
The Ultimate Linux/Windows System
I recently converted my Toshiba notebook computer into a dual-boot system, running Windows XP Pro and Ubuntu Linux. I was hoping I'd be able to use cross-platform applications such as Mozilla Firefox, Mozilla Thunderbird, AbiWord, Gnumeric and SciTE transparently, no matter which operating system was currently booted. This article describes the steps I took to make this possible.
In what follows, I assume you already have a dual-boot computer that has a working Linux and Windows operating system installed. You also must have an adequately sized additional disk partition for storing shared application data. This partition must be readable and writable by both operating systems. FAT32 (VFAT) is the logical choice.
My notebook came with Windows XP Pro installed on a 30GB hard drive. The computer was well used, its disk nearly filled, before I decided to convert it to a dual-boot system. I offloaded lots of data, and used the Windows defragment program to reduce my total Windows size below 15GB. Then, I used utilities on the Linux System Rescue CD to resize the original Windows partition and make new partitions as follows:
Partition 1: Windows NTFS primary partition, 18.5GB.
Partition 2: Linux ext3 primary partition, 5GB.
Partition 3: Linux swap partition, 1GB.
Partition 4: FAT32 partition for shared application data, 5GB.
Making a dual-boot system with only 30GB of total disk space is not ideal. My shared application data partition was 80% full once I loaded my archived e-mail, working documents and various ongoing cross-platform software development projects. For a more ideal setup, I recommend at least 60–80GB of disk space. In that case, I'd allocate 20GB for Windows, 10GB for Linux, 1–2GB for Linux swap and make the remainder the FAT32 shared partition.
Windows views a FAT32 partition as a separate disk drive and assigns it a drive letter. The letter assigned depends on what storage devices are connected to the system—for example, floppy or CD/DVD drives. On my system, Windows identifies the FAT32 partition as drive E:. Use Windows Explorer to verify the Windows drive letter for your FAT32 partition.
When I installed Ubuntu Linux, I selected mounting the FAT32 partition at boot time, using the mountpoint /share. After Linux boots, you can verify that the FAT32 partition is mounted with the UNIX df command (Listing 1).
Listing 1. UNIX df Command Showing Mounted /share Partition
kevin@lyratoshibaubuntu:~$ df -k Filesystem 1K-blocks Used Available Use% Mounted on /dev/hda2 5036316 1748816 3031668 37% tmpfs /dev/shm 184936 0 184936 0% tmpfs /dev/hda1 184936 12588 172348 7% /lib/modules/2.6.12-9-386/volatile /dev/hda1 18427896 9955608 8472288 55% /media/hda1 /dev/hda4 4713876 417898 4295978 9% /share
Although the /share partition is mounted, there is a problem. By default, the the root user owns the /share partition. A standard user will not have read or write permission, and will not be able to run programs that access the shared data. Fortunately, the UNIX mount command provides options for a partition to be mounted with ownership set to a user other than root. This is one method for enabling you to read and write the shared partition using your normal login.
If only one person uses the computer, or only one user needs access to the shared partition, the best plan is to mount the /share partition at boot time, but with your login provided with ownership and full access rights. To configure this, you need to know your user ID and group ID. The /etc/passwd file stores this information. Here's the entry for my user name (kevin) in my /etc/passwd file:
kevin@lyratoshibaubuntu:~$ cat /etc/passwd | grep kevin kevin:x:1000:1000:kevin,,,:/home/kevin:/bin/bash
The user ID is the number after the second colon. The group ID is the number after the third colon. The example shows that user kevin is assigned user ID 1000 and group ID 1000 on my system.
Now, you must edit the /etc/fstab file. This filesystem table identifies the filesystems the booting Linux system can expect to see, and instructs Linux on what actions to take for each filesystem. You need to switch to the root user account to edit the file.
First, make a backup copy of the current working /etc/fstab file, so you can revert to that version if something goes wrong. Next, bring the fstab file into an editor, such as vi, emacs, gedit or scite. Find the line for the /share file system, and change the data in the <options> column to defaults,uid=uuuu,gid=gggg where uuuu and gggg are your user ID and group ID from /etc/passwd.
Your finished /etc/fstab file should look something like Listing 2.
