as you understand what they did and what we gain from them and their size (a mere 31 new lines, and 1 line of change).
SIA::Cookie::setLeftNav executes our original $user->leftNav, serializes the results, base64 encodes them (so that it doesn't contain any characters that aren't allowed in cookies), and sends it to the user for permanent storage.
SIA::Cookie::leftNav checks the user's cookie, and if it is not there, calls the setLeftNav method. If it is there, it base64 decodes it and deserializes it into a useable structure.
In our original design, our application required a database query on every page load to retrieve the data needed to render the left navigation bar. With our first stab at speeding this up using integrated caching, we saw good results with an approximate 80% cache hit rate. Note, however, that the database queries and cache lookups stressed a limited number of machines that were internal to the architecture. This contention is the arch enemy of horizontal scalability.
What we have done with cookies is simple (32 lines of code) but effective. In our new page, when a user visits the site for the first time (or makes a change to her preferences), we must access the database because it is a cache miss. However, the new caching design places the cached value on the visitor's machine. It will remain there forever (effectively) without using our precious resources. In practice, aside from initial cache misses, we now see a cache hit rate that is darn near close to 100%.
Addressing Security and Integrity — Because this is a cache, we are not so concerned with durability. However, the nature of some applications requires that the data fed to them to be safe and intact. Any time authentication, authorization, and/or identity information is stored within a cookie, the landscape changes slightly. Although our news site isn't so concerned with the security and integrity of user preferences, a variety of other applications impose two demands on information given to and accepted from users.
The first demand is that a user cannot arbitrarily modify the data, and the second is that the user should not be able to determine the contents of the data. Many developers and engineers avoid using a user's cookie as a storage mechanism due to one or both of these requirements. However, they do so wrongly because both issues can be satisfied completely with cryptography.
In the previous example, immediately before base64 encoding and after base64 decryption, we can use a symmetric encryption algorithm (for example, AES) and a private secret to encrypt the data, thereby ensuring privacy. Then we can apply a secure message digest (for example, SHA-1) to the result to ensure integrity.
This leaves us with a rare, but real argument about cookie theft (the third requirement). The data that we have allowed the user to store may be safe from both prying eyes and manipulation, but it is certainly valid. This means that by stealing the cookie, it is often possible to make the web application believe that the thief is the victim–identity theft.
This debacle is not a show-stopper. If you want to protect against theft of cookies, a time stamp can be added (before encrypting). On receiving and validating a cookie, the time stamp is updated, and the updated cookie is pushed back to the user. Cookies that do not have a time stamp with X of the current time will be considered invalid, and information must be repopulated from the authoritative source, perhaps requiring the user to reauthenticate.
Two-Tier Execution
Now that we have user preferences just about as optimal as they can get, let's move on to optimizing our article data caching. We briefly discussed why our memcached implementation wasn't perfect, but let's rehash it quickly.
Assuming that we use memcached in a cluster, the data that we cache will be spread across all the nodes in that cluster. When we "load balance" an incoming request to a web server, we do so based on load. It should be obvious that no web server should be uniquely capable of serving a page, because if that web server were to crash that page would be unavailable. Instead, all web servers are capable of serving all web pages.
So, we are left with a problem. When a request comes in and is serviced by a web server, and when it checks the memcached cache for that request, it will be on another machine n-1 times out of n (where n is the number of nodes in our cluster). As n grows, the chance of not having the cached element on the local machine is high. Although going to a remote memcached server is usually much faster than querying the database, it still has a cost. Why don't we place this data on the web server itself?
We can accomplish this by an advanced technique called two-tier execution. Typically in a web scripting language (for example, PHP, ASP, Apache::ASP, and so on), the code in a page is compiled and executed when the page is viewed.
Compilation of scripts is a distributed task, and no shared resources are required. Removing the compilation step (or amortizing it out) is a technique commonly used to increase performance. PHP has a variety of compiler caches including APC, Turk MMCache, PHP Accelerator, and Zend Performance Suite. Apache::ASP uses mod_perl as its underlying engine, which has the capability to reuse compiled code. Effectively, recompiling a scripted web page is more of a performance issue than one of scalability, and it has been solved well for most popular languages.
Execution of code is the real resource consumer. Some code runs locally on the web server. XSLT transforms and other such content manipulations are great examples of horizontally scalable components because they use resources only local to that web server and thus scale with the cluster. However, execution that must pull data from a database or other shared resources takes time, requires context switches, and is generally good to avoid.
So, if we have our data in a database and want to avoid accessing it there, we stick it in a distributed cache. If we have our data distributed cache and want to avoid accessing it there, where can be put it? In our web pages.
If we look back at our /hefty/art2.html example, we see two types of code executions: one that generates the bulk of the page and the other that generates the left navigation system. So, why are they so different? The bulk of the page will be the same on every page load, no matter who views it. The left navigation system is different for almost every page load. This is the precise reason that a transparent caching solution will not provide a good cache hit rate–it is only capable of caching entire pages.
To eliminate database or cache requests for the main content of the page, we could have the author code the page content directly into the HTML. Is this an awful idea? Yes. Authors do not need to know about the page where the data will reside; they should concentrate only on content. Also, the content (or some portion of the content) will most likely be used in other pages. It is simply not feasible to run a news site like the old static HTML sites of the early 90s.
However, we can have the system do this. If we augment our scripting language to allow for two phases of execution, we can have the system actually run the script once to execute all the slowly changing content (such as article information and user comments) and then execute the result of the first execution to handle dynamic content generation that differs from viewer to viewer.
To accomplish this, we will do three things:
Write a /hefty/art3.html page that supports our two-tier execution.
Write a small two-tier page renderer that stores the first phase execution.
