
Programming Tools: UML Tools
A communication gap exists in most organizations of any size. This even applies to small groups--think job turnover. One of the most common ways of passing on knowledge is through diagrams. In our field, these diagrams often take the form of UML drawings.
None of the UML shapes are complex to create, but automating their creation and rearrangement saves time and also adds consistency. Most of us want something that draws what we want quickly and easily. All of the UML tools I review here can do this to slightly different degrees. However, only one tool is open source. The differences are instructive.
Reviewed here are the DIA drawing program, which is open source, Poseidon by Gentleware and No Magic's MagicDraw. The latter two products have binary-only Community Editions that are available for free for non-commercial purposes. All of them run under Linux and Windows.
The simple tests that I applied below are taken from Scott Ambler's excellent little book The Elements of UML Style.
DIA is a drawing package based on the GNOME Toolkit, gtk+, that tries to emulate the functionality of Microsoft's VISIO program. For simple-minded applications, such as putting predefined visual objects on a sheet, it works fine. However, shapes and pallets have little semantic knowledge about the shapes they contain.
The first figure example in Ambler's book demonstrates how crossing lines have a little bump in one set of lines to indicate that the lines are crossing and not merging. None of the packages showed this distinction this simply. For DIA, I ended up composing this type of line out of an arc and two line segments. It was doable, though, and I then was able to put this crossover connector shape into the UML palette.
Creating most of the other diagram examples in DIA was laborious. In a number of cases, I needed to compose the standard shapes I wanted from more basic shapes. For example, I needed to draw an Associated Class using a regular class object and an association line.
DIA's do-it-yourself figure creation ability can be both a strength and a weakness. For instance, the other two packages were so highly structured that I did not have this flexibility to create what I needed. Figure 1 shows an overview of the DIA GUI.

Figure 1. The DIA GUI
Nits with this version of DIA include:
The main File menu has New and Open options but no Save, SaveAs or Close options.
Once a group of objects is created, it cannot be resized. Also, the properties of an object do not include its size, making resizing an object this way impossible.
In the context menu for a selected object, the first option, Modify, does not seem to do anything.
Documentation that comes with the package does not explain how to create pallets or template objects. However, this information is available on the Web.
DIA crashed a number of times, once while I was saving a diagram.
Poseidon has a nice GUI, which makes using the product a pleasant experience. The company also uses a business model for Poseidon that I like: a non-commercial, single-user Community Edition and Commercial Editions for business purposes. Unlike DIA, however, Poseidon is not open source.
Poseidon is a sophisticated UML drawing program. As shown in Figure 2, it is geared to UML creation. I was not able to create, for example, the crossover connector that I did in DIA. Nor could I figure out how to add new symbols to the pallete. However, I was able to create more sophisticated diagrams more quickly using Poseidon. See Figure 2 for an idea of what this product can do.
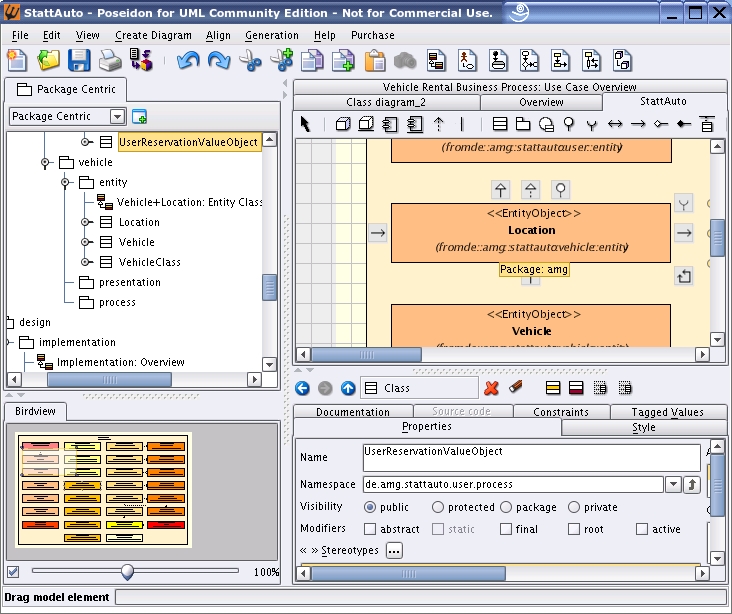
Figure 2. Poseidon at Work
Nits with this version of Poseidon include:
The Community Edition does not support copying a model element completely with all user-provided data, only their visual representation. This is according to the included documentation. However, I could not get Paste to work in any form.
I could not convert a diagonal association into a series of horizontal and vertical line segments.
