
Echo and Soft VoIP PBX Systems
Most of us have experienced telephone calls with disturbing echoes on the line. Low echo volumes together with discernible delay can make a line completely unusable, with the call being terminated after the exchange of a few halting sentences. Traditionally, problems with echo have been experienced on long-distance or international calls, particularly those involving satellite connections.
For many people new to software-based VoIP telephony systems, such as Asterisk, the phenomenon of voice echo comes as an unpleasant surprise. This is true even for those who come to the business after working with traditional PBX systems or proprietary VoIP equipment. Suddenly echo is a problem on local calls, and the traditionally troublesome long-distance and satellite calls are completely echo-free.
In this article, we discuss the origins of echo and how it manifests itself in the VoIP world with particular reference to Asterisk and other software-based telephony systems.
Echo in telephony systems is caused by two main phenomena: the first is electrical echo due to imperfect impedance matching, and the second is acoustic echo due to microphone pickup of audio output. Both these sources produce similar effects and have to be treated similarly. The major difference is electrical echo is a property of the line connection and remains mostly constant throughout the call, while acoustic echo varies in strength and delay depending on the changing acoustic environment of the echo source. For instance, on a hands-free cell-phone call, the echo characteristics change as the speaker moves around.
Electrical signals of all types always are reflected at line terminations, except when the load at the line end exactly matches the impedance rating of the line itself. In fact, the meaning of, say, “75-ohm cabling” is precisely that in order to have no signal reflections, the cable must be terminated by a 75-ohm load. Line impedance is a property of the cable that is affected only by the cable geometry. As no cables are geometrically perfect over their length and no load impedance is perfectly accurate, there always is some reflection at a line termination.
Where digital signals are concerned, as long as the reflections are a small enough fraction of the data transmission, the reflections do not cause errors in reading the bit values. Thus, digital systems can tolerate considerable echo.
The human ear has quite different characteristics, however; it is an incredibly sensitive instrument. The softest sound that can be heard has an acoustic power about a hundred thousand billion times smaller than the power at the threshold of pain. As long as sounds vary by only about a factor of 100 or so, the ear hears a similar level of sound. So even what electrically looks like a small reflection can sound about the same volume as the original signal to the human ear.
And, the traditional telephone circuits are far from perfect. Two-wire circuits from analog lines terminate at devices called hybrids that convert the two-wire analog signal to four-wire signals before digitization. The loads at the hybrids vary quite widely, as does the impedance of the low-cost subscriber loop wiring. The result is almost every call that involves an analog telephone anywhere in the circuit has electrical reflections that can be interpreted by the ear as troublesome echoes.
If this is so, why is echo not a problem on every call? The answer is, if the echo is heard at the same time as the caller is speaking, it is heard as part of the side tone and goes unnoticed. Echo becomes noticeable only when there is a delay between speaking and hearing your voice echoed. This is why echo is a problem only for traditional telephony over long distances. The round-trip delay on a coast-to-coast US call is more than 30ms, which is enough for echo to cause irritation. Satellite delays are much longer still.
VoIP intrinsically has packetization, depacketization and processing delays built into its protocols. That is why, from the point of view of echo, every VoIP call is like a very long-distance call.
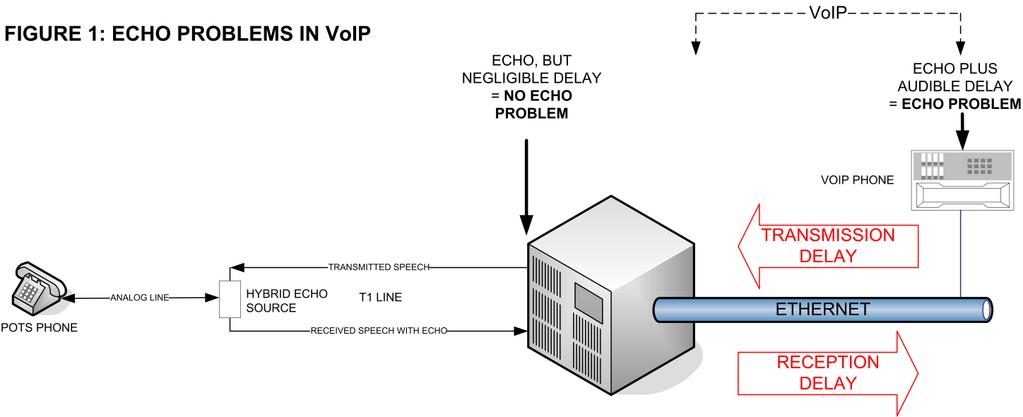
Figure 1. How VoIP and Analog Telephone Systems Interact to Cause Troublesome Echo
Figure 1 shows a typical VoIP scenario. The echo is heard on the VoIP phone: the caller on the analog line hears only a normal side tone, because there are no signal delays. Because delay is a necessary component of perceived echo, traditional PBXes that switch analog or T1/E1 traffic have no perceived echo problems, as their intrinsic end-to-end delay is low. It is the packetization and processing delays inherent in VoIP that cause existing echo to become a problem.
