
Scaling dcache with RCU
RCU (read-copy update), a synchronization technique optimized for read-mostly data structures, recently was added to the Linux 2.6 kernel. This article describes how RCU improved the scalability of Linux's directory-entry cache (dcache). For some more background, see “Using RCU in the Linux 2.5 Kernel”, in the October 2003 issue of Linux Journal.
Linux's dcache maintains a partial in-memory image of the filesystem hierarchy. This image enables pathname lookup without expensive disk transfers, greatly increasing the performance of filesystem operations. To ease handling of mount and unmount operations, the Linux kernel also maintains an image of the mount tree in struct vfsmount structures.
If the Linux 2.4 dcache is so great, why change it? The difficulty with the 2.4 dcache is it uses the global dcache_lock. This lock is a source of cache line bouncing on small systems and a scalability bottleneck on large systems, as illustrated in Figure 1.

Figure 1. Tux Doing His Duty
This section provides background for the RCU-related dcache changes, which are described later in the article. Readers desiring more detail should dive into the source code.
This section uses the example filesystem tree shown in Figure 2, which has two mounted filesystems with roots r1 and r2, respectively. The second filesystem is mounted on directory b, as indicated by the dashed arrow. The file g has not been referenced recently and therefore is not present in dcache, as indicated by its dashed blue box.

Figure 2. Example Filesystem Tree
The dcache subsystem maintains several views of the filesystem trees. Figure 3 shows the directory structure representation. Each dentry representing a directory maintains a doubly linked circular list headed by the d_subdirs field that runs through the child dentries' d_child fields. Each child's d_parent pointer references its parent. The mountpoint (dentry b) does not reference the mounted filesystem directly. Instead, the mountpoint's d_mounted flag is set, and dcache looks up the mounted filesystem in mount_hashtable, a process that is described later.
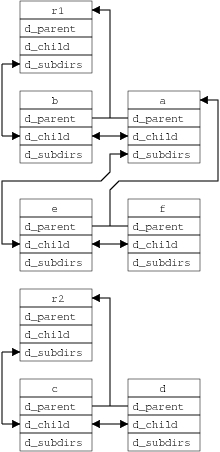
Figure 3. dcache Representation of the Example Filesystem Tree
Although one could search the d_subdirs lists directly, this would be a slow process for large directories. Instead, __d_lookup() hashes the parent directory's dentry pointer and the child's name, searching the global dentry_hashtable for the corresponding dentry. This hash table is shown in Figure 4, along with the LRU list headed by dentry_unused. Any dentry in the LRU list usually is in the hash table as well. Exceptions include cases where parent directories time out, such as in distributed filesystems like NFS.

Figure 4. dentry Hash Table
Each dentry references its inode using the d_inode pointer. This d_inode pointer can be NULL for negative dentries, which lack an inode. Negative dentries can be generated when a filesystem removes a dentry's file or when someone tries to lock a non-existent file. Negative dentries can improve system performance by failing repeated accesses to a given non-existent file without having to invoke the underlying filesystem. Similarly, hard links result in multiple dentries sharing an inode, as shown in Figure 5.

Figure 5. Hard-Link Alias Chains
Figure 6 shows a high-level dentry state diagram. The normal dentry's life goes as follows:
d_alloc() allocates a new dentry for a newly referenced file, leading to state New.
d_add() associates the new dentry with its name and inode, leading to state Hashed.
When done with the file, d_put() adds the dentry to the LRU list and sets its DCACHE_REFERENCED bit in its d_vfs_flags field, leading to state LRU Ref (Hashed).
If the file is referenced again while in the LRU Ref (Hashed) state, dget_locked(), usually called from d_lookup(), marks it in use. If it still is in use at the next prune_dcache() invocation, it is removed from the LRU list, leading again to state Hashed.
Otherwise, prune_dcache() eventually removes the DCACHE_REFERENCED bit from the d_vfs_flags field, leading to state LRU (Hashed).
As before, if the file is referenced again, dget_locked() marks it in use so that prune_dcache() can remove it from the LRU list, leading again to state Hashed.
Otherwise, the second consecutive call to prune_dcache() invokes d_free() via prune_one_dentry(), resulting in state Dead.
Other paths through Figure 6 are possible. For example, if a distributed filesystem converts a cached file handle into a new dentry, it invokes d_alloc_anon() to allocate the dentry when the corresponding object's parent is no longer represented in the dentry cache. Similarly, using d_delete() to delete the file or directory underlying a given dentry would move that dentry to the Negative state. On last close, it would be advanced to “Dead”.

