
Writing a Program to Control OpenOffice.org, Part 1
The growing use of office automation programs poses a new problem for software programmers. In fact, users are no more satisfied with programs able to give them the requested data. Graphic presentations not only must be clear, they also must be agreeable and, as it were, fascinating. This is an understandable exigency, because word processors and spreadsheets are widely used, and they allow users to attain good results rather easily, aesthetically speaking. On the other hand, small- and medium-sized software houses can't afford to spend thousands of man-hours trying to compete with Lotus or OpenOffice.org. A good solution is to exploit competitors' services.
Two basic ways are available to invoke these services. The first one requires us to write some procedures, using languages such as VBA or Star Basic, and then make the service supplier process them. The other option is to rely on interprocess communication technologies. The second solution is, in my opinion, the better one from a programmer's point of view.
Once we have decided on our strategy, we must choose the instruments to make it work: an office automation suite and a communication standard. I have opted to use OpenOffice.org and UNO. The first element is well known and my choice is easily justifiable--OOo is reliable, widely used and cross-platform. But what about UNO? UNO, short for Universal Network Objects, is an interprocess communication technology designed by OpenOffice.org and Sun to allow software developers to control the programs that form the homonymous product.
The aim of this series of articles is to explain the UNO programming principles. To accomplish this goal, we will build an application written in C++ that is able to connect to OpenOffice.org, open a spreadsheet and then update, print and close the document. The problems that must be solved in order to build the source code will allow beginners to understand the basic principles of this technology. These problems are:
installing the OpenOffice.org software development kit
building the files to implement the communication process with OpenOffice.org
understanding the basic structure of UNO: what are services, service-factories and interfaces?
writing the source code
writing a Linux makefile
The first three points are treated here in Part 1 of this article series.
Currently, no compiler is UNO compliant. We therefore need a software development kit (SDK), a set of programs and libraries allowing Java, C++ and Star Basic developers to use UNO.
UNO is available for Linux, Windows and Solaris. The software prerequisites for Linux users are:
OpenOffice.org 1.1.x or higher
JDK 1.4.1_01 or higher
GNU GCC; releases 2.91.x, 2.95.x, 3.0.x, 3.1.x, 3.2.x work fine. The 3.3.x ones cause some runtime compatibility problems; these will be discussed in a future article
GNU make 3.79.1 or higher
In addition, although it is not indispensable, I suggest installing stlport; otherwise, managing the Standard Template Library could present some problems. stlport is available here.
The UNO installation process is simple and includes three steps. First, download the SDK tar file, which is available here. Second, rebuild the tar archives. Third, configure some environment variables. The most important variables are OO_SDK_HOME, the SDK installation directory, and OFFICE_HOME, the OpenOffice.org installation directory. This configuration task can be performed by a pair of batch files, stored in the SDK base directory. The first file asks users for the right values to assign to the variables and then writes them to the second file, setsdkenv_linux. The second file must be called to carry out the whole operation. In this regard, we have to be aware that the configuration process performed by setsdkenv_linux effects only the terminal window in which it is executed.
Like CORBA and COM, UNO does not refer to a particular programming language. In order to define data and services, it uses the UNO Interface Definition Language (UNOIDL), a meta-language similar to ATL and CORBA IDL. The UNOIDL files, with the .idl extension, are stored in OpenOffice sdk directory/idl. Each of them describes an interface or a service. They are similar to source code, in that procedures and applications can't directly call them. That is why the OOo SDK supplies a collection of software instruments able to translate UNOIDL files, making them usable by C++ or Java programs. Here, we solve the problem from the point of view of C++ programmers.
First of all, we must use the .idl files as a base to write the header files we need. The programs that allow us to reach our goal must be called from the command line and are idlc, regmerge and cppumaker, in this order. For more about these development tools, read OpenOffice sdk directory/docs/toolsl.html.)
The first program, idlc, is a compiler and has the following syntax:
idlc [-options]file1.idl ... filen.idl
For each .idl file, idlc creates a binary one with the .urd (UNO reflection data) extension. The structure of .urd files is a tree of classes, where the base class is the root. All the .urd files must be merged in one .rdb (registry database) file, which we refer to when we write the C++ code. Building this registry is the task of regmerge, which also can work with rdb files. Its syntax is:
regmerge <registry_file_name> <start_level> file1 ... filen
Here is an example:
regmerge prova.rdb / prova1.urd regmerge prova.rdb / prova2.rdb
All the levels of prova1.urd and prova2.rdb--the / means we start from the root of the trees--are merged in prova.rdb. The .rdb files are binary, as are the .urd ones, but we can read their structures using a program called regview.
Finally, cppumaker builds our header files, starting from a registry. More precisely, cppumaker writes one file each interface, organizing them in a tree of the directory that reflects the .urd files inner structure. Its syntax is:
cppumker [-options] file1 file2 ... filen
Two options often are used with cppumaker. -O specifies the starting path of the header files, while -B is used to choose the starting level of the registry file, usually UCR.
