
An Event Mechanism for Linux
This article is the first in a series describing a new event-based mechanism for Linux. This particular article focuses on the motivation, requirements and benefits of such a mechanism for carrier-grade Linux.
The work of supporting a native event-based system in the Linux kernel started as a research project in 2001 at the Open Systems Lab (Ericsson Research, Corporate Unit) in Montréal, Canada. The goal was to provide Linux with an event-driven environment that could deliver better performance compared to existing solutions in the context of telecom applications.
There has been a growing interest in bringing the Linux operating system to a carrier-grade level. For example, the OSDL Carrier-Grade Linux working group (www.osdl.org/projects/cgl) currently is drafting a set of requirements to turn Linux into a solid carrier-grade server for Next Generation Networks.
Operating systems for telecom applications must ensure that they can deliver a high response rate with minimum downtime—less than five minutes per year, 99.999% of uptime—including hardware, operating system and software upgrade. In addition to this goal, a carrier-grade system also must take into account such characteristics as scalability, high availability and performance.
For such systems, thousands of requests must be handled concurrently without impacting the overall system's performance, even under high load. Subscribers can expect some latency time when issuing a request, but they are not willing to accept an unbounded response time. Such transactions are not handled instantaneously for many reasons, and it can take some milliseconds or seconds to reply. Waiting for an answer reduces applications' abilities to handle other transactions.
Many different solutions have been envisaged to improve Linux's capabilities using different types of software organization, such as multithreaded architectures, by implementing efficient POSIX interfaces or by improving the scalability of existing kernel routines. We think that none of these solutions are adequate for true carrier-grade servers.
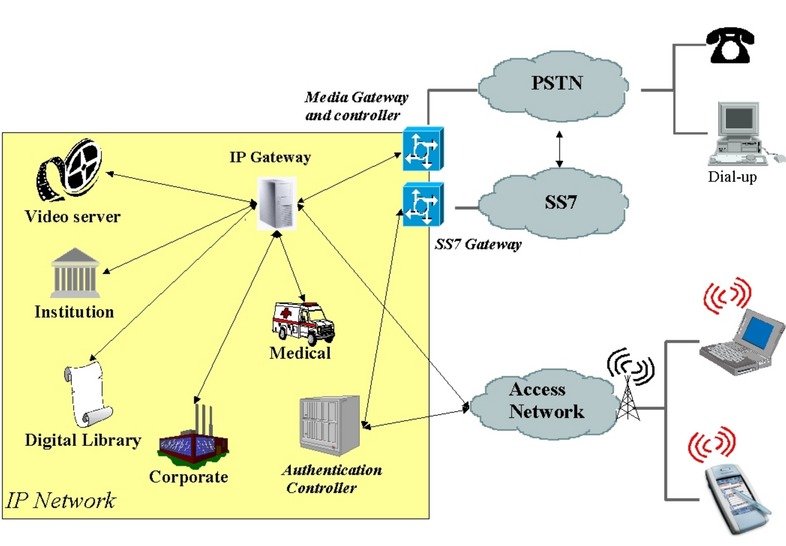
Figure 1. Architecture and Interoperability between the PSTN and IP Networks
In order to understand our point, this article provides an overview of telecom networks. The purpose is to clarify the requirements for a carrier-grade operating system. After this introduction, we explain the benefits of a native asynchronous event mechanism to better support carrier-grade characteristics.
Telecommunications is concerned with the establishment of telephone calls between two devices and the transport of voice over wire links. Figure 1 shows the traditional Public Switched Telephone Network (PSTN). More specifically, carriers use the term signaling to indicate the establishment of a telephone call between two devices. Signaling in the PSTN is done through the Signaling System 7 (SS7) protocol stack. SS7 performs call routing and builds a path to the destination telephone through the circuits. The two phones are connected once the path is established and the voice can be carried over. The SS7 protocol is able to handle call routing, call forwarding and error conditions.
The flexibility, cost performance and continuous growth of the Internet are driving a migration of many telecom services to it. This helps to establish IP technologies as the new standard for all communications services. These two types of networks are based on different technologies and require the utilization of signaling and media gateways for inter-working purposes.
Gateways perform the translation of information between different types of network. For example, an SS7 gateway is used to encapsulate signaling over the IP network through the Stream Control Transmission Protocol (SCTP). A media gateway is used to encode and decode the voice coming from the PSTN network and going to the IP network and vice versa.
The signaling and the media gateways provide connectivity to the IP network for calls coming from the PSTN network. Signaling gateways must perform protocol encapsulation in order to carry the syntax and semantics of SS7 messages over an internet protocol, such as SCTP over IP or UDP over IP. Signaling servers must be able to scale with respect to their system capabilities as the number of concurrent requests increases.
