
Paranoid Penguin - Application Proxying with Zorp, Part I
At first glance, stateful packet filtering appears to have conquered the firewall world, both in terms of market share and mind share. The list of products based on stateful packet filtering is a long one, and it includes both the proprietary industry leader, Check Point Firewall-1, and Linux's excellent Netfilter kernel code.
But what about application-layer proxies? Professional firewall engineers have long insisted there's nothing like an application-aware proxy for blocking the widest possible range of network attacks. Indeed, being such a person myself, I've been disheartened to see application-layer proxies increasingly marginalized. In some circles they've even been written off as obsolete for reasons that simply don't warrant, in my opinion, the loss of a powerful security tool. Marketing is at least as big a reason as any other.
Apparently I'm not alone in my opinion. Balazs Scheidler, creator of the essential logging facility Syslog-NG, has created Zorp, an open-source proxy firewall product that is simply brilliant. This month I explain why Zorp has helped resuscitate my faith in the application-layer proxy firewall, and what this means for anyone charged with protecting highly sensitive networks.
At this point, some of you may be asking, “What are application-layer proxying and stateful inspection? And why do I care which is better?” I can explain. Feel free to skip ahead to the next section if you're a grizzled firewall veteran.
A firewall, of course, is a computer or embedded hardware device that separates different networks from one another and regulates what traffic may pass between them. The instructions that determine which network nodes may send what type of network packets and where are called firewall rules or, collectively, the firewall policy.
These rules are what make a firewall different from an ordinary router. Routers must be programmed to know how to move packets from one network to another, but not necessarily whether to allow them to move in any given way. A firewall, on the other hand, discriminates.
One very simple way to categorize packets is by the Internet information in packets' Internet Protocol (IP) headers. An IP header contains basic information, most importantly, protocol type, source and destination addresses, and, if applicable, source and destination ports. The ports actually are part of the next header down in the packet, the UDP header or TCP header. A firewall that looks only at this basic information is called a simple packet filter. Because simple packet filters don't look deeply into each packet, they tend to be quite fast.
However, the IP header of a packet plus its TCP or UDP port number tells us nothing about that packet's relationship to other packets. For example, if we examine the IP header of an HTTP packet, we know it's a TCP packet (thanks to the IP field), where it's from and where it's going (source and destination IP address fields) and what type of application sent it (from the destination port, TCP 80). Table 1 shows an example simple packet-filtering rule.
Table 1. Simple Packet Filter Rules for HTTP
| Source IP | Destination IP | Protocol | Source Port | Destination Port | Action |
|---|---|---|---|---|---|
| Any | 192.168.1.1 | TCP | Any | 80 | Allow |
| 192.168.1.1 | Any | TCP | 80 | Any | Allow |
But that level of inspection leaves out some key pieces of information about the HTTP connection: whether the packet is establishing a new HTTP session, whether it's part of a session in progress or whether it's simply a random, possibly hostile, packet not correlating to anything at all. This information is left out because crucial session-related information such as TCP flags, TCP sequence numbers and application-level commands, all are contained deeper within the packet than a packet filter digs. That's where stateful packet filtering comes in.
A stateful packet filter, like a simple packet filter, begins by examining each packet's source and destination IP addresses, and source and destination ports. But it also digs deeper into the packet's UDP or TCP header to determine whether the packet is initiating a new connection. If it is, the firewall creates an entry for the new connection in a state table. If it isn't, the stateful packet filter checks the packet against the state table to see if it belongs to an existing connection. A stateful packet filter will block packets that pretend to be part of an existing connection, but aren't. Actually, UDP is connectionless, but a good stateful firewall can guess that an outbound DNS query to a given server on UDP 53 should be followed by an inbound response from that server's UDP port 53. Stateful packet filtering has two main benefits over simple packet filtering.
First, firewall rules can be simpler. Rather than needing to describe both directions of each bi-directional transaction, such as HTTP, firewall rules need address only the initiation of each allowed transaction. Subsequent packets belonging to established, allowed connections can be handled by the firewall's state table, independently of explicit rules. In Table 2 we see that only one rule is needed to allow the same HTTP transaction for which we needed two rules in Table 1.
Table 2. Stateful Packet Filter Rule for HTTP
| Source IP | Destination IP | Protocol | Source Port | Destination Port | State | Action |
|---|---|---|---|---|---|---|
| Any | 192.168.1.1 | TCP | Any | 80 | New | Allow |
The second main benefit of stateful packet filtering is we don't have to do such distasteful things as allowing all inbound TCP and UDP packets from the Internet to enter our internal network if they have a destination port higher than 1024. This is the sort of thing you sometimes must do if you don't have a better way to correlate packets with allowed transactions. In other words, stateful packet filtering provides better security than simple packet filtering.
