
Paranoid Penguin - Authenticate with LDAP, Part III
For the past couple of months in the Paranoid Penguin column, we've been building an LDAP server. We've installed OpenLDAP; configured slapd, the server dæmon; made TLS encryption work; and created our first LDAP record, a root organization entry. Now, it's time to add some users and start using our server for authenticating IMAP sessions.
The first step in creating an LDAP user database is to decide on a directory structure, including whether to group users and other entities or use a completely flat structure. If your LDAP database is strictly an on-line address book or authentication server, a flat database may suffice. In that case, your users' Distinguished Names (DNs) should look like this: dn=Mick Bauer,dc=wiremonkeys,dc=org.
If, however, your database contains information not only about individual users but also records for organizational subgroups or departments, for computers on your network and so on, you'll probably want to use a more sophisticated directory tree structure. There are a variety of ways to do this. One is by using domainComponent (dc) fields to create subdomains of your domain name, regardless of whether these actually exist in DNS. The method looks like dn=Bick Mauer,dc=engineering,dc=wiremonkeys,dc=org. Another is to use organizationalUnit objects in the same way, for example, dn=Dick Lauer,ou=engineering,dc=wiremonkeys,dc=org.
In order to keep this discussion simple, I use a flat database for the rest of the article; I leave it to you to determine whether and how to structure an LDAP database that best meets your particular LDAP needs. The documentation found at www.openldap.org and included with OpenLDAP software provides ample examples.
Another decision you need to make is which LDAP attributes you want to include for each record. Last month, I described how these are grouped and interrelated in schemas. You may recall that the schemas you specify, or include, in /etc/openldap/slapd.conf determine which attributes are available for you to use in records.
In addition to including schema in /etc/openldap/slapd.conf, in each record you create you need to use objectClass statements to associate the appropriate schemas with each user. Again, as discussed last time, the schema files in /etc/openldap/schema determine which schema support which attributes, and within a given schema, which object classes to which those attributes apply.
Suppose you intend to use your LDAP server to authenticate IMAP connections. The essential LDAP attributes for this purpose are uid and userPassword. This also holds true for any other application that authenticates to LDAP using the Bind method, in which the authenticating service simply attempts to bind to the LDAP server using the user name and password supplied by the user. If the bind succeeds, authentication is judged successful, and the LDAP connection is closed.
One way to determine which schema and object classes provide uid and userPassword is to grep the contents of /etc/openldap/schema for the strings uid and userPassword, note which files contain them and then manually parse those files to find the object classes that contain those attributes in MUST() or MAY() statements. If I do this for uid on a Red Hat 7.3 system running OpenLDAP 2.0, I find that the files core.schema, cosine.schema, inetorgperson.schema, nis.schema and openldap.schema contain references to the uid attribute.
Quick scans of these files (using less) tell me the following: core.schema's object uidObject requires uid; cosine.schema's only reference to the attribute uid is commented out and can be disregarded; inetorgperson.schema contains an object class, inetOrgPerson, that supports uid as an optional attribute; nis.schema contains two object classes, posixAccount and shadowAccount, both of which require uid; and openldap.schema's object class OpenLDAPperson also requires uid.
Luckily, there's a much faster way to determine the same information. The gq LDAP tool allows you to browse all supported attributes in all supported schema on your LDAP server. Figure 1 is a screenshot illustrating my LDAP server's support for uid, according to gq.
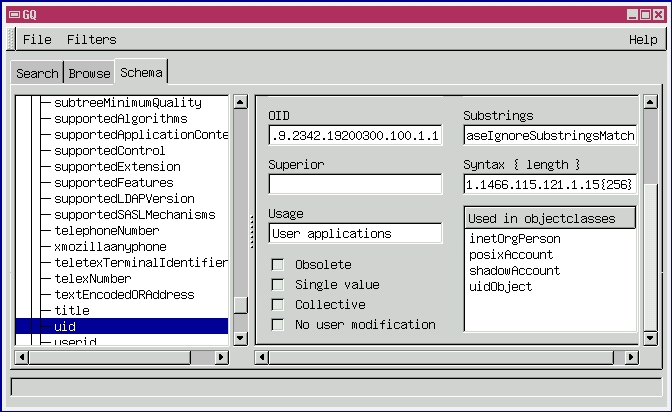
Figure 1. Schema Browsing with gq
The Used in objectclasses box in Figure 1 tells us that the selected attribute, uid, appears in the object classes uidObject, posixAccount, shadowAccount and inetOrgPerson, all of which we identified earlier using grep. The object class OpenLDAPperson does not appear in the gq screen, because the LDAP server in question doesn't have an include statement in its /etc/openldap/slapd.conf file for the file openldap.schema. When in doubt, you should include schema you're not sure you need. After you settle on an LDAP record format, you can always un-include schema that don't contain object classes you need.
