
Linus & the Lunatics, Part I
This article series includes transcriptions of two talks given on the latest Linux Lunacy Geek Cruise, which occured this past September. For background details, check out the three-part report on the whole cruise; a link to the next part is located at the end of the first two installments.
The first talk, given at sea somewhere between Sitka and Ketchican off the coast of Alaska, was Linus' second annual progress report on the kernel. Part I (below) of this article series is the prepared part of Linus' talk. It includes the slides and screen projections he used to illustrate his points. Part II is the transciption of the much longer Q&A that followed. Part III is an excerpt from a meeting between about 30 Linux Lunatics and 50 members of the Victoria Linux Users Group. Linus plays a leading role in that one, as does kernel developer Ted Ts'o.
These transcriptions have been edited lightly and only for clarity. So listen with your ears and keep an open mind. If you do, I bet you'll learn even more than you already know about why Linux and the world that increasingly depends on it continue to adapt so well to each other.
--Doc Searls

Linus: As most of you probably already know, I hate giving talks... I expect this to be mostly a Q&A. But usually Q&As that start off cold don't work very well. So what I usually do for my Q&A is do a few slides. If the slides end up being interesting and I get questions on the slides, the slides can take up the whole thing. But that seldom happens because the slides tend to be boring.
But I've noticed that I used to give a lot of talks about what's new in 2.6 kind of things, right? Or a few technical thoughts about some specific feature. And I decided I won't do that this time at all. Because I notice that what I'm not actually doing any more is coding... Since I'm still giving a talk about technical stuff, I decided that I might as well give a talk about managing stuff.... a few slides on some of the issues that come up.
I've really only got a few points on what really matters. Obviously, people--managing people, and having other people manage people for you--ends up being one of the more important parts. The other one is that we have started to use a lot of tools for management. One of them obviously is source control. The other one is, I'm writing this C parser because I decided I needed it and wanted it.

So people it actually seems to be biggest problem.
[Laughter.]
What I've gotten the most negative comments about for the last couple of years has been, for example, that the Linux-kernel mailing list is not a very friendly place. And people are actually afraid of posting on the mailing list because of the flammage they get.
It is very hard to find people who don't flame and are calm and rational--and have good taste. I mean it's like...give me one honest man. It doesn't happen...too much. And at the same time, when it happens, it matters a lot. Just a few of these people make a huge difference.
Allen Cox used to be the main one to some degree. He's going off to do an MBA, don't ask me why.
[Laughter.]
He was obviously getting tired of it too. And that's one of the problems. Is that this is a very high-visibility thing. The good ones tend to rise pretty quickly. Once you reach a certain point you get a lot of respect; but it's hard to reach that point. It takes insane amounts of time. It's a full-time job because if you go away for a week regularly, you end up not being able to manage a lot of what happens. And one of the problems tends to be that, well, companies that have been involved in kernel development have been pretty good about putting engineers on specific areas that they [the engineers] care about. It seems to be very hard to get companies to actually put managers--these kind of technical management people into...
Part of it is just liability, apparently. That certain companies--I know IBM for example--have a rule that their engineers must not commit other people's code. It's okay to commit their own code, but if you take in somebody else's code and commit that--at least in some groups, I don't know if that's true in all groups--which means that it's impossible to be this kind of technical manager for the kernel. If you have that policy. Because you need to take other people's code and basically make releases.
A lot of people basically ignore it. Greg works for IBM. He doesn't seem to care too much about the IBM rules and he does a really good job. Andrew Morton right now is my right-hand man. And he's not actually been around that long. He's been active in Linux for something like three years, and he was [garbled] my choice for 2.4 maintainer too, except then he was so new to the whole thing. So pretty quickly the exceptional people do stand out. But on the other hand there are a lot of problems really getting many new faces. The companies decide, "Hey, we want a new manager too". Because they have their own problems finding good technical managers.
So this is one of the biggest issues I ever--I always--have. Is finding people who basically act as managers for the kernel.
This is not Linux-specific itself. But I just wanted to say that this is maybe the biggest issue.