Those of you who have watched old black-and-white movies depicting long-distance conversations may remember the callers shouting into the mouthpieces in order for the other party to repeat what was said. The reason the callers had to shout was low receiver volume. The attenuated volume was the way echo was dealt with before powerful digital processing was available. The signal heard by a listener was attenuated considerably by the equipment. The echo passed through the attenuator twice—once on the way out and once on the way back—and this provided a measure of echo reduction. The use of attenuation to eliminate echo was not a satisfactory solution, and this method was abandoned when digital echo cancellation became available. However, the technique still is valuable in the soft PBX world as a mechanism for getting rid of the echo that remains after the somewhat limited software echo cancellers have done their job.
Digital echo cancellation is based on subtracting from the received signal a correction based on the response of the system to a short spike of sound, called the finite impulse response (FIR). The FIR is simply the echo you would hear from a short ping.
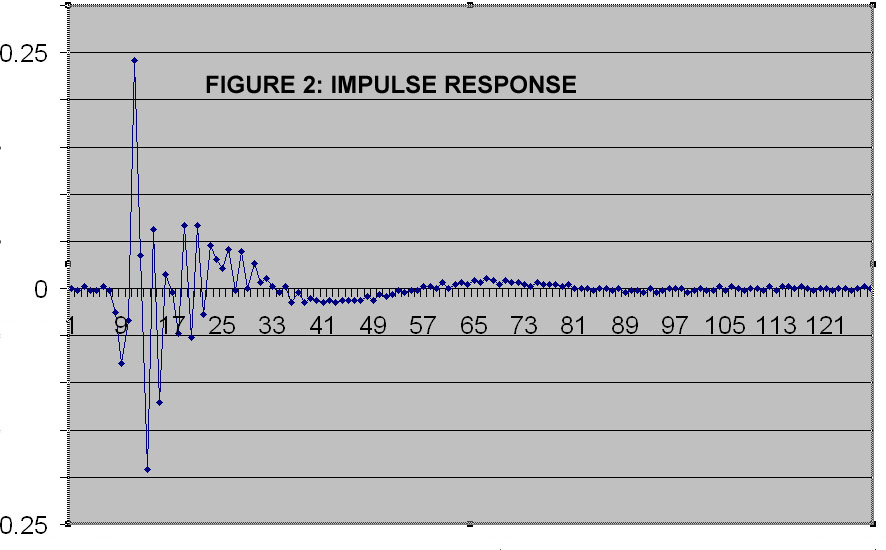
Figure 2. The Response of a Typical System to a Unit Impulse
Figure 2 shows 128 digital sound samples or taps taken at a rate of 8,000 times per second, covering 128/8 = 16 milliseconds. The impulse occurred at time zero. The dots represent the individual sample values that have been normalized to an impulse size of 1.
The first thing to notice is the echo does not appear to be very strong. The impulse had a value of 1, and the highest peak in the response is less than 0.25, falling rapidly to tiny values. But because of the sensitivity of the ear, the echo produced by this system sounds almost as loud as the spoken voice, resulting in a completely intolerable echo on a VoIP system.
The echo from the impulse has an effect that lasts about 10ms (80 taps). To cancel out the echo properly, the input from all the nonzero taps needs to be taken into account. This is why the number of taps in an echo canceller is important. The number of taps is always a power of 2: 32, 64, 128, 256 and so on. Naturally, the higher the number of taps, the higher the computing load and memory requirement.
This echo starts at tap 7, or about 1ms after the impulse. The delay is due to switching and transmission delays on the digital and analog lines. You can see why it is important that echo cancellation takes place close to the echo source. If this echo were being cancelled at the far end of a transatlantic call, there would be many more leading idle taps, so the true echo would be shifted back, perhaps right out of the tap sample. When echo is heard on a system with good echo cancellation, it usually is because an unexpectedly complex system has switching and transmission delays that have shifted the FIR backwards out of the tap sample.
For this call, beyond about 70 taps, the echo tail is small. In practice, this echo canceller would be about as effective at 64 taps, particularly if the leading 8 taps were eliminated by better buffering. That would cut the echo cancellation computation load by half.
