
Introducing the 2.6 Kernel
The kernel has come a long way since Linus branched off 2.4.15 to create 2.5.0 back on November 22, 2001. Since then, rapid development has ensued, resulting in a drastically different and much-improved kernel. This article discusses the more interesting, important features and their impact on the performance and reliability of Linux.
In Linux kernel parlance, the minor version number of a kernel denotes whether that kernel belongs to a stable series or a development series. Even minor version numbers denote stable kernels, and odd minor version numbers denote development kernels. When a development kernel is fully mature and deemed stable, its minor version number is incremented to an even value. For example, the 2.3 kernel development series gave way to the 2.4 stable series.
The current development kernel is 2.5. The initial work on a development series is quite brisk, and many new features and improvements are incorporated. When Linus and the kernel developers are satisfied with the new feature set, a feature-freeze is declared, which has the purpose of slowing development. The last feature-freeze occurred on October 31, 2002. Ideally, when a feature-freeze is declared, Linus will not accept new features—only additions to existing work. When the existing features are complete and nearly stable, a code-freeze is declared. During a code-freeze, only bug fixes are accepted, in order to prepare the kernel for a stable release.
When the development series is complete, Linus releases the kernel as stable. This time around, the stable kernel most likely will be version 2.6.0. Although the official release date is “when it is done”, a good estimate is third or fourth quarter 2003.
In March 2001 and again in June 2002, the core kernel developers met at Kernel Summits to discuss the kernel. The primary goal of 2.5 was to bring the aging block layer (the part of the kernel responsible for block devices, such as hard drives) into the 21st century. Other concerns centered on scalability, system response and virtual memory (VM). The kernel hackers met all—and many more—of these goals. The list of important new features includes:
O(1) scheduler
preemptive kernel
latency improvements
redesigned block layer
improved VM subsystem
improved threading support
new sound layer
In this article, I discuss a lot of new technology and innovation that has gone into the 2.5 kernel and will appear in 2.6. The development is the result of hard work from many individuals. I am going to refrain from mentioning names, because if I start giving credit I inevitably will miss some people, and I would rather give no list than an incomplete or incorrect one. The Linux Kernel Mailing List archive is a good source of who did what.
The process scheduler (or, simply, the scheduler) is the subsystem of the kernel responsible for allocating processor time. It decides which process gets to run when. This is not always an easy job. From a possibly large list of processes, the scheduler must ensure that the most worthy one is always running. When there is a large number of runnable processes, selecting the best process may take some time. Machines with multiple processors only add to the challenge.
Improvements to the scheduler ranked high on the list of needed improvements. Specifically, developers had three specific goals:
The scheduler should provide full O(1) scheduling. Every algorithm in the scheduler should complete in constant time, regardless of the number of running processes.
The scheduler should have perfect SMP scalability. Ideally, each processor should have its own locking and individual runqueue. A runqueue is the list of runnable processes from which the scheduler chooses.
The scheduler should have improved SMP affinity. It should naturally attempt to group tasks on a specific CPU and run them there. It should migrate tasks from one CPU to another only to resolve imbalances in runqueue length.
The new scheduler accomplishes all of these goals. The first goal was full O(1) scheduling. O(1) denotes an algorithm that executes in constant (fixed) time. The number of runnable tasks on a system—or any other variable, for that matter—has no bearing on the time to execute any part of the scheduler. Consider the algorithm for deciding which task should run next. This job involves looking at the highest priority task, with timeslice remaining, that is runnable. In the previous scheduler, the algorithm was analogous to:
for (each runnable process on the system) {
find worthiness of this process
if (this is the worthiest process yet) {
remember it
}
}
run the most worthy process
With this algorithm, the worthiness of each process must be checked. This implies the algorithm loops n-times for n processes. Hence, this is an O(n) algorithm—it scales linearly with the number of processes.
Conversely, the new scheduler is constant with respect to the number of processes; it does not matter whether there are five or 5,000 runnable processes on the system. It always takes the same amount of time to select and begin executing a new process:
get the highest priority level that has processes get first process in the list at that priority level run this process
In this algorithm, it is possible to simply “get the highest priority level” and “get first process in the list”, because the scheduler keeps track of these things. It simply has to look up, instead of search for, these values. Consequently, the new scheduler can select the next process to schedule without looping over all runnable processes.