“Cool”, you say, “stateful packet filters are more efficient and secure”, which is true. But what about the things even stateful packet filters don't consider? What about things like potentially malformed HTTP commands or intentionally overlapping IP fragments? Might there be a type of firewall that examines each packet in its entirety or that has some other means of propagating the fewest anomalous packets possible?
Indeed there is, and it's called an application-layer proxy or application-layer gateway. Whereas packet filters, whether simple or stateful, examine all packets and pass those that are allowed, an application-layer proxy breaks each attempted connection into two, inserting itself in the middle of each transaction as an equal participant. To the client or initiator in each transaction, the firewall acts as the server. To the intended destination, or server, the firewall acts as the client.
Figures 1 and 2 illustrate this difference. In Figure 1, we see that the stateful packet filter passes or blocks transactions but ultimately is an observer in that it passes allowed packets more or less intact, unless, for example, it performs network address translation (NAT). In contrast, in Figure 2 we see that the firewall terminates each allowed connection to itself and initiates a new, proxied connection to each allowed connection's desired actual endpoint.
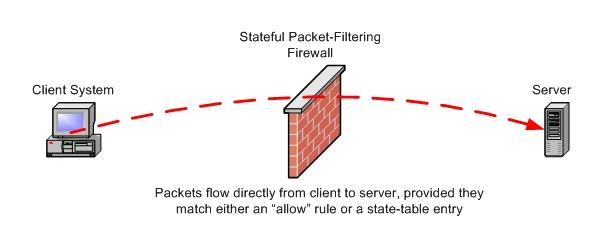
Figure 1. With a stateful packet filter, packets flow directly from client to server, provided they match either an allow rule or a state-table entry.
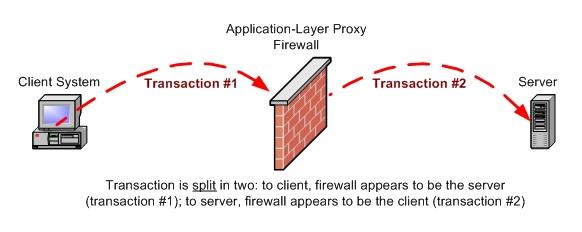
Figure 2. With an application-layer proxy, the connection is split in two. To the client, the firewall appears to be the server (transaction #1). To the server, the firewall appears to be the client (transaction #2).
Proxying comes in two flavors, transparent and nontransparent. In a transparently proxied connection, both parties are unaware that the connection is being proxied; the client system addresses its packets as though there were no firewall, with their true destination IP address. By contrast, in a nontransparently proxied connection the client must address its packets to the firewall rather than to their true destinations. Because the client must, in that case, somehow tell the firewall where to proxy the connection, nontransparent proxying requires clients to run proxy-aware applications. Although most Web browsers and FTP clients can be configured to use a nontransparent proxy, transparent proxies are easier for end users to live with than are nontransparent proxies. Modern application-layer proxies, such as Zorp, are transparent.
Transparent or not, proxying has several important ramifications. First, low-level anomalies, such as strange flags in the IP header, generally are not propagated by the firewall. The firewall initiates the secondary connection in the way that it, not the client system, considers an acceptable manner. Second, because the firewall is re-creating the client connection in its entirety and not merely propagating or trivially rewriting individual packets, the firewall is well positioned to examine the connection at the application layer. This is not a given, however; if the firewall is, say, a SOCKS firewall and not a true application-layer proxy, it simply could copy the data payloads of the client connection packets into those of the new, proxied packets. But if the firewall is application-aware, like Zorp is, the firewall not only examines but makes decisions about the data payloads of all client packets.
Let's look at an example: suppose your public Web server is vulnerable to a buffer-overflow exploit that involves a malformed HTTP GET command containing, say, an abnormally long URL. Your application-layer proxy firewall initially accepts the connection from the client, but upon examining the long URL, closes the connection with an error message to the client and a reset to the server, without ever forwarding the attack payload, the long URL.
The third ramification isn't a positive one: by definition, proxying is more resource-intensive than is packet filtering, and application-aware proxying is especially so. This strike against application-layer proxies is, however, generally overstated. Zorp, for example, can proxy 88Mbps worth of HTTP traffic, nearly twice the capacity of a T-3 WAN connection, running on only a 700MHz Celeron system with 128MB of RAM. Zorp, on a dual-processor Pentium system with 512MB of RAM and SCSI RAID hard drives, can handle around 480Mbps, according to the Zorp Professional v2 Product Description, available at www.balabit.com.