Listing 2. /etc/fstab File with Boot-Time Mounting of the Shared Partition, Giving Ownership to a Specific User
kevin@lyratoshibaubuntu:~$ cat /etc/fstab # /etc/fstab: static file system information. # # <file system> <mount point> <type> <options> <dump> <pass> proc /proc proc defaults 0 0 /dev/hda2 / ext3 defaults,errors=remount-ro 0 1 /dev/hda1 /media/hda1 ntfs defaults 0 0 /dev/hda4 /share vfat defaults,uid=1000,gid=1000 0 0 /dev/hda3 none swap sw 0 0 /dev/hdc /media/cdrom0 udf,iso9660 user,noauto 0 0
If multiple user accounts need to access the shared partition, you need a different strategy. One option is not to mount the /share partition at boot time, but instead make a script that users execute to mount the partition giving themselves ownership and full access.
To disable mounting /share at boot time, edit /etc/fstab and place a # at the start of the /share filesystem line. This makes the line a comment. Then, find the user ID and group ID in /etc/passwd for each user who requires full access to the /share partition. Finally, place a script file similar to the following into the home directory of each user, inserting each user's user ID and group ID after uid= and gid=, respectively:
kevin@lyratoshibaubuntu:~$ cat mountShare.csh sudo mount -t vfat -o uid=1000,gid=1000 /dev/hda4 /share
After logging in to Linux, the user opens a terminal window and executes the command script to mount the FAT32 partition with the needed access settings:
bash ./mountShare.csh
However the shared partition is mounted, you can verify that you have ownership and full access to the /share directory with a long listing of path /:
kevin@lyratoshibaubuntu:~$ ls -l / | grep share drwxr-xr-x 18 kevin kevin 4096 1969-12-31 19:00 share
At this point, you are ready to use applications that run on both Windows and Linux to do work on documents stored in your shared application data space. If I'm working under Windows, I store and access my documents using drive E:. Again, the drive letter for the FAT32 partition may be different on your system. If I'm working under Linux, I store and access the same documents in my /share partition.
Before you start editing documents, make sure you have the same version of each application installed on Windows and Linux. Don't just hope there are no configuration or data file structure changes between two different releases of an application.
I use Mozilla Firefox as my Web browser and Mozilla Thunderbird as my e-mail client. Before I converted my notebook into a dual-boot system, I had run Firefox for a long time, and it had many bookmarks. I also had multiple years of saved e-mail messages. Naturally, with my new dual-boot system, I wanted to run Firefox using all of my previously saved bookmarks, and I wanted to be able to use Thunderbird transparently in Windows and Linux, having full access to all my archived e-mail.
Is this possible? Thanks to the configuration strategy employed by the Mozilla Suite developers, the answer is “yes”! Both Firefox and Thunderbird organize their configurations via profiles. Each profile is stored in its own subdirectory, which by default is located beneath the top-level configuration directory for the application. The name and location of each profile is stored in an index file named profiles.ini. This structure gives us the flexibility to store the configuration data for any profile in any disk location accessible to the user—for example, on our FAT32 shared application data partition.
Before you make any configuration changes, make sure Firefox and Thunderbird are not running. Then, create a directory on the shared partition where your Mozilla application configuration data will be stored for access by both Windows and Linux. I chose to make a users directory with a subdirectory named kevin, my user name under both operating systems. This is convenient if I decide later to have multiple users on the system. In that case, I'll make a separate path for each user's unique configuration data, so that the logged in user accesses and maintains his or her own configuration.
Under Windows, the path to my application configuration directory is E:\users\kevin. Under Linux, the path is /share/users/kevin.
For reference, I performed my Firefox shared configuration using Firefox Version 1.5. However, the procedures also should work with 1.0.x versions of Firefox.