The second goal is perfect SMP scalability. This implies the performance of the scheduler on a given processor remains the same as one adds more processors to the system, which was not the case with the previous scheduler. Instead, the performance of the scheduler degraded as the number of processors increased, due to lock contention. The overhead of keeping the scheduler and all of its data structures consistent is reasonably high, and the largest source of this contention was the runqueue. To ensure that only one processor can concurrently manipulate the runqueue, it is protected by a lock. This means, effectively, only one processor can execute the scheduler concurrently.
To solve this problem, the new scheduler divides the single global runqueue into a unique runqueue per processor. This design is often called a multiqueue scheduler. Each processor's runqueue has a separate selection of the runnable tasks on a system. When a specific processor executes the scheduler, it selects only from its runqueue. Consequently, the runqueues receive much less contention, and performance does not degrade as the number of processors in the system increases. Figure 1 is an example of a dual-processor machine with a global runqueue vs. a dual-processor machine with per-processor runqueues.

Figure 1. Left, the 2.4 Runqueue; Right, the 2.5/2.6 Runqueue
The third and final goal was improved SMP affinity. The previous Linux scheduler had the undesirable characteristic of bouncing processes between multiple processors. Developers call this behavior the ping-pong effect. Table 1 demonstrates this effect at its worst.
Table 1. A Worst-Case Example of the Ping-Pong Effect
The new scheduler solves this problem, thanks to the new per-processor runqueues. Because each processor has a unique list of runnable processes, processes remain on the same processor. Table 2 shows an example of this improved behavior. Of course, sometimes processes do need to move from one processor to another, like when an imbalance in the number of processes on each processor occurs. In this case, a special load balancer mechanism migrates processes to even out the runqueues. This action occurs relatively infrequently, so SMP affinity is well preserved.
Table 2. The New Scheduler Preserves CPU Affinity
The new scheduler has a lot more features than its name implies. Table 3 is a benchmark showing off the new scheduler.
The purpose of kernel preemption is to lower scheduling latency. The result is improved system response and interactive feel of the system. The Linux kernel became preemptive with version 2.5.4. Previously, kernel code executed cooperatively. This meant a process—even a real-time one—could not preempt another process executing a system call in the kernel. Consequently, a lower priority process could priority invert a higher priority process by denying it access to the processor when it requested it. Even if the lower priority process' timeslice expired, it would continue running until it completed its work in the kernel or voluntarily relinquished control. If the higher priority process waiting to run is a text editor in which the user is typing or an MP3 player ready to refill its audio buffer, the result is poor interactive performance. Worse, if the higher priority process is a specialized real-time process, the result could be catastrophic.
Why was the kernel not preemptive from the start? Because it is more work to provide a preemptive kernel. If tasks in the kernel can reschedule at any moment, protection must be in place to prevent concurrent access to shared data. Thankfully, the issues a preemptive kernel creates are identical to the concerns raised by symmetrical multiprocessing (SMP). The mechanisms that provide protection under SMP were adapted easily to provide protection with kernel preemption. Thus, the kernel simply leverages SMP spinlocks as preemption markers. When code would hold a lock, preemption is similarly disabled. Otherwise, it is safe to preempt the current task.
Most likely, one can now see the next bottleneck. The preemptive kernel simply reduces scheduling latency from the entire length of kernel execution to the duration of spinlocks. It's definitely shorter, sure, but it's still a potential problem. Thankfully, reducing lock duration, which is equal to the length of time kernel preemption is disabled, is doable.
Kernel developers optimized kernel algorithms for lower latency. They primarily concentrated on the VM and virtual filesystem (VFS) and, consequently, greatly reduced the lock duration. The result is excellent system response. Users have observed worst-case scheduling latency in 2.5, even on average machines, at less than 500 nanoseconds.
The block layer is the chunk of the kernel responsible for supporting block devices. Traditional UNIX systems support two general types of hardware devices, character devices and block devices. Character devices, such as serial ports and keyboards, manipulate data as a stream of characters, or bytes, one at a time. Conversely, block devices manipulate data in groups of a fixed size (called blocks). Block devices do not merely send or receive a stream of data; instead, any of their blocks are accessible. Moving to one block from another is called seeking. Examples of block devices include hard disks, CD-ROM drives and tape backup devices.