In summary, application-layer proxies provide superior protection by inserting themselves in the middle of each network transaction they allow by re-creating all packets from scratch and by making intelligent decisions on what application-layer commands and data to propagate. They accomplish this based on their knowledge about how those applications are supposed to work, not merely on how their container packets ought to look. The main strike against application-layer proxies is performance, but thanks primarily to Moore's Law, this shortcoming is mitigated amply by fast but not necessarily expensive hardware.
In the interest of full disclosure, I should mention one other shortcoming that many people perceive in application-layer proxies, greater complexity. It stands to reason that because application-layer proxies are more sophisticated than packet filters, it should take more sophistication to configure them, in the same way that you need to know more to operate a Mosler safe than to operate your typical bus station locker. It's more work to configure a firewall running Zorp or Secure Computing Sidewinder than it is to configure one running Check Point Firewall-1 or Linux Netfilter/iptables.
But isn't better security worth a little extra work? Like everything else in information security, it's up to you to choose your own trade-off. Maybe the extra work is worth it to you, and maybe it isn't. Either way, I hope this column makes you glad you've got the choice in the first place. The remainder of this article, which continues with at least one more installment, explains precisely what's involved in configuring and using Zorp.
The proxy dæmons that comprise Zorp run on top of the Linux kernel concurrently with the standard Netfilter and Balabit-provided TPROXY kernel modules. In theory, this makes Zorp distribution-agnostic, and it's designed to compile cleanly on any Linux distribution that meets certain requirements (see below). Zorp is developed on Debian Linux, however, and the vast majority of Zorp documentation assumes that you're running Debian too. In fact, Zorp GPL is an official Debian package (as of this writing, in Debian's testing and unstable releases).
Zorp is available in three versions: Zorp GPL, the free GPLed version; Zorp Unofficial, a cutting-edge or beta version of Zorp GPL; and Zorp Professional (or simply Zorp Pro), a commercial product based on but with more features than Zorp GPL. If you purchase Zorp Pro, you get a bootable CD-ROM that installs not only Zorp Pro but ZorpOS, a stripped-down Debian distribution optimized for Zorp. With Zorp Pro, a bare-metal Zorp installation takes less than 15 minutes, excluding subsequent configuration, of course. Anyone who's suffered through lengthy dselect sessions while trying to install just enough Debian for one's needs can appreciate the beauty of this.
Zorp Pro also includes the new Zorp Management Server (ZMS), which allows you to manage multiple Zorp firewalls from a central management host. The host in turn can be operated remotely with ZMC, a GUI client available in both Debian Linux and Windows versions. ZMS is functionally equivalent to Check Point Firewall-1's management module, arguably the biggest reason Check Point has conquered the enterprise firewall world. ZMS has the potential to make Zorp very attractive indeed to sites with a lot of firewalls to manage.
ZMS/ZMC is still a little rough around the edges—Balabit isn't expecting to release a consumer-installable version of that part of Zorp Pro in March 2004 (though at the time of this writing it is being used, successfully, by paying customers). Even if you don't use ZMS/ZMC, Zorp Pro's smooth installation and wide range of features, including several application proxies not supported in Zorp GPL, make Zorp Professional worthwhile.
Unlike Zorp Pro, Zorp GPL and Zorp Unofficial require a working Linux installation that includes the following: glib 2.0, Python 2.1, libcap 1.10 and openssl 0.9.6g. It also requires either a Linux 2.2 kernel compiled with IP, firewalling and transparent proxy support or a Linux 2.4 kernel compiled with iptables, iptables connection tracking, iptables NAT and, using Balabit's TPROXY kernel patch (www.balabit.com/products/oss/tproxy), iptables transparent proxying. All of these features should be compiled as modules.
Once your OS is ready, you either can install Zorp GPL from binary deb packages or compile Zorp GPL from source code (available at www.balabit.com/downloads). Compiling Zorp GPL is a little more involved than your typical ./configure make make install routine; see the Zorp GPL Tutorial at www.balabit.com/products/zorp_gpl/tutorial for detailed instructions.
Next time, I'll describe how to set up Zorp GPL to protect a typical Internet—DMZ—Trusted Network topology.
Mick Bauer, CISSP, is Linux Journal's security editor and an IS security consultant in Minneapolis, Minnesota. He's the author of Building Secure Servers With Linux (O'Reilly & Associates, 2002).
