
Podcasting for the Penguin!
Kelly Penguin Girl and I have been producing the weekly GNU/Linux User Show podcast (www.linuxuser.thepodcastnetwork.com) since June 2005. We're just about to hit show #30, which I think makes us one of the oldest running GNU/Linux podcasts aimed specifically at new GNU/Linux users. We've moved on to other things and no longer host the show, but it's been a long, fun journey, and we've learned a lot.
The technical aspects of podcasting on GNU/Linux are on par with podcasting on any other OS, but there are some cultural differences. Podcasting to the Free/Libre/Open-Source Software (FLOSS) community requires a sensitivity of the community's values. In short, a podcaster that intends to podcast to the FLOSS community should really be part of the community. The community wants to be talked with, not talked at. Trespassers will be shot.
We record our shows on either a Kanotix or Linspire box (depending on where we are in the house) using a set of $25 US NeXXt headsets and two pairs of Y-cables. We thought about getting a mixer, but so far the Y-cables have performed flawlessly, so we don't see the need to spend the extra money on unnecessary gear.
I always find it quizzical why so many podcasters recommend spending $200 US or more on gear. We've spent less than $100 US since day one on three sets of headsets and a standalone microphone. One of the lessons that blogging has taught us is that content is king, not the pretty bells and whistles around the content. Although there is certainly a minimum level of quality expected by listeners, the content is what drives the show, not the benefits of shiny microphones and mixers.
Application-wise, we use Audacity to record and edit the show, and EasyTag to insert the ID tags in preparation for file upload.
The real workhorse of our show is Audacity. Audacity is a wonderful digital audio workstation (DAW) application that is not only licensed under the GNU GPL and available on SourceForge, but it is also available for all major OS platforms. Audacity has served us well for recording our shows, editing the audio streams, adding effects, importing and aggregating other audio streams and formats, and finally allowing us to export our show in a variety of different formats. Audacity supports Ogg Vorbis encoding out of the box, and it will support MP3 encoding via the LAME encoder (separate download).
One of the killer features of Audacity is the wide range of audio formats it is capable of importing. Over time, we've had to incorporate audio from many sources, such as individual listeners, promo clips from advertisers, audio clips from other shows and downloaded clips from the Internet. Without Audacity's ability to import everything we've thrown at it, we would have been dead in the water many times over.
We generally record the show in many parts. Some are recorded days apart, and some only seconds apart. Regardless, Audacity represents each of these parts as a graphic sound wave, and each of these waves can be manipulated individually (Figure 1).
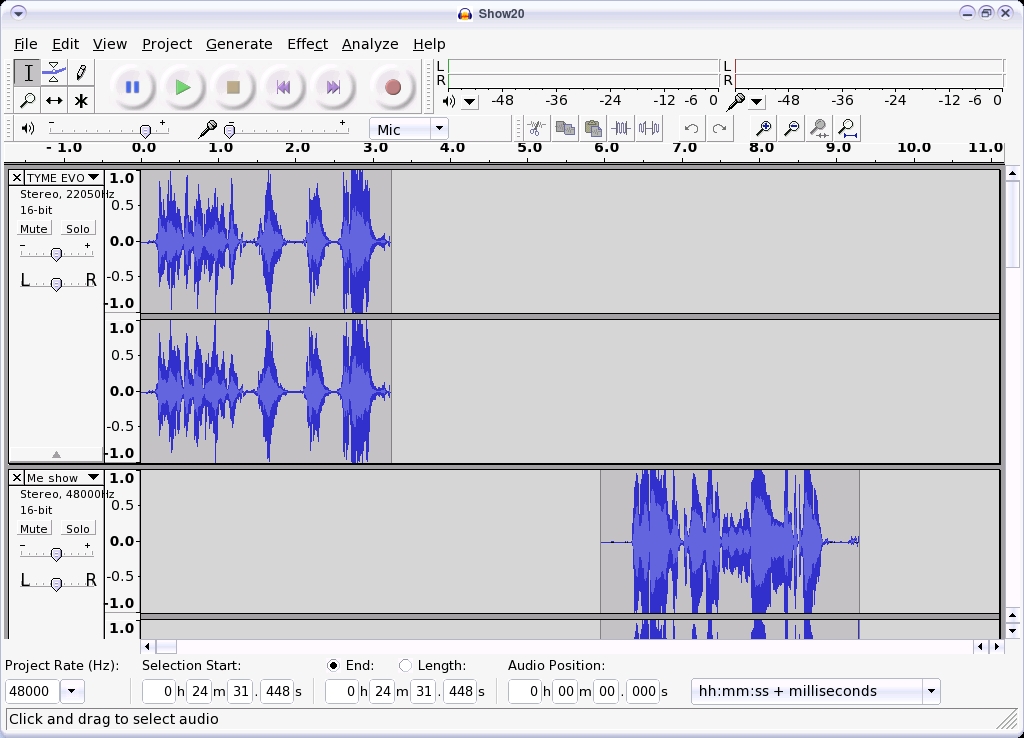
Figure 1. Audacity is the workhorse of this podcast.