Figure 6. dentry State Diagram
Figure 7 shows the mount_hashtable data structure used to map the mountpoint dentry to the struct vfsmount of the mounted filesystem. This mapping hashes the pointer to the mountpoint dentry and the pointer to the struct vfsmount for the filesystem containing the mountpoint. This combination of dentry pointer and struct vfsmount allows multiple mounts on the same mountpoint to be handled more gracefully.

Figure 7. Traversing Mountpoints
The example filesystem layout shown in Figure 2 would result in struct vfsmount structures as shown in Figure 8. The vfs1 structure references the root dentry r1 both as the mnt_mountpoint and the mnt_root, because this filesystem is the ultimate root of the filesystem tree. The vfs2 structure references dentry b as its mnt_mountpoint and r2 as its mnt_root. Thus, when the mount_hashtable lookup returns a pointer to vfs2, the mnt_root field quickly locates the root of the mounted filesystem.

Figure 8. VFS Mount Tree
The overall shape of the mounted filesystems is reflected in the mnt_mount/mnt_child lists. These lists are used by functions such as copy_tree() while doing loopback mount, which need to traverse all the filesystems mounted in a particular subtree of the overall pathname namespace.
A full parallelization of dcache would be quite complex and was deemed too risky for the latter part of the 2.5 effort. The 2.6 dcache is but one step along the road to RCU; the goal for 2.7 is to walk the entire path without acquiring any locks.
Listing 1. Lock-Free Pathname Segment Lookup
1 struct dentry *
2 __d_lookup(struct dentry * parent,
3 struct qstr * name)
4 {
5 unsigned int len = name->len;
6 unsigned int hash = name->hash;
7 const unsigned char *str = name->name;
8 struct hlist_head *head = d_hash(parent,hash);
9 struct dentry *found = NULL;
10 struct hlist_node *node;
11
12 rcu_read_lock();
13 hlist_for_each (node, head) {
14 struct dentry *dentry;
15 unsigned long move_count;
16 struct qstr * qstr;
17
18 smp_read_barrier_depends();
19 dentry = hlist_entry(node, struct dentry,
20 d_hash);
21 if (unlikely(dentry->d_bucket != head))
22 break;
23 move_count = dentry->d_move_count;
24 smp_rmb();
25 if (dentry->d_name.hash != hash)
26 continue;
27 if (dentry->d_parent != parent)
28 continue;
29 qstr = dentry->d_qstr;
30 smp_read_barrier_depends();
31 if (parent->d_op &&
32 parent->d_op->d_compare) {
33 if (parent->d_op->d_compare(parent, qstr,
34 name))
35 continue;
36 } else {
37 if (qstr->len != len)
38 continue;
39 if (memcmp(qstr->name, str, len))
40 continue;
41 }
42 spin_lock(&dentry->d_lock);
43 /*
44 * If dentry is moved, fail the lookup
45 */
46 if (likely(move_count ==
47 dentry->d_move_count)) {
48 if (!d_unhashed(dentry)) {
49 atomic_inc(&dentry->d_count);
50 found = dentry;
51 }
52 }
53 spin_unlock(&dentry->d_lock);
54 break;
55 }
56 rcu_read_unlock();
57 return found;
58 }
Pathname segment lookup is performed by the __d_lookup() function shown in Listing 1. The __d_lookup() function is invoked with a pointer to the parent directory's dentry and the name to be looked up. The name is passed in a struct qstr, which contains a pointer to the string, its length, a precomputed hash value for the dcache hash table and the name itself, if desired.
Lines 5–7 unmarshall the struct qstr. Line 8 hashes the combination of the name and the parent dentry pointer into the global dcache hash table, yielding a pointer to the corresponding hash chain.
Lines 12 and 56 demark the RCU-protected segment of the code, disabling preemption in CONFIG_PREEMPT kernels, as specified by the Reader-Writer-Lock/RCU analogy described in the article entitled “Using RCU in the Linux 2.5 Kernel” in the October 2003 issue of Linux Journal. Lines 13–55 loop through the elements in the selected hash chain, looking for the matching dentry. Line 18 issues a memory barrier but only on DEC Alpha. On other CPUs, the data dependency implied by the pointer dereference suffices, so on these CPUs, line 18 generates no code.