So the thing that makes this very important is just the scale of the problem. I got out some statistics from [garbled] what has happened during this year. Not the last twelve months, but calendar year 2003, so just the last nine months or so.
We've had twelve thousand changes by more than 500 people. And that [on screen] looks like a very exact number, but what I did was get all the e-mail addresses, ripped out the hostnames completely and just did a unique count on the first part. There is a number of Davids that were counted as one. But on the other hand, it's very rare, but some people do show up twice just because they have two to ten e-mail addresses that they actually use different names, not just different hosts.
And while it's true that it's a very skewed number here, that twenty percent did ninety percent of the changes, part of the reason for that is that, in the top twenty percent are a lot of the managers who actually end up incorporating changes from others. And the prime example of this is, Number One is not me... I did show up as Number Two, which made me happy. But Number One is Andrew Morton. He writes code himself, but at least half of what he does is, he gathers stuff from other people too, which is the only sane way to get the job done.
So yes, it is very skewed in the sense that, of the twelve thousand I think fifteen hundred were by Andrew, but at the same time this actually hides the fact that there's even more than 500 people involved.
I like this. It's important to have 500 people involved. Because if you end up having a core group, which a lot of projects have, where you have thirty people involved and nobody else ever does anything, that project will die. I mean, it's not a question of if; it's a question of when, right?
So you want to have people who actually get involved and start doing a lot of these changes are obviously very small. So that's how you get into the thing.
This is good, and it's important. But the subtitle here [at the title, "More about people"] is "What's wrong with CVS." This is also the reason why I will never ever touch CVS. I worked for six years, and this number is interesting: during nine months, we've had twenty-nine hundred merges. And by merges I mean there was actually parallel work on two trees that were joined. It was not just copying a tree around and doing a trivial merge where no code has changed. It was actually a case of 2,300 times, different people had done updates in parallel, and they had to be merged. And I think about fifty of those were manual. Everything else was automatic.
And the nice thing about that is [to the audience]--Who has actually used CVS? Who has used CVS with branches? Who has ever done a single merge and not felt bad about it?
[Laughter.]
Imagine doing 2,300 merges.

And part of the reason there are so many merges here is [partly that] there are a lot of developers who do things in parallel; but part of it is because BK (BitKeeper) makes it so easy. We do merges all the time. It really helps, because you don't have this flag day, when you have had a long living branch, that has gone through maybe half a year's worth of development, while the main line has gone through half a year worth of development, and they have completely different reasons for being there--and when you merge them you have bugs that could have been introduced anywhere within the last six months. So making joining easy is, to me, very important for a lot of different people.
A lot of people don't like BitKeeper. I'm not going to push BitKeeper per se. The important part is the merging. And realizing the fact that a lot of work gets done that never gets merged back. I do that all the time myself. I do something, I start a second separate tree for testing something out, and decide "That sucks". And I never merge it back. So you actually don't even see the fact that there have been more branches than have been merges. And if you have five hundred plus people, you obviously can't trust them....
I am firmly convinced that if your source control doesn't support random people making their own branches, and then being able to merge as they do development with anybody else's branch, the source control is not worth bothering with. And if BitKeeper ever goes away, I will not go to Subversion or something like that. I will go back to tarballs and patches. Because at least that one doesn't have merge problems that most other projects have. Which is kind of strange, but.... It has been very productive. It has helped enormously having something that is truly distributed. But I did want to mention that.
The last Geek Cruise I mentioned BitKeeper. It was still a bit controversial at that time, because I had only used it for like four months or something. And people hadn't gotten used to it so much. This time around it is clear that even the people who don't like the license per se seem to have realized how useful the source control management thing is, when done right. And CVS is not it.
So, the other tool I've been working on...basically grew out of my own personal belief that ANSI C is basically the language for gods. The language for somebody who wants to control everything, right? You can keep your scripting languages, your toy stuff--
[Laughter.]
--but you can't control the world. You can't create the something that controls everything with that. C does.

ANSI C is good. But K&R I hate. I refuse to touch K&R code. I look at projects that still use K&R.... [Some] say that, "Hey, we have to support legacy systems." And I say "Screw them." There are no legacy systems that make it worthwhile anymore. Get a real compiler.
The only real difference between ANSI C and K&R is type checking. I am a huge believer in static typechecking that doesn't add any runtime overhead. So you basically get perfect performance, assuming your compilers are perfect--whatever--with reasonably good safety. The problem is that being the kernel has to do a lot of things that break typechecking. Which you see more in the kernel than in a lot of other programs. You end up having a lot of inline assembly which is obviously completely opaque.
[From audience] ...C typechecking?
Yes. That's correct. And that is kind of the reason for Sparse. You can extend the typechecking so that you can describe the kinds of things the kernel wants to do. So that you actually can get the same kind of static typechecking for areas you are interested in.
A lot of this is actually kind of inspired by the Stanford checker. How many of you have heard of the Stanford checker? A few. The Stanford people basically took GCC, tweaked it a bit so it output dependency chains and a lot of other information, wrote a lot of scripts to go through what the internal GCC organization had been. And they actually figure out, to some degree, the rules, the typechecking, on their own, from that parse stream.
The problem is, you can't get at the sources, it is extremely complicated--this is definitely a research project--and part of it is, because they tried to take non-modified kernel sources, and figure out, from the non-modified kernel sources, what the rules are. Which is really manly. But it's manly in a very stupid way.
[Laughter.]
Because what you could really do is just add the annotations to the kernel sources directly, so that you don't have to figure out what the rules are. You make them explicit, which is nice because you make it exclusive to the programmer himself, which ends up being as useful as the fact that you now can check for it automatically. So I decided that [using] the Stanford tools, which weren't even released--they did their stuff every few months--wasn't really the approach.
So I wrote Sparse. Which is best explained by an example.