This intuitive feature makes the post-production of our shows a snap. The tools we use the most are the time-shifter, which allows movement of individual audio parts to snug them up together and kill any dead space, and the insert silence tool. The insert silence tool may sound innocuous, but it's very handy for extending little dead spots to fit around another sound clip.
Audacity also features a very complete set of options that allow granular control of the final audio file quality and size (Figure 2).
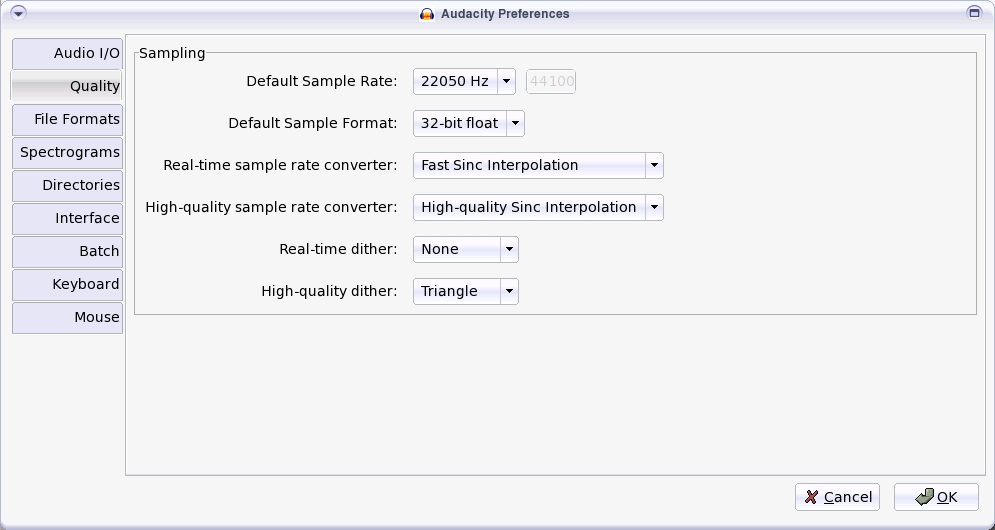
Figure 2. Speech doesn't need the 44KHz sample rate associated with music.
Podcasts generally are mostly speech and can therefore be exported at low quality without any appreciable degradation. The Podcast Network's standard is 48Kbps and 22KHz. We used to put out only MP3s of our show, but after Richard M. Stallman came on lucky show #13 and asked us also to produce Ogg Vorbis files, we started doing that as well. It took me a while to understand the Ogg Vorbis compression technique, and our first few Oggs were twice as big as the same show's MP3 file. That didn't make us very popular, let me tell you! Here's the secret: in Audacity, there is no bit rate setting for Ogg Vorbis files. Rather, there is a slider from 0 to 10. A setting of 0, although counter-intuitive, creates a perfectly usable Ogg Vorbis file.
Once the show is created and exported, it's critical to put the ID tags into the file. The ID tags provide the information that scrolls across the screen of listeners' digital audio players (DAP) or their digital audio applications. Without ID tags, listeners would be hard pressed to figure out what show and episode they're listening to. This information isn't necessary only for logistics, it's also critical for promoting your podcast. Listeners can't come back to find your next show if they don't know what the heck they're listening to.
Audacity has the ability to manage ID tags, but supports only a few fields. The Podcast Network standards required us to supply data for more than those few fields. Therefore, we had to turn to an external tagging application.
We went through a few different tagging applications and finally settled on EasyTag. EasyTag is a nice application that does one thing and does it well. It tags the heck out of Ogg Vorbis and MP3 files. EasyTag is GNU GPL'd and also available from SourceForge.
There's a real science to tagging podcasts and EasyTag has many more features than we use. Along with the basic functionality of embedding IDv2 and IDv3 tags in both MP3 and Ogg Vorbis files, EasyTag can be set to scan entire directories of audio files and auto-fill in the tags. Because we produce a podcast only once a week, we don't have a lot of use for these advanced features. But, if I had a hard drive full of nontagged music files, EasyTag's scanning feature would be very, very useful.