With a media gateway, operators can implement transport of streaming data between the PSTN and the IP networks. The number of connections they can accept depends on their hardware, which can vary in size from one to thousands of interfaces. Media gateways must support a large number of connections in real time.
Authentication, authorization and accounting (AAA) servers maintain databases of user profiles. Typically, one or two AAA servers may contain information about several millions of subscribers belonging to a particular network operator. It is common to observe peaks of thousands of concurrent authentication requests per second. Such variation in the number of connections is difficult to plan for in advance. AAA servers have a critical role of controlling access to the IP network and are not allowed to fail. They require soft real-time capabilities, so they can reply to most requests within a few milliseconds.
Media servers provide specialized resources and services to end users, such as video conferences, video servers, applications and e-mail. An important aspect of these carrier-class systems is scalability. These platforms can accept a linear increase of the number of transactions with respect to the number of processors, interfaces or bandwidth. Telecom operators speak of linear scalability, meaning the cost per transaction or per user should not increase when scaling up a server.
In case of failure or unplanned interruption, carrier-grade platforms can recover automatically or failover to another server through network redundancy procedures. Live software upgrades and hot swap of hardware devices also are part of the 99.999% service availability.
Linux has proven to be stable and consistent over the years, and it is already an attractive option for carriers. In order to become a key element of telecom networks, however, it must be enhanced with components providing these much-needed carrier-grade capabilities.
In the traditional programming model, software components explicitly synchronize with others. This is the common model when a lot of interaction is required. For example, the typical approach is to use select() or poll() to listen to file descriptors. A generic implementation of select scans the entire array of descriptors. This is not scalable because the time it takes to detect activity on a descriptor is proportional to the size of the array. This increases the application latency and leads to a decrease in the overall system performance.
Scanning an array of descriptors or waiting for data consumes processing time. A common idea in the design of efficient algorithms is to handle system events asynchronously. Some examples of mechanisms that provide event notification to user-space applications are the POSIX AIO, epoll or the BSD kqueue (see Resources).
When describing the efficiency of such mechanisms, it is common to compute the average time it takes from the moment an event is detected in the kernel to the moment it is effectively handled by the application. One of the main reasons this is done is that micro-benchmarks for this type of method are not relevant. Such mechanisms can be quite efficient locally but inefficient when combined with other mechanisms not well adapted, such as multithreaded architectures. As an example, many web servers use a pool of threads that is started when the application is launched. A typical architecture is to use one dedicated thread to manage incoming connections and one thread per transaction. Usually this design is efficient for a low number of incoming connections but is inefficient when the load goes higher.
Multithreaded applications are needed when a high level of concurrency is required between objects competing for the CPU. Well-known examples are found in high-performance computing applications where the speed of execution of every thread is important, but the number of threads run is not high.
Threads provide a sequential and synchronous model of development, and they have become the standard way of implementing applications when a high level of concurrency is needed. But flaws in the design of applications or flaws in handling synchronizations easily can create system contentions and affect the overall system performance. J. Ousterhout, in “Why Threads Are a Bad Idea”, established that programming with threads is quite difficult and mainly leads to applications unable to execute properly under high loads.
No competition between threads exists in telecom applications. But concurrency occurs when handling common objects, such as distributed data structures. For these applications, threads are needed to provide concurrent accesses to shared data.
Telecom applications are used to handle thousands of transactions per second and hundreds of simultaneous connections on the same processor. In addition, system events, including database accesses, applications faults, overload notifications, alarms, state change of system components and so on, must be taken into account. Thousands of events can be generated in the same system during the execution of an application, so managing events with threads would be inefficient.
Traditional asynchronous mechanisms try to solve this scalability issue by preventing applications from waiting unnecessarily or, like epoll on Linux, they aim to improve the detection of active descriptors. Unfortunately, these solutions are limited to file descriptors, which represent only a fraction of the events of interest. Also, starting a huge number of threads, as needed for web servers to handle these events, would create a bottleneck and aggravate the situation.
The development of complex distributed software architectures demands the implementation of a mechanism that is suitable to take advantage of system resources at runtime. A promising solution that is more appropriate to address this issue is the introduction of an event-based mechanism in Linux. Such mechanisms enable a real cooperation between the operating system and the applications. They provide components able to register for events that can be asynchronously notified later, through the execution of handlers.
If we compare signal handlers and event handlers, we find the latter more informative because they bring the data directly to the application. Basically, an asynchronous event mechanism can be used to implement generic user-level handlers triggered by system events or to implement periodic monitoring components, like timers. The first case is particularly interesting if an application doesn't know when an event occurs. When receiving events asynchronously, the application can take action without recovering all the necessary data because it is supplied in parameters.