Basically you can add attributes to any kind of data type. In Sparse one of the attributes on data types is which address space it belongs to. This is a define that goes away if you don't use Sparse.
So GCC, who doesn't know anything about address spaces, will never see any other code. So GCC treats the exact same code as it always used to do; but when you run it with a Sparse checker, it will notice that when you do a copy_to_user call, the first argument has to be a user pointer. Well, address_space (1), the tool itself doesn't really care about user or kernel; you can use it for anything. If it gets anything that isn't a user pointer, for example, if you switch the arguments around by mistake, which has happened, it will complain with a big fat warning saying "Hey, the address spaces don't match." And the nice thing about this is--well, in copy_to_user it's not so interesting because the function obviously copies to user space. But I will actually show...[types on keyboard]...so something like this...

...basically takes the argument to exec.c and counts how many arguments there are or how many environment variables there are. So it takes a pointer to user space that points to user space--so that both of them are actually pointers to, and different address space on the kernel one, so you know indeed what it really means. In that sense. You know you can't directly via reference (?) it. So you actually have documentation for the kernel at the same time. Because Sparse will actually follow the types as you access them.
It notices that when you do a get_user on something that is __user * __user *, it will not complain because it got a __user *, but it will return a __user *.
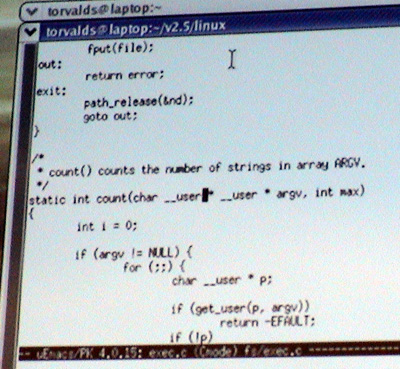
So now, if I had used the wrong type here for p, Sparse again would have complained and said, "Hey, you didn't actually get a kernel pointer. You got a user pointer. So you better use the right pointer."

[Question from the audience, inaudible.]
Sparse [garbled] asset compiler. I actually made it a full front end. Once you do the parsing and the pipe checking, you really have all that information anyway. Jeff Garzik, because I kind of pushed him into it, wrote a back end for the 386.
[Question from the audience, inaudible.]
Well, the code generator is really new. It's like a week old right now. The test examples tend to look like, "surprise, surprise". Right? The interesting part is, this is a really hard program to parse. Can anybody guess why?

[Audience, inaudible.]
The [garbled] itself is easy. It's just a function call. This one pulls in something like thirty different header files, with new extensions in them, right?. So you have to get all the attributes right, to not give warnings about the header files. As it turns out, if you actually try to compile this--
[Audience, inaudible.]
Trust me, you need that header. Because Sparse will refuse to touch anything that doesn't have a prototype. Because it will say "I don't know what the types are, I can't check them." So you need the header. So these are the warnings.

Sparse doesn't understand the mode attribute. So, right now, we'll have to fix that just to be able to compile user space.

The code generated is crap. But it actually happens to work, so what you can do is--
[Audience, inaudible, laughter.]
But I actually wanted the code generator because it validates that the parser is doing the right thing. Which is really hard to do. Outputting a parse stream is a nasty business. They look completely unreadable for anything even remotely interesting, right? Which means the only way to really validate that the front end does the right thing is actually to write a back end. And if the back end generates code that actually can run, you don't care if it's efficient or not. You know the front end works, right?
That was kind of a digression.
I have another example that we're not using in the kernel yet, but I designed it for the kernel, which is to give

again, any object not only has an address space; but you can do context masks to say, "Okay, you can only use this object in a certain context." My point is, this part you'd hide in a header file again. Sparse doesn't know about things like IRQs, and it shouldn't know about things like IRQs. But it can say, "Okay, these bits in the context mask mean that I am interested in this particular context, and those bits had better match these other bits that I care about." Right? Which means you can bend, once you have that header file. You can say, "Okay..." ira_handler? That's a handler that shoots people or something?
[Laughter.]
[I mean] irq_handler. The point was, this is what I eventually want to add to the kernel too, saying "This function can tape". (?) Right now we actually check for that dynamic. Right now we actually check for that dynamic clue. Which adds overhead at runtime and that means you only find the cases that you actually run through, right? But say if you do static typechecking, it's actually stronger than the dynamic typechecking that you do currently. Plus there's no performance overhead. That's why I want to do things like this.
By the way, this is actually a real warning. I typed this in with Sparse. It is literally the warning you will get. It says "context c, line 13, character 2"--which happens to be that i--"using symbol irq--unsafe in wrong context." So it actually gives you readable warning messages for doing that thing.

Right now it's a bit too limited. [Garbled.] So I need to improve Sparse a bit more.
That's really all of my prepared slides.
The Q&A section of Linus' talk appears in Part II.
Doc Searls is Senior Editor of Linux Journal, covering the business beat. His monthly column in the magazine is Linux For Suits, and his bi-weekly newsletter is SuitWatch.
email: doc@ssc.com