To write all the header files referring to prova.rdb, starting from the current directory, we enter:
cppumaker -BUCR -O. prova.rdb
We must compile every service and interface called by our application. This is a long and error-prone process, because of the great number of files it involves. We can make this operation briefer by using two OpenOffice registry files, services.rdb and types.rdb. They are located in OpenOffice directory/program. regmerge can merge them in one registry file that later can be processed by cppumaker. Doing it this way gives us a registry bigger than we need, but in my opinion, the saved time is worth this price.
Thus, there are two types of files; .idl files describe data and services, while binary ones implement those data and services. Therefore, we can argue that UNO has two layers, one for each kind of file. After this preliminary comment, though, we have to study the UNO terminology. In my opinion, this is pivotal because we can't fully understand the source code we are going to write without knowing the meaning that words such as service, interface, propriety and service manager have in UNO (see the Developer's Guide in OpenOffice sdk directory/docs/DevelopersGuide/DevelopersGuide.html).
I think that services are the best starting point, as they are linked directly to the well-known concept of objects. The authors of the above mentioned guide often use the word service as a synonymn for object. However, there is a clear difference between the two terms. While an object is the instance of a class, a service is the abstract description of an object. More precisely, according to the Guide, "A service comprises a set of interfaces and properties that are needed to support a certain functionality. It can include other services as well. Services are abstract specifications which have to be implemented." A simile can make this concept clearer. Let's consider flow charts. They are able to describe algorithms by using graphic symbols, without taking care of problems such as memory allocation or runtime crashes. They are abstract, and we can't use them directly, but they give us all the directives we need to build up executable programs. But we could say almost the same for services; they are mere descriptions. The abstract adjective which refers to services, suggesting to that they are not able to do anything; their only function is to expose some interfaces and properties, accessible through the methodologies described below.
The above definition mentions interfaces and properties, too. An interface is a collection of methods describing an aspect of its own service, to make it actual. Generally speaking, it is a class and its implementation depends on programming languages. Instead, when we refer to a set of service characteristics, each of them defined by a name-value pair, we call them properties. Two general methods, getPropertyValue and setPropertyValue, allow us to interact with properties. For example, Figure 1 shows two services, com.sun.star.document.OfficeDocument and com.sun.star.text.TextDocument, with their interfaces.
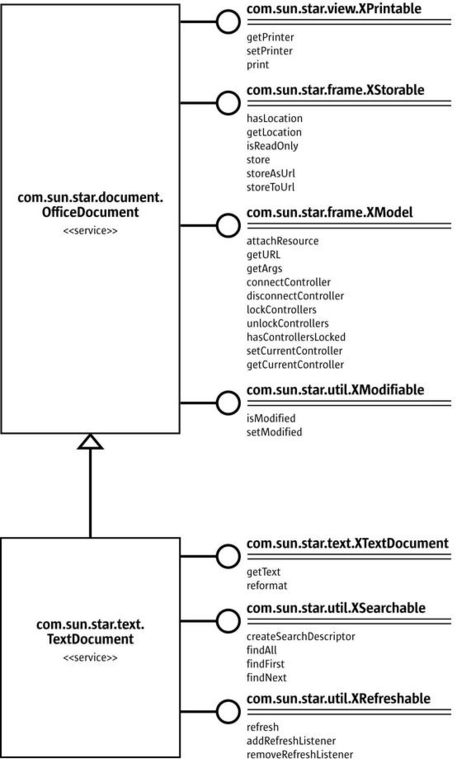
Figure 1. Two Services and Their Interfaces
But how can we build a new service? This is the service manager task, also known as the service factory. As the name suggests, the service factory can be seen as services that build other services. Service factories need to know the name of the service to be created and no more. At first glance, the very idea of a service factory is useless, as it forces the programmer to write some extra code.
And the same criticism is applicable to the concept of services themselves: why don't we replace services with directly implementable classes? These objections are not groundless, but introducing services and service managers largely improves the flexibility of UNO architecture for two reasons. First, not using service managers would mean transforming services in instantiable classes. Therefore, if OOo programmers updated a service, they would have to write again the entire code of the respective class and modify the architecture of UNO. As we just said, service managers create services based only on their names. Second, services describe what must be done, not how it must be done. Every detail about the actual execution of a task is under the care of interfaces; that is, they rely on a different software layer. Writing new releases of the code is simple, because updating a particular interface does not affect its service.
Services and service managers play an important role in the communication between two processes. Two services belonging to two different processes can exchange information by way of TCP/IP, building what is called a bridge in the UNO environment, but only if both of them have been created by a service factory. Therefore, for this communication process to work, the OpenOffice.org suite has to act as a TCP/IP server, which implies that, at startup, it must listen to a port. To achieve this aim, we have to modify the configuration file OpenOffice directory/share/registry/data/org/openoffice/Setup.xcu (see the Developer's guide). For instance, in order to make OOo listen to port 8100 of the local computer, we have to add the following lines within the <node oor:name="Office"> section.
<prop oor:name="ooSetupConnectionURL"> <value>socket,host=localhost,port=8100;urp;StarOffice.ServiceManager </value> </prop>
To summarize, UNO has a two-layer structure. Services and service factories make up the first layer. It depends on neither the operating system nor the programming language, and it has only a descriptive function. The second layer, however, relies on interfaces and properties. It therefore depends on both the operating system and the programming language, and it actually implements services.
In Part 2, we will learn how to write the source code.
