
Writing Scalable Applications with PHP
The first part of this article, "Real-World PHP Security", appeared in the April 2004 issue of Linux Journal and covered the subject of secure PHP development. This article takes you, the professional PHP developer, one step further, by providing detailed explanations and reliable source code that illustrate the steps to follow in order to develop successful PHP applications.
One day or another, every developer faces a situation in which he/she is responsible for extending the functionality of an existing application or prepare an application for an increase in use and traffic (scaling up). Our goal today is to make this process trivial by learning to develop applications based on a clean, elegant and modular design that is secure, reliable and flexible while keeping it all simple.
Please refer to Figure 1, previously introduced in "Real World PHP Security" and included below.
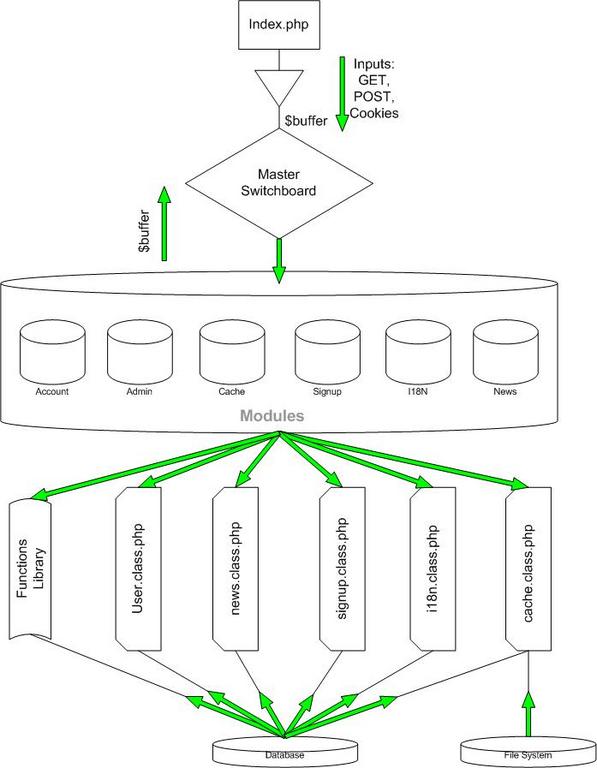
Figure 1. Our Application Model Diagram
As a system administrator, you may have noticed how flexible PHP is in terms of error reporting and security. The php.ini file enables you to make considerable changes to the behavior of the PHP interpreter, which can lead to bad surprises for a PHP developer.
Before we start working on the logic of our application, we must ensure that our operating environment will behave in a predictable way. One of the things you must watch out for is PHP's magic_quotes_gpc directive, which, when enabled, escapes every single value in your GET, POST and COOKIE arrays. This may look like a great way to protect against SQL injections, but it becomes a hassle when working with binary data. Listing 1 illustrates how to detect if the magic_quotes_gpc directive was enabled and how to reverse its effect if necessary.
Listing 1. Cleaning Up the Operating Environment
Many other surprises out there waiting for you as you port your applications to different platforms. Generally speaking, you should become as familiar as possible with the directives available in php.ini. Also, use the ini_get() PHP function to find out if specific directives are enabled or not. You then are able to set up your environment in a predictable way without having to worry about the configuration of the PHP interpreter.
If you are developing a commercial application or would like your application to be as flexible as possible, one thing you should look into is using a database abstraction facility in your projects. Many database abstraction libraries are available, but PEAR::DB is a widely accepted standard that performs well, has great error handling and is quite reliable. DB currently supports 13 different database platforms. DB's documentation is quite extensive and can be found here.
Some may argue that using a database abstraction layer in your application can affect the overall performance. It does, though, bring the flexibility you need to scale your applications up to new levels and to release cross-database applications.
Although DB may not seem forgiving or friendly at first, the DB APIs are compliant with the PEAR standards, which makes its behavior predictable and allows developer to create wrappers easily.
As with any database API, the steps to perform operations on your database are as follow:
Establish a Connection to the Database Server: DB uses a DSN (data source name) to represent the parameters to use when establishing the connection. Many formats are supported; an example might look like this: mysql://dbuser:dbpass@localhost/db_name. You then can use DB::connect(&$dsn) to establish the connection.
Perform Error Handling: DB uses the PEAR standard for its error handling facility. This error handling system is well designed and is versatile enough to provide predictable error control for all PEAR packages.
Specify the Behavior of the Interface: This is where PEAR::DB truly shines. DB allows the developer to define how the package should operate in every aspect. Using the same interface, you can make DB work as a cursor-based result-set iterator or fetch your entire result-set in an ordered array, an array of objects or an associative array.
Execute Queries: Whether you want to execute a stored procedure or a simple query, DB provides simple methods that perform those operations on your database while still providing error handling. The query() method simply executes a query against your database and returns a PEAR error object if an error should occur.
Work with Result-Sets: DB offers many simple methods for working with result-sets and offers a myriad of data-structures to the developer, such as associative arrays, objects, indexed arrays and so on.
But DB also offers some higher-end methods to the developer, such as auto-prepare and auto-execute facilities that allow you to create templates for your SQL query and have DB handle the creation and execution of subsequent queries. It also can filter literals against special characters, regardless of the database server you are using.
In this section, we work on a simplistic PHP application that handles the creation and management of user accounts. Although the rest of this section is pure PHP code, it has been documented and tested extensively. This code illustrates every principle described in this article as well as the initial print article.
We use the following file hierarchy for our application, roughly based on the previous article:
/index.php (this is the only www file) /config.inc.php (configuration file) /lib (libraries, protected by a .htaccess) /modules (module files, protected by a .htaccess) /lib/config.inc.php (configuration file) /tpl (templates, protected by a .htaccess) /doc (project and APIs documentation) /images /classes (classes, protected by a .htaccess) /misc (CSS style-sheets, JS files, etc...)
All of the PHP code for this work is contained in this tar ball along with a README file.
In this article, we have spent a great deal of time looking at a real-world project. A lot of documentation is available in the comments for the listings, so a quick look through the code should give you a clear idea of how it works.
The latest version of this sample application is available for you to download here. Instructions on how to install this sample application as well as the license for this code and the API documentation also are available at the same address.