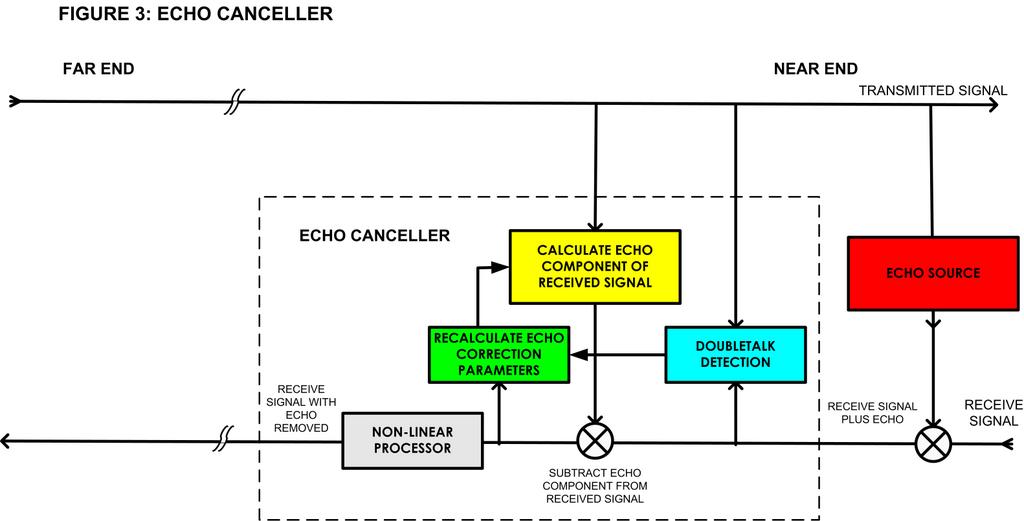
Figure 3. A Typical Echo Canceller
The FIR is used to calculate a series of correction factors that represent the echo component of the received signal. Mathematically, the echo to be subtracted for each voice sample is given by the dot product of two vectors of dimension equal to the number of taps. On a 128-tap echo canceller, for example, it would look like this:
Echo = (128 values of FIR) ⋅ (128 previous tap samples of transmission)
By subtracting this “echo” from the signal as received, a substantially echo-free receive signal is obtained. However, because of rounding errors and non-linearities, some of the echo remains. The nonlinear processor cuts out the remaining received signal if the signal is small enough. In higher-performance echo cancellers, the nonlinear processor then substitutes “comfort noise”, background noise so the line does not sound dead.
Obtaining the FIR is an iterative training process based on measuring the residual signal after the calculated echo has been subtracted and changing the FIR estimate. This process requires silence on the other end of the line—there is no doubletalk. The doubletalk detector detects when both parties are speaking at the same time and disables the FIR optimization process until the doubletalk condition has ceased. The iterative FIR optimization converges quite slowly, but as the calculations are done 8,000 times per second, within a second or two of the start of a call, a good echo canceller will be fully trained.
Echo cancellation is a hugely CPU-intensive process. A complete echo canceller for 92 simultaneous calls, or four PRI T1 lines, consumes on the order of one GIPS. The calculations involve mainly 8-bit operations, and in other ways are not optimum for the PC architecture or CPU cache. Thus, software echo cancellation is one of the major factors limiting the performance of soft PBX systems.
In an effort to improve overall system performance, software echo cancellers are usually highly optimized to reduce the PC load. One compromise made in the interest of saving CPU cycles is that the “learning” algorithms that update the FIR estimate are not run every time a voice sample is processed, but much less frequently. So the system trains slowly. You often hear quite considerable echo well into the conversation until the echo canceller trains and the echo decreases.
Another of the trade-offs is the absence of a nonlinear processor, which often is eliminated completely in soft echo cancellers. This is why there is usually some residual echo on systems such as Asterisk, even after training.
The goal under Asterisk was to provide software echo cancellation for a full quad E1 card (120 channels) with current PC technology and still be able to do other useful voice and data processing. This is indeed possible, but as discussed, the echo canceller trains slowly and after training there is still usually some remaining echo.
You can use the old-fashioned attenuation method to reduce residual echo. The transmit and receive gain settings in Asterisk (txgain and rxgain) can be set to negative values that reduce the sound volumes, but also produce acceptable final echo performance. One limitation is the txgain and rxgain settings in Asterisk are global, meaning the gain settings are compounded for any system with bridging. For bridged TDM systems, it is hard to get the balance between voice volume and residual echo right. But for simpler systems, setting txgain = –10 or thereabouts usually produces acceptable call volume with little perceived echo after about 10 seconds.
The remaining problem under Asterisk is the slow convergence of the FIR estimation. An ingenious mechanism for dramatically improving the convergence time of the echo canceller is Asterisk's echo training option. Transmitted voice is disabled for a short time during ringing and a spike of sound is transmitted to measure the FIR directly instead of learning it iteratively over many samples. The echo training option eliminates most of the echo at the beginning of the call in many cases. But its use is restricted to simple systems where ringing can be detected. It does not function on PRI T1 or E1 lines.