Because this lookup acquired no locks, it may be racing with a rename system call. Such a system call could move a dentry to another hash chain, taking this lookup with it. Lines 21 and 22 check for this race, but they are not sufficient in and of themselves. Therefore, line 23 takes a snapshot of the number of times that the current dentry has been subjected to a rename, the dcache d_move() function, which is used later to determine if any renames raced with the path walk. Line 24 is a memory barrier to ensure that the snapshot is not reordered by either the compiler or the CPU.
Lines 25–28 check the name hash and the parent dentry. If either fail to match, this dentry cannot be the target of our lookup. Lines 29–41 do the full name comparison, with memory barrier for DEC Alpha at line 30. Filesystem-specific name comparison functions may be provided, for example, for case-independent filesystems, as shown on line 33.
If execution reaches line 42, we have found a child dentry with a matching name. We then acquire the child dentry's lock on line 42. Because we have a lock on each dentry, the level of contention on these individual locks is much lower than on the original dcache_lock. Nonetheless, life is not perfect. For example, the lock on the root dentry still is subject to contention, a topic discussed later.
The child dentry possibly was renamed after the d_move_count snapshot was acquired on line 23. Therefore, lines 46–47 check the current value of d_move_count against the snapshot. If the check passes, the child dentry has not been renamed out from under the lookup, and lines 48–51 increment a reference count—but only if the entry still is hashed.
Line 53 releases the child dentry's lock, and line 54 breaks out of the hash-chain search loop. Line 57 returns a pointer to the child dentry if the lookup was successful, or NULL otherwise.
A failure of __d_lookup() does not mean that failure is returned to the user process. The file actually may exist, but has not been loaded yet into dcache.
This function does not protect, however, against all rename-race hazards. One additional race is caused by the fact that dcache uses hlist rather than list for the dcache hash chains. It uses hlist to save memory, because hlist requires one rather than two pointers in the list header. This does mean, though, that hlist, unlike list, is not circular. It therefore is possible that a particular dentry will be renamed such that it lands in a previously empty dcache hash chain. If this happened at the right time, the __d_lookup() function could return search failure incorrectly.
An incorrectly returned search failure is handled by the upper-level d_lookup() function, shown in Listing 2. Any racing renames are detected by the read_seqretry() function on line 13. As the problematic case results only in spurious failure, the check is made only on NULL return from __d_lookup().
Listing 2. Pathname Segment Lookup Rename-Race Resolution
1 struct dentry *
2 d_lookup(struct dentry * parent,
3 struct qstr * name)
4 {
5 struct dentry * dentry = NULL;
6 unsigned long seq;
7
8 do {
9 seq = read_seqbegin(&rename_lock);
10 dentry = __d_lookup(parent, name);
11 if (dentry)
12 break;
13 } while (read_seqretry(&rename_lock, seq));
14 return dentry;
15 }
The d_free() function must defer freeing of a given dentry until a grace period has elapsed, because any number of ongoing path walks might be holding references to that dentry. Deferment is accomplished in the d_free() function shown in Listing 3, where line 5 uses the call_rcu() primitive to defer the destructive actions in the d_callback() function until after a grace period has elapsed. The d_callback() function is shown in Listing 4; it simply frees large names stored separately (lines 5–7), if appropriate, then frees the dentry itself on line 8.
Listing 3. Deferred-Free of dentry Structures
1 static void d_free(struct dentry *dentry)
2 {
3 if (dentry->d_op && dentry->d_op->d_release)
4 dentry->d_op->d_release(dentry);
5 call_rcu(&dentry->d_rcu, d_callback, dentry);
6 }
Listing 4. RCU Callback Function for dentries
1 static void d_callback(void *arg)
2 {
3 struct dentry * dentry = (struct dentry *)arg;
4
5 if (dname_external(dentry)) {
6 kfree(dentry->d_qstr);
7 }
8 kmem_cache_free(dentry_cache, dentry);
9 }