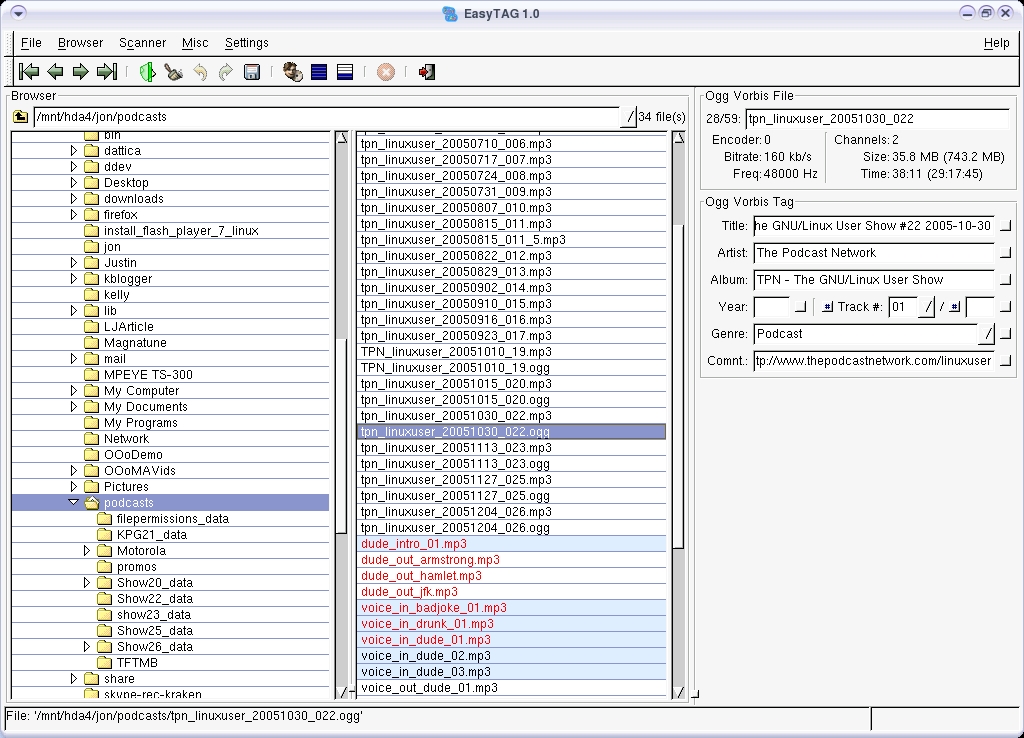
Figure 3. The name EasyTag is appropriate as it makes tagging our MP3 and Ogg files so easy.
Aside from the technical aspects of tagging files, there are many different schools of thought on what information should go in to each tag. Most audio players scroll the title, artist and length of the file at a minimum across the screen while playing. Although the title and artist are generally pretty easy to figure out, the title tag requires more thought. Some podcasters put the name of the show and the date it was produced into the title tag. Others feel that the sequence number of show is more important than the date. Both sides typically argue that it's easier for a listener to keep track of a (sequence number or date) than a (date or sequence number).
This argument was likely more important in the beginning of podcasting, because podcatching software wasn't as advanced as it is now. What makes a podcast a podcast is that it is delivered via an RSS feed. An MP3 (or Ogg file) that is just linked to download on a Web page is just an audio file on the Web, not a podcast. Podcatcher is the affectionate name given to the genre of software that listeners can use to subscribe to these RSS feeds. Once you subscribe to a podcast, the podcatcher should check each show for new episodes and download them automatically. There are varying degrees of complexity in today's podcatchers, but most offer at least the check and download new episodes functionality.
One of the more popular GNU/Linux podcatchers is BashPodder [see Marcel Gagné's article on page 32 for more information on BashPodder] written by Linc Fessenden of The Linux Link Tech Show. Along with the basic BashPodder, Linc also wrote BPGUI, which is a nice GUI front end for the command-line BashPodder client. In true community fashion, Linc released BashPodder under the GNU GPL, and many people have made modifications to the base application. A quick Google search for the term BashPodder shows the wide variety of improvements and changes the community has made to it. Whatever your taste, it's likely that you will be able to find a flavour of BashPodder that meets your needs.
The stable of podcatchers for GNU/Linux is growing as podcasting becomes more popular. CastPodder [see Marcel Gagné's article on page 32 for more on CastPodder] is another popular podcatcher, and even amaroK has podcatching capabilities.
I cannot stress enough that content is what listeners tune in for. Audio quality is important, but it's not the Holy Grail. Good guests, solid content, credible hosts and regular production are what build an audience.
Happy podcasting!
Jon Watson is the host of the weekly GNU/Linux User Show on The Podcast Network. Jon has written articles for Really Linux, Linux Journal, has been interviewed on the topic of podcasting for Alberta Venture Magazine and is slated to speak at the Calgary Linux User Group Linuxfest in spring of 2006. In his spare time, Jon also writes the New Linux User (www.newlinuxuser.com) blog for b5 Media (www.b5media.com) and can be contacted at me@jonwatson.ca. Jon lives with his fiancée and co-host Kelly Penguin Girl in mountainous Calgary, Alberta, Canada.