Some investigations already have been done regarding fast message-passing mechanisms, which are based on the same principles as asynchronous events. For example, active messages (see Resources) execute asynchronously on the stack of the receiver process. In pop-up threads, a thread of execution is created for every handler, and in single-threaded upcalls, a dedicated thread is created on each processor. AEM is an emerging mechanism that offers a native environment for the development of applications requiring real asynchrony. For example, we used AEM to implement a native asynchronous socket interface for TCP. In AEM, the choice is made at registration time to define a handler that is executed on either the current execution task or a new thread of execution. Some other research projects have proposed similar solutions to improve web server capabilities under high load (see “A Scalable and Explicit Event Delivery Mechanism for UNIX”, Resources).
The main benefit of the event paradigm is the integration of event handling and thread management in the same mechanism. Concretely, it gives full control to resource consumption.
Performance is really a goal for event-based mechanisms. Decoupling event management from the application permits increased locality by taking advantage of different memory allocation schemes or influencing the scheduler decision. For example, soft real-time responsiveness is ensured by enforcing process priorities depending on pending events.
This emerging paradigm provides a simpler and more natural programming style compared to the complexity offered by multithreaded architectures. It proves its efficiency for the development of multilayer software architectures, where each layer provides a service to the upper layer. This type of architecture is quite common for distributed applications.
Figure 2 illustrates a typical distributed application based on an event-driven model. It is composed of many software components, and a process represents one layer of the application. In distributed applications, a lot of local and remote communications are engaged either at the same level or at a different level.
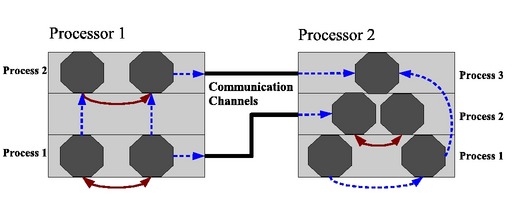
Figure 2. A multilayer distributed application designed with an event-based model running on two processors. Each layer is single-threaded, and the communication between application components is either synchronous (plain lines) or asynchronous (dashed lines).
In many situations such applications have to provide services that must operate worldwide with high performance. It is essential that these applications take advantage of hardware resources and scale linearly with respect to the platform's capabilities.
The design of this software must ensure that no deadlock or race condition is possible between the components. The impact of such design flaws on system integrity can be catastrophic. This situation is difficult to solve when using a multithreaded approach, because it is hard to detect and correct due to the high number of possible configurations. An event-based mechanism reduces the chance of introducing points of failure by controlling the number of threads started asynchronously. It is easier to guarantee atomicity of handler executions, because the mechanism is kept in the kernel.
System resources are limited, and the number of processes that can be started is always limited. At registration time, the alternative is given to choose the type of handler to execute. This permits the production of more robust applications as the load increases. The main advantage for applications is the possibility to mix sequential code and asynchronous code. It then is possible to design applications that exploit capabilities of both strategies.
An event-based framework offers operators dynamic reconfiguration with minimum impact on the system uptime. Hardware hot swap and dynamic software upgrade must be possible without restarting the system. Distributed applications are built from a large number of interacting components, and upgrading such software is a critical operation.
Telecom platforms require 99.999% uptime for all services. The services cannot be stopped during maintenance operations, as this would impact other service platforms and subscriber requests connected to it. Software upgrades must be performed gradually. Event-based mechanisms introduce the potential for such capability to distributed applications. As we can see in Figure 2, there are no direct dependencies between software layers if communication is performed asynchronously. It then is possible to replace some of the application parts without major disturbance.
An event-based mechanism provides a new programming model that offers software developers unique and powerful support for asynchronous execution of processes. Of course, it radically differs from the sequential programming styles we are used to but offers a design framework better structured for software development. It also simplifies the integration and the interoperability of complex software components.
The strength of such a mechanism is its ability to combine synchronous code and asynchronous code in the same application—or even mix these two types of models within the same code routine. With this hybrid approach, it is possible to take advantage of their respective capabilities depending on the situation. This model is especially favorable for the development of secure software and for the long-term maintenance of mission-critical applications.
In a future article, we will show how AEM has been implemented to provide this support in the Linux kernel and how to use it for software development.
email: Frederic.Rossi@ericsson.ca
Frederic Rossi is a researcher at the Open Systems Lab at Ericsson Research, Corporate Unit, in Montréal, Canada. He is involved in research activities leading to designing kernel components for the advancement of carrier-class operating systems. He can be reached by e-mail at frederic.rossi@ericsson.ca.