There is no way of applying attributes such as bold, italics and the like to text elements. However, color and size can be used.
Adding a visible legend to each diagram is a tedious process.
When trying to create a design diagram, there is no way to suppress visibility or an operation's parameter lists.
There is no way of specifying a return type determined by implementation.
In a class diagram, there seemed to be no way of specifying a multiplicity of 0..*
MagicDraw has the most restrictions of any of the Community Editions reviewed here. Its restrictions are based on the amount of work you are trying to do. In other words, don't try to do anything complex with this edition if you don't plan on buying a license. That said, MagicDraw Community Edition is a sophisticated and easy-to-use tool for producing UML diagrams.
After a short time, I found that it was easier to work with MagicDraw than with either of the other two programs. I ended up doing more in even a shorter time than I expected. The interface for this package is shown in Figure 3.
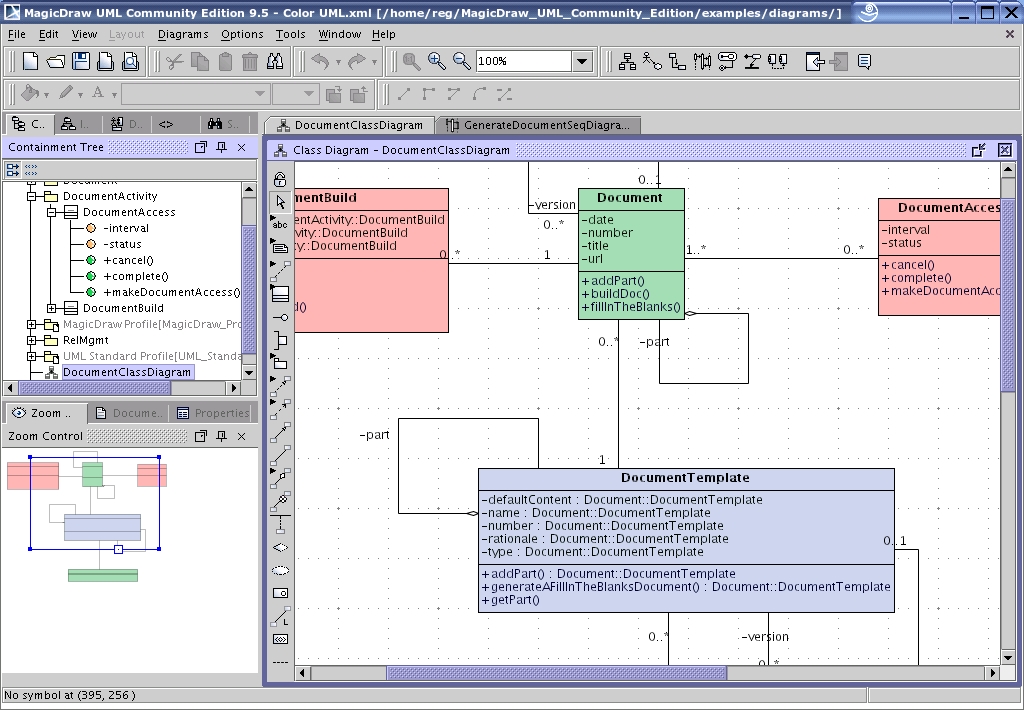
Figure 3. MagicDraw's Interface
Nits with this version of MagicDraw include:
Depending on the drawing mode, you cannot use elements from other modes. For example, I could not use directed associations in the diagrams, although they were available in the Activities diagrams.
The Language Properties button does not work, so I was unable to specify the exceptions that an operation could throw.
In developing the tests for this column, I actually exceeded the limits on the community edition of this program. However, I did not seem to lose anything.
At the moment, none of the open-source tools that I have tried match the richness of the commercial products. DIA is the most extensible, but it does not treat UML semantically, so logical connections and implications are not supported. MagicDraw was the easiest to use, but it also was the most restrictive in terms of both flexibility and licensing.
During my simple testing, it was obvious that the commercial products are more polished and more focused. They are developed intrinsically for the UML market. As such, they are able to make better assumptions about what a user wants to do. That said, they offer little flexibility outside their area of expertise. Eventually, open-source tools will be the equal of their commercial peers, but in the area of UML tools, that moment has not yet come to pass.
Lastly, making each product conform to an arbitrary standard may seem unfair. However, most of us want some form of standard and Ambler's book is a good start. You can adopt his guidelines to fit what your chosen product can do. As long as you have consistency and clarity, you are ahead. However, making each product conform to an unbiased standard has been interesting. Try it yourself, as all of these products are available for the cost of a free download.
The Elements of UML Style, by Scott W. Ambler, ISBN: 0-521-52547-0.