My Windows Firefox installation contained all my personal bookmarks and other configuration settings, so I reconfigured that Firefox first. In Windows, find the Application Data directory for your user name beneath the Documents and Settings directory. You should see a directory named Firefox that has a subdirectory named Profiles. The Profiles directory will have at least one subfolder. Here's how it looks on my system:
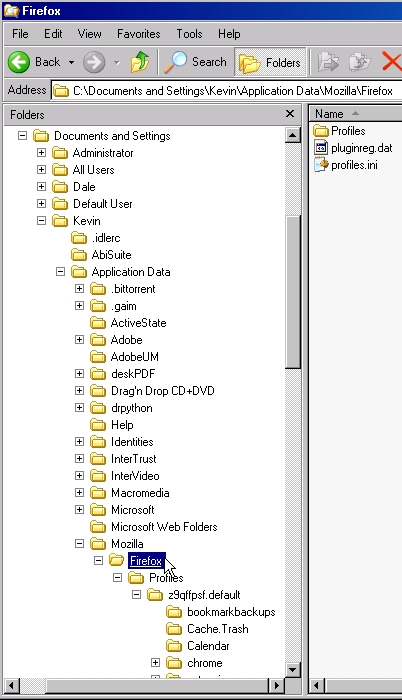
Figure 1. Windows Firefox Application Data Folder Location and Structure
The profiles.ini file tells Firefox where to find its configuration data. Open profiles.ini in an editor, and you should see something like this:
[General] StartWithLastProfile=0 [Profile0] Name=default IsRelative=1 Path=Profiles/z9qffpsf.default Default=1
This profiles.ini file identifies my configuration as having a single profile, with the configuration data located in the folder Profiles/z9qffpsf.default, relative to the directory where profiles.ini is located. Looking at the folder tree in Figure 1, you can see the Profiles/z9qffpsf.default folder, with various subfolders. This is the location of all of my unique Firefox configuration information. This is the data I want to be able to access (read and write), whether I am booted in Windows or Linux. In your own Firefox installation, the *.default folder will have a different name. You need to substitute the name of your own profile directory as you perform the steps described below.
To make my configuration data available to both operating systems, I made a Firefox\Profiles directory beneath my shared E:\users\kevin directory, then copied the original Firefox Profiles\z9qffpsf.default configuration directory to that path. Figure 2 shows the result.
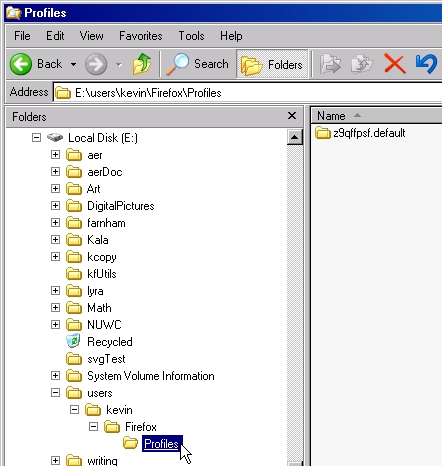
Figure 2. Moved Firefox Configuration Directory
I renamed the original z9qffpsf.default directory on my C: drive to maintain a backup copy in case of unanticipated disaster.
Next, I edited profiles.ini to point to the new location of the Firefox configuration profile. I set the IsRelative flag to zero and the Path location to the shared partition location where I copied the configuration folder. When setting the path, make sure you use Windows-style backslashes. Otherwise, Windows Firefox won't recognize the new location. Here's my edited profiles.ini file:
[General] StartWithLastProfile=0 [Profile1] Name=default IsRelative=0 Path=E:\users\kevin\Firefox\Profiles\ z9qffpsf.default
I saved a copy of this file as profiles_new.ini, so I could return to it in case something went wrong on my first try.
When you've got all of this complete, launch Firefox. If a window pops up asking if you want to import settings from another browser, something is incorrect in your setup. In this case, Firefox will have overwritten the profiles.ini file and created a new default configuration directory. Check your backup copy of your new profiles.ini file and the directory names on the shared partition, make any necessary corrections, re-save your corrected profiles.ini file, and try launching Firefox again. When you have all the configuration elements correct, Firefox launches as it always did, with all of your bookmarks available.
Now, Linux Firefox must be configured to use the same profile. Boot in to Linux and mount the shared partition using one of the described methods. In Linux, Firefox stores the configuration files beneath a user's home in directory .mozilla. Go into this directory, then into the firefox subdirectory, and execute ls -l. You'll see a profiles.ini file, the pluginreg.dat file and a configuration profile subdirectory.
To make the Linux Firefox use the configuration profile that was placed onto the shared partition, edit the profiles.ini file. Set the IsRelative flag to zero, and set the Path to the correct /share location. Here's my modified Linux profiles.ini file:
[General] StartWithLastProfile=1 [Profile0] Name=default IsRelative=0 Path=/share/users/kevin/Firefox/Profiles/ z9qffpsf.default Default=1
Start Firefox. If all is correct, you'll see your standard Firefox session with all the bookmarks you originally stored using Windows Firefox available. If this doesn't happen, check the profiles.ini file again, make certain the /share partition is mounted correctly, with proper ownership and permissions, and verify the exact path to the shared Firefox configuration directory. Replace profiles.ini with your corrected version, and launch Firefox again.