Today, all long-distance calls over 600km routinely are echo-cancelled at each end. Cell-phone calls to the PSTN always are echo-cancelled. Calls originating from digital end points, such as ISDN or VoIP, should have no echo. Thus, only analog calls over distances less than 600km actually need any echo cancellation. Even local calls often are echo-cancelled by the PSTN, simply because the capacity is there.
The result is that on most VoIP-PSTN gateways, including Asterisk, a great deal of echo cancellation goes on that is unnecessary and, in fact, detrimental to voice quality. For example, a VoIP-based call center may handle mostly 1-800 calls, the majority being long-distance ones that require no echo cancellation.
Although it is complicated and computationally intensive to cancel echo, it turns out that it is quite easy to measure whether echo is present on a call (Figure 4). A simple algorithm built into a Field Programmable Gate Array can measure within a second or two of speech whether echo cancellation is required for the call. If the call has no echo, echo cancellation can be disabled. Thus, for a system using hardware echo cancellation in DSPs, it is possible to allocate DSP resources dynamically to the calls that need them. But the really dramatic improvements are seen in systems with software echo cancellation.
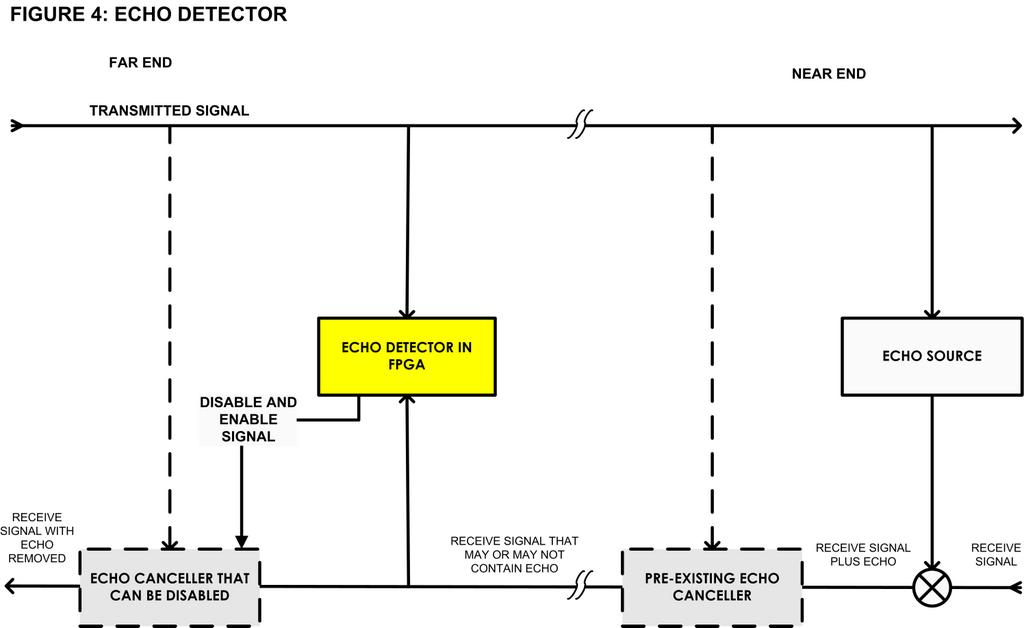
Figure 4. Echo cancellation isn't necessary for incoming calls that already are echo-cancelled. An echo detector can be used to switch off echo cancellation for these calls.
In software echo cancellers, the considerable CPU load that can be freed by echo detection is always immediately available to other processes, which in turn can increase the quality and capacity of the system significantly. More important, echo detection changes the optimization point of the echo canceller design. If only a fraction of calls will require any echo cancellation, the canceller itself can afford to be designed to include the additional features, such as nonlinear processing and fast convergence, that will make the audio truly toll-quality.
Echo on a telephone call is an annoying phenomenon that has been mostly under control in the classic telephony system, but it is rearing its head again as VoIP proliferates. Its effective control is vitally important for the eventual success of VoIP technologies in general, because of the effect of echo on perceived quality. For open-source VoIP PBX/IVR technologies to become truly mainstream, toll-quality audio must be a given, and this requires reliable, high-performance echo cancellation.
David Mandelstam is the President and CEO of Sangoma Technologies. Before founding Sangoma, David ran a private engineering company, was engineering VP of Solartech, an energy conservation company and was responsible for pricing at Spar Aerospace. Prior to immigrating to Canada, David was in charge of aircraft engine maintenance for South African Airways. David holds a BSc in mechanical engineering from the University of Witwatersrand in South Africa, an MSc in aerodynamics from the Cranfield Institute of Technology in the United Kingdom and a BComm from the University of South Africa.