All this probably sounds like a lot of trouble and indeed it can be, but it's extremely important to be able to create records that contain the kinds of information pertinent to your LDAP needs. Because LDAP is so flexible, figuring out precisely how to assemble that information in the form of attributes can take some tinkering.
Just as schema browsing can be done either manually or with a GUI, so can adding LDAP records. We used the manual method last month to create our root organization entry, and we'll do so again to add our first user record. This method has two steps: first, create a special text file in LDIF format, then use the ldapadd command to import it into the LDAP database. Consider the LDIF file in Listing 1.
Listing 1. LDIF File for a User Record
dn: cn=Wong Fei Hung,dc=wiremonkeys,dc=org cn: Wong Fei Hung sn: Wong givenname: Fei Hung objectclass: person objectclass: top objectclass: inetOrgPerson mail: wongfh@wiremonkeys.org telephonenumber: 651-344-1043 o: Wiremonkeys uid: wongfh
Because they determine everything else, we'll begin by examining Listing 1's objectclass statements: this user has been associated with the object classes top (mandatory for all records), person and inetorgperson. I chose person because it supports the attributes userPassword (which is not set in Listing 1; we'll set Mr. Wong's password shortly) and telephonenumber, which I don't need now but may in the future. The object class inetOrgPerson supports the uid attribute, plus a whole slew of others that also may come in handy later.
One way around having to know and comply with the MUST and MAY restrictions in schema is to add the statement schemacheck off to /etc/openldap/slapd.conf. This allows you to use any attribute defined in any schema file included in slapd.conf without needing to pay any attention to object classes. However, it also adversely affects your LDAP server's interoperability with other LDAP servers and even with other applications (besides flouting LDAP RFCs), so many LDAP experts consider it poor form to disable schema checking in this manner.
It isn't necessary to discuss each and every line in Listing 1; many of the attributes are self-explanatory. In short, know that you don't need to set every attribute you intend to use, but some are mandatory; they are contained in MUST() statements in their respective object class definitions. Each attribute you do define must be specified in the MUST() or MAY() statement of at least one of the object classes defined in the record, and some attributes, such as cn, may be defined multiple times in the same record.
To add the record specified in Listing 1, use the ldapadd command:
$ ldapadd -x \ -D "cn=ldapguy,dc=wiremonkeys,dc=org" \ -W -f ./wong.ldif
This is similar to how we used ldapadd in last month's column. For a complete explanation of this command's syntax, see the ldapadd(1) man page.
If you specified the attributes required by all object classes set in the LDIF file, if all attributes you specified are supported by those object classes and if you provide the correct LDAP bind password when prompted, the record is added to the database. If any of those conditions is false, however, the action fails and ldapadd tells you what went wrong. Thus, you can use trial and error to craft a workable record format. After you've figured this out the first time, you can use the same format for subsequent records, without going through all this schema-induced zaniness.
I offer one caveat: say your LDIF file contains multiple records, which is permitted, if your LDAP server detects an error, it quits parsing the file and does not attempt to add any records below the one that failed. Therefore, you should stick to single-record LDIF files for the first couple of user adds, until you've finalized your record format.
The manual record creation method is a little clunky, but it accommodates a certain amount of tinkering. This is especially useful in the early stages of LDAP database construction.
Once you have a user record or two in place, you can use a GUI tool such as LDAP Browser/Editor (www.iit.edu/~gawojar/ldap) or gq (included in most Linux distributions) to create additional records. In gq, for example, left-clicking on a record pops up a menu containing the option New→Use current entry, which copies the selected record into a new record. This is much faster and simpler than typing everything into an LDIF file manually.
I mentioned in the description of Listing 1 that we generally don't specify user passwords in LDIF files. A separate mechanism is used for that, in the form of the command ldappasswd. By design, its syntax is similar to that of ldapadd:
bind-$ ldappasswd -S -x -D "cn=hostmaster,dc=upstreamsolutions,dc=com" \ -W "cn=Phil Lesh,dc=upstreamsolutions,dc=com"
You don't need to be logged in to a shell session on the LDAP server to use the ldappasswd command. You instead can use the -H option to specify the URL of a remote LDAP server, like this:
$ ldappasswd -S -x \ -H ldaps://ldap.upstreamsolutions.com \ -D "cn=hostmaster,dc=upstreamsolutions,dc=com" \ -W "cn=Phil Lesh,dc=upstreamsolutions,dc=com"
This option also may be used with ldapadd.