The d_move() function implements the dentry-specific portion of the rename system call, as shown in Listing 5. Line 5 excludes any other tasks attempting to update dcache, and line 6 permits d_lookup() to determine that it has raced with a rename. Lines 7–13 acquire the per-dentry lock of the file being renamed and its destination, ordered by address so as to avoid deadlock. Lines 14–17 remove the entry from its old location in the dcache hash table, if it has not been so removed already.
Line 19 updates the dentry to point to its new hash bucket, lines 20–21 add the dentry to its destination hash bucket and line 22 updates the flags to indicate that the dentry is present in the dcache hash table. Line 24 removes the target dentry—the one being rename()ed over—from the dcache hash table, and lines 25–26 divorce the moving and target dentries from their old parents.
Line 27 changes the dentry's name, and line 28 enforces write ordering. The name change is nontrivial due to the fact that short names are stored in the dentry itself, and longer names are stored in separately allocated memory. Lines 29–32 update the name length and hash value. Lines 33–44 connect the dentry to its new parent. Finally, line 45 updates the d_move_count so __d_lookup() can detect races, and lines 46–49 release the locks.
In theory, a sustained succession of rename operations carefully designed to leave dentries in the same directory and in the same hash chain could stall indefinitely horribly unlucky lookups. One way this stall could happen is if the lookup is searching for the last element in the hash chain and the second-to-last element is renamed consistently (thus moved to the head of the list) just as the lookup got to it. In practice, dcache hash chains are short and renames are slow. If these stalls become a problem, though, it may be necessary to add code to stall renames upon path-walk failure. Another approach being considered is to eliminate the global hash table entirely in favor of modifying the d_subdirs list so as to handle large directories gracefully.
Listing 5. Renaming dentries
1 void
2 d_move(struct dentry *dentry,
3 struct dentry *target)
4 {
5 spin_lock(&dcache_lock);
6 write_seqlock(&rename_lock);
7 if (target < dentry) {
8 spin_lock(&target->d_lock);
9 spin_lock(&dentry->d_lock);
10 } else {
11 spin_lock(&dentry->d_lock);
12 spin_lock(&target->d_lock);
13 }
14 if (dentry->d_vfs_flags & DCACHE_UNHASHED)
15 goto already_unhashed;
16 if (dentry->d_bucket != target->d_bucket) {
17 hlist_del_rcu(&dentry->d_hash);
18 already_unhashed:
19 dentry->d_bucket = target->d_bucket;
20 hlist_add_head_rcu(&dentry->d_hash,
21 target->d_bucket);
22 dentry->d_vfs_flags &= ~DCACHE_UNHASHED;
23 }
24 __d_drop(target);
25 list_del(&dentry->d_child);
26 list_del(&target->d_child);
27 switch_names(dentry, target);
28 smp_wmb();
29 do_switch(dentry->d_name.len,
30 target->d_name.len);
31 do_switch(dentry->d_name.hash,
32 target->d_name.hash);
33 if (IS_ROOT(dentry)) {
34 dentry->d_parent = target->d_parent;
35 target->d_parent = target;
36 INIT_LIST_HEAD(&target->d_child);
37 } else {
38 do_switch(dentry->d_parent,
39 target->d_parent);
40 list_add(&target->d_child,
41 &target->d_parent->d_subdirs);
42 }
43 list_add(&dentry->d_child,
44 &dentry->d_parent->d_subdirs);
45 dentry->d_move_count++;
46 spin_unlock(&target->d_lock);
47 spin_unlock(&dentry->d_lock);
48 write_sequnlock(&rename_lock);
49 spin_unlock(&dcache_lock);
50 }
Although this change in dcache was relatively small, it had far-reaching consequences in the kernel, because a well-defined API for filesystems to interact with dcache was not in place. This resulted in a large number of bugs in the Linux 2.5 kernel due to filesystems hackers attempting to manipulate dcache directly in the traditional style. Given that a somewhat more formal API now exists, we hope future changes will be less traumatic.
Figure 9 shows the performance of a multiuser benchmark running on a Linux 2.5.59 kernel patched to use RCU in the directory-entry cache compared to the performance of an unpatched kernel. These benchmarks were run on a 16-CPU NUMA-Q system using 700MHz PIII Intel Xeons with 1MB L2 cache and 16GB of memory.