Use mod_rewrite to short-circuit the first phase of execution if it has been performed already.
1: <%
2: use SIA::Article;
3: use SIA::Utils;
4: my $articleid = $Request->QueryString('articleid');
5: my $article = new SIA::Article($articleid);
6: %>
7: <[%
8: use SIA::User;
9: use SIA::Cookie;
10: my $cookie = new SIA::Cookie($Request, $Response);
11: my $user = new SIA::User($cookie->userid);
12: %]>
13: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
14: "http://www.w3.org/TR/html4/strict.dtd">
15: <html>
16: <head>
17: <title>example.com: <%= $article->title %></title>
18: <meta http-equiv="Content-Type" content="text/html">
19: <link rel="stylesheet" href= "/sia/css/main.css" media="screen" />
20: </head>
21: <body>
22: <div id="leftnav">
23: <ul>
24: <[% foreach my $toplevel (@{$cookie->leftNav($user)}) { %]>
25: <li class="type"><[%= $toplevel->{group} %]></li>
26: <[% foreach my $item (@{$toplevel->{type}}) { %]>
27: <li><a href="/sia/news/page/<[%= $item->{news_type} %]>">
28: <[%= $item->{type_name} %]></a></li>
29: <[% } %]>
30: <[% } %]>
31: </ul>
32: </div>
33: <div id="content">
34: <h1><%= $article->title %></h1>
35: <h2><%= $article->subtitle %></h2>
36: <div id="author"><p><%= $article->author_name %>
37: on <%= $article->pubdate %>:</p>
38: <div id="subcontent">
39: <%= $article->content %>
40: </div>
41: <div id="commentary">
42: <%= SIA::Utils::render_comments($article->commentary) %>
43: </div>
44: </div>
45: </body>
46: </html>
As you can see, no new code was introduced. We introduced a new script encapsulation denoted by <[% and %]>, which Apache::ASP does not recognize. So, upon executing this page (directly), Apache::ASP will execute all the code within the usual script delimiters (<% and %>), and all code encapsulated by our new delimiters will be passed directly through to the output.
We will not ever directly execute this page, however. Our renderer is responsible for executing this page and for transforming all <[% and %]> to <% and %> in the output, so that it is ready for another pass by Apache::ASP. This intermediate output will be saved to disk. As such, we will be able to execute the intermediate output directly as an Apache::ASP page:
<%
use strict;
use Apache;
die "Direct page requests not allowed.\n" if(Apache->request->is_initial_req);
my $articleid = $Request->QueryString('articleid');
# Make sure the article is a number
die "Articleid must be numeric" if($articleid =~ /\D/);
# Apply Apache::ASP to our heavy template
my $doc = $Response->TrapInclude("../hefty/art3.html");
# Reduce 2nd level cache tags to 1st level cache tage
$$doc =~ s/<\[?(\[*)%//%$1>/gs;
# Store our processed heavy tempalate to be processed by Apach::ASP again.
my $cachefile = "../light/article/$articleid.html";
if(open(C2, ">$cachefile.$$")) {
print C2 $$doc; close C2;
rename("$cachefile.$$", $cachefile) || unlink("$cachefile.$$");
}
# Short circuit and process the ASP we just wrote out.
$Response->Include($doc);
%>
Now for the last step, which is to short-circuit the system to use /light/article/ 12345.html if it exists. Otherwise, we need to run our renderer at /internal/render.html?articleid=12345. This can be accomplished with mod_rewrite as follows:
RewriteEngine On
RewriteCond %{REQUEST_URI} news/article/(.*)
RewriteCond /data/http://www.example.com/light/$1 -f
RewriteRule $news/(.*) /data/http://www.example.com/light/$1 [L]
RewriteRule ^news/article/(.*).html$
/data/http://www.example.com/internal/render.html?articleid=$1 [L]
Cache Invalidation — This system, although cleverly implemented, is still simply a cache. However, it caches data as aggressively as possible in a compiled form. Like any cache that isn't timeout-based, it requires an invalidation system.
Invalidating data in this system is as simple as removing files from the file system. If the data or comments for article 12345 have changed, we simply remove /data/ www.exmaple.com/light/article/1.html. That may sound easy, but remember that we can (and likely will) have these compiled pages on every machine in the cluster. This means that when an article is updated, we must invalidate the cache files on all the machines in the cluster.
If we distribute cache delete requests to all the machines in the cluster, we can accomplish this. However, if a machine is down or otherwise unavailable, it may miss the request and have a stale cache file when it becomes available again. This looks like a classic problem in database synchronization; however, on closer inspection, it is less complicated than it seems because this data isn't crucial. When a machine becomes unavailable or crashes, we simple blow its cache before it rejoins the cluster.
Two things should be clear by now. First, caching systems vary widely in their implementation, approach, and applicability. Second, on analysis you can determine which caching approach is right for a specific component to achieve dramatic improvements with respect to both performance and scalability.
In our original article page we witnessed three substantial database operations on every page. After implementing a variety of dynamic caching solutions we were able to achieve an acceptably high cache-hit rate (nearly 100%) and all but eliminate database queries from our pages. After users log in for the first time, their left navigation preferences are stored in their cookie, and it is unlikely that they will ever lose their cookie and require a database query to reset it. Articles data, which once required two queries to retrieve, are now compiled into a valid web page to be served directly by Apache, alleviating both database access and the dependency on an external caching mechanism.
Although the examples in this chapter are implemented in perl using the Apache::ASP embedding system, all the caching techniques presented can be implemented using almost any interpreted scripting language. The goal was to present concepts. Aside from the two-tier execution approach, all the concepts presented can be implemented in any language and in any architecture–even outside the Web.
The key to successful caching is understanding the true nature of your data: how frequently it is changed and where it is used.