The ldaps:// URL is required in the above example. I've specified the -x option for simple clear-text authentication, so I definitely need to connect to the server with TLS encryption rather than in the clear. Last month, I showed how to set up an LDAP server to accept TLS connections.
Having said all that, however, I must point out that password management for end users is one of LDAP's problem areas. On the one hand, if your users all have access to the ldappasswd command, you can use a combination of local /etc/ldap.conf files and scripts/front ends for ldappasswd to make it reasonably simple for users to change their own passwords.
But for users who run some other OS, you must manage passwords centrally and have all users contact the e-mail administrator every time they need to change their password, or you must install LDAP client software for their OS. For client systems running Microsoft Windows, you can configure Samba to let users change their LDAP password with the Windows password tool. See the article “OpenLDAP Everywhere” in LJ, December 2002.
Technically, we've covered or touched on all the tasks needed to build an LDAP server using OpenLDAP (excluding, necessarily, the sometimes lengthy step of actually getting your various server applications to authenticate users against it successfully). In the interests of robust security, a concept not alien to readers of this column, we need to discuss one more thing: OpenLDAP access control lists (ACLs).
As with most other things affecting the slapd dæmon, ACLs are set in /etc/openldap/slapd.conf. And, like most other things involving LDAP, ACLs can be confusing to say the least and usually require some tinkering to get right. Listing 2 shows a sample set of ACLs.
Listing 2. ACLs in /etc/slapd.conf
access to attrs=userPassword
by dn="cn=ldapguy,dc=wiremonkeys,dc=org" write
by self write
by * compare
access to *
by dn="cn=ldapguy,dc=wiremonkeys,dc=org" write
by users read
by * auth
ACLs are described in detail in the slapd.conf(5) man page, but in Listing 2 you can see generally how they work. For each LDAP element to which you wish to control access, you specify who may access it and with what level of access. Technically, an entire ACL can be listed on one line, but by convention we list each “by...” statement on its own line. slapd is smart enough to know that the string “access to” marks the beginning of the next ACL.
Space doesn't permit my describing ACL syntax in detail, but remember a few important points. First, ACLs are parsed from top to bottom, and first match wins; they act like a stack of filters. Therefore, it's crucial that you put specific ACLs and by statements above more general ones. For example, in Listing 2 we see an ACL restricting access to the userPassword attribute, followed by one applicable to *, that is, the entire LDAP database. Putting the userPassword ACL first means the rule that allows users to change their own passwords (access to attrs=userPassword by self write) is an exception to the more general rule stating users may read anything (access to * by users read).
Another important point is access levels are hierarchical. Possible levels are none, auth, compare, search, read and write, where none is the lowest level of access and write is the highest, and where each level includes the rights of all levels lower than it. These two points, the first match wins rule and the inclusive nature of access levels, are crucial to understanding how ACLs are parsed. They also are important for making sure your ACLs don't lead to either greater or lesser levels of access than you intend in a given situation.
LDAP is one of the most complicated technologies I personally have worked with lately. To make it work the way you need, you have to spend a lot of time testing while watching logs and fine-tuning the configurations of both the LDAP server and the applications you wish to authenticate against it. But, having such a flexible, powerful and widely supported authentication and directory mechanism is well worth the trouble. I hope this series of articles has helped you get there or at least pointed you in the right direction.
Resources
OpenLDAP software and documentation, including the important “OpenLDAP Administrator's Guide”: www.openldap.org.
List of error codes used in LDAP error messages. This is essential in interpreting LDAP log messages: www-user.tu-chemnitz.de/~fri/web500gw/errors.html.
The Exchange Replacement HOWTO, which describes how to use LDAP as the authentication mechanism for Cyrus-IMAPD: www.arrayservices.com/projects/Exchange-HOWTO/html/book1.html.
Carter, Gerald. LDAP System Administration. Sebastopol, California: O'Reilly & Associates, 2003. An excellent new book with detailed coverage of OpenLDAP.
Mick Bauer, CISSP, is Linux Journal's security editor and an IS security consultant for Upstream Solutions LLC in Minneapolis, Minnesota. Mick spends his copious free time chasing little kids (strictly his own) and playing music, sometimes simultaneously. Mick is author of Building Secure Servers With Linux (O'Reilly & Associates, 2002).