Figure 9. Multiuser Benchmark Performance
Applying the dcache_rcu patch to a Linux 2.4.17 kernel increased SPECweb99 (without SSL) throughput from 2,258 to 2,530 on an 8-CPU PIII Xeon server, a 12% improvement. Applying the same patch to a Linux 2.5.40-mm2 kernel reduced the system time consumed by a Linux kernel build from 47.548 CPU seconds to 42.498 CPU seconds, more than a 10% reduction. A similar test run on a uniprocessor 700MHz PIII Xeon system running the Linux 2.5.42 kernel showed no change. In summary, dcache RCU not only increases scaling for high-end machines, it also maintains good performance on low-end machines.
Although the 2.6 dcache system is much more scalable than the 2.4 version was, a number of issues still need to be investigated:
Updates still are gated by dcache_lock, which means that update-intensive workloads do not scale well.
The global hash table defeats cache locality and makes update code more complex than necessary. Of course, any alternative must preserve its benefits, including high-performance handling of large directories.
The 2.6 dcache code acquires each dentry's d_lock spinlock, resulting in cache-line bouncing and atomic operations, particularly on the root directory and on working directories. Much thought is needed to arrive at a simple solution, as moving permissions into the dentry turns out to be quite complex.
The code that resolves races between __d_lookup() and d_move() is overly complex.
We eagerly anticipate participating in the 2.7 effort to resolve these issues, hopefully resulting in the situation shown in Figure 10.

Figure 10. Tux's Duty in 2.7
This work represents the view of the author and does not necessarily represent the view of IBM.
SPEC and the benchmark name SPECweb are registered trademarks of the Standard Performance Evaluation Corporation. The benchmarking was done for research purposes only and may not be compared to published results on the SPECWeb site, due to the following deviations from the rules:
It was run on hardware that does not meet the SPEC availability-to-the-public criteria. The machine was an engineering sample.
access_log was not kept for full accounting. It was being written but deleted every 200 seconds.
For the latest SPECweb99 benchmark results, visit www.spec.org.
Paul E. McKenney is a distinguished engineer at IBM and has worked on SMP and NUMA algorithms for longer than he cares to admit. Prior to that, he worked on packet-radio and Internet protocols (but long before the Internet became popular). His hobbies include running and the usual house-wife-and-kids habit.
Dipankar Sarma currently is working on a number of Linux kernel projects, including CPU hot-plug, RCU and VFS enhancements. Prior to his Linux days, he worked on a number of areas including ABI, OS bringup, I/O drivers and multipath I/O.
Maneesh Soni has been working with IBM's Linux Technology Center as a member of Linux Scalability Effort Project. He has experience in the system software arena, particularly with operating-system kernels and filesystems.