The configuration organization for Thunderbird is similar to that for Firefox. For reference, I made my shared configuration using Thunderbird Version 1.0.7.
In Windows, find the Thunderbird directory beneath Application Data in the Documents and Settings directory tree for your user name. You might think the Thunderbird directory would be beneath Mozilla, parallel to the Firefox directory, but this wasn't the case on my system. In the Thunderbird directory, you'll see the familiar profiles.ini file and a Profiles folder, as with Firefox.
To make all of your stored e-mail accessible from both your Windows and Linux installations, the configuration folder must be moved to the shared partition. I made a directory \users\kevin\Thunderbird on my shared partition and copied the Profiles directory from the default Windows location into the new shared directory. In my case, the view from Windows Explorer looks like Figure 3.
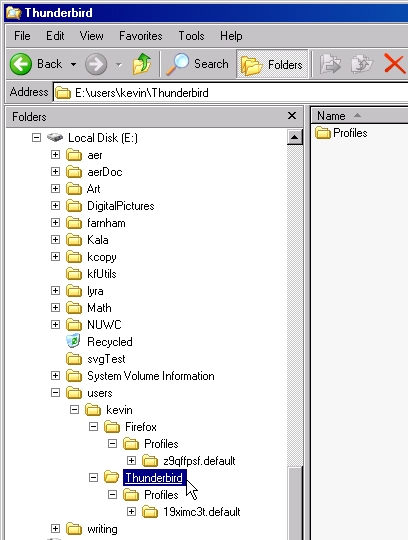
Figure 3. Moved Windows Thunderbird Configuration Directory
I renamed my original configuration directory to have a backup and also to be certain that it would no longer be accessed by my operational Windows Thunderbird.
Next, I changed the profiles.ini file to point to the new Thunderbird application data location. My initial profiles.ini looked like this:
[General] StartWithLastProfile=1 [Profile0] Name=default IsRelative=1 Path=Profiles/19ximc3t.default
I changed IsRelative to zero and set Path to the new Thunderbird location on the shared partition, switching the path directory separators to Windows standard backslashes. Here's my modified file:
[General] StartWithLastProfile=1 [Profile0] Name=default IsRelative=0 Path=e:\users\kevin\Thunderbird\Profiles\ 19ximc3t.default
When you've done all of this, start Thunderbird. If everything has been modified correctly, Thunderbird starts normally. If the configuration is not correct, Thunderbird will ask about creating a new profile. In this case, cancel and exit the program, check your new profile.ini file and the location of the Thunderbird files on the shared partition. Correct any problems, then run Thunderbird again.
On Linux, you'll find the Thunderbird profiles.ini file in the directory .mozilla-thunderbird, beneath your home directory. Edit profiles.ini to identify the configuration you set up from Windows on the shared partition as the profile Thunderbird should use. Again, set IsRelative to zero and Path to the shared location. Here's my modified Linux Thunderbird profiles.ini file:
[General] StartWithLastProfile=1 [Profile0] Name=default IsRelative=0 Path=/share/users/kevin/Thunderbird/Profiles/ 19ximc3t.default Default=1
Launch Thunderbird, and you should have full access to all your e-mail accounts and all the e-mail messages that were saved originally by Thunderbird running on Windows. If Thunderbird asks about creating a new profile, exit and check your work.
Having a dual-boot Linux and Windows notebook is convenient. The convenience is extended by sharing application data between both operating systems. Being able to run Mozilla Firefox and Thunderbird transparently from both Linux and Windows further enhances a dual-boot system's versatility.
Although a large number of steps are required to create the shared configuration, the individual steps are not difficult for someone familiar with locating, copying and editing files and directory structures in both the Windows and Linux operating systems.
Resources for this article: /article/8954.
Kevin Farnham works primarily on software engineering projects involving document indexing, mathematical modeling and simulation, and scientific data acquisition, analysis and presentation. His company, Lyra Technical Systems, Inc., is located in rural Northeastern Connecticut.