Managing block devices is a nontrivial job. Hard disks are complicated pieces of hardware for which the operating system needs to support arbitrary reading and writing of any valid block. Further, because seeks are expensive, the operating system must intelligently manage and queue requests to block devices to minimize seeks.
The block layer in Linux was in serious need of a redesign. Thankfully, starting with kernel 2.5.1, the revamp began. The most interesting work involved creating a new flexible and generic structure to represent block I/O requests, eliminating bounce buffers and supporting I/O directly into high memory, making the global io_request_lock per queue and building a new I/O scheduler.
Prior to 2.5, the block layer used the buffer_head structure to represent I/O requests. This method was inefficient for several reasons, the largest being the block layer often had to break the data structures into smaller chunks, only to reconstruct them later in the I/O scheduler. In 2.5, the kernel makes use of a new data structure, struct bio, to represent I/O. This structure is simpler, appropriate for both raw and buffered I/O, works with high memory and may be split and merged easily. The block layer consistently uses the new bio structure, resulting in cleaner, more efficient code.
The next issue was eliminating the bounce buffer used when performing I/O into high memory. In the 2.4 kernel, an I/O transfer from a block device into high memory has to make an unfortunate extra stop. High memory is non-permanently mapped memory for which the kernel must provide special support. On Intel x86 machines, this is any memory over about 1GB. Any I/O request into high memory (for example, reading a file from a hard drive into a memory address greater than 1GB) must make use of a special bounce buffer that resides in low memory. The rationale is that some devices may be unable to understand high memory addresses. The result is devices always must perform their I/O transfers into low memory. If the final destination is in fact high memory, the data must bounce from the block device to low memory and finally into high memory (Figure 2). This extra copy introduces significant overhead. The 2.5 kernel now automatically supports transferring directly into high memory, eliminating the bounce buffer logic for devices that are capable.

Figure 2. The Bounce Buffer in the 2.4 Kernel
The next bottleneck that developers tackled was the global I/O request lock. Each block device is associated with a request queue, which stores block I/O requests, the individual bio structures that represent each block read or write. The kernel constantly updates the queues as drivers add or remove requests. The io_request_lock protects the queues from concurrent access—code may update a queue only while holding the lock. In kernels prior to 2.5, a single global lock protects all the request queues in the system. The global lock prevents concurrent access to any queue, and the lock merely needs to prevent concurrent access to any single queue. In 2.5, a fine-grained lock for each queue replaced the global request lock (Figure 3). Consequently, the kernel now can manipulate multiple queues at the same time.
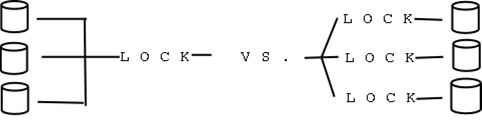
Figure 3. The 2.5 kernel introduces one lock per request queue.
Finally, a new I/O scheduler solved the remaining block layer inefficiency. The I/O scheduler is responsible for merging block requests and sending them to the physical devices. Because seeks are expensive, the I/O scheduler prefers to service contiguous requests. To this end, it sorts incoming requests by sector. This is an important feature for both disk performance and longevity. The problem is, however, that repeated I/O requests to contiguous sectors could prevent servicing of a request for a nonadjacent sector. The new I/O scheduler solves this problem by implementing deadlines for I/O requests. If the I/O scheduler starves a request past its deadline, the I/O scheduler services the starved request rather than continuing to merge requests at the current sector. The new I/O scheduler also solves the writes-starving-reads problem by giving preferential treatment to read requests over write requests. This change greatly improves read latency. Last but not least, the request queue is now a red/black tree, which is an easily searchable data structure, instead of a linear list.
During 2.5, VM finally came into its own. The VM subsystem is the component of the kernel responsible for managing the virtual address space of each process. This includes the memory management scheme, the page eviction strategy (what to swap out when memory is low) and the page-in strategy (when to swap things back in). The VM often has been a rough issue for Linux. Good VM performance on a specific workload often implies poor performance elsewhere. A fair, simple, well-tuned VM always seemed unobtainable—until now.
The new VM is the result of three major changes:
reverse-mapping (rmap) VM
redesigned, smarter, simpler algorithms
tighter integration with the VFS layer
The net result is superior performance in the common case without the VM miserably falling to pieces in the corner cases. Let's briefly look at each of these three changes.
Any virtual memory system has both physical addresses (the address of actual pages on your physical RAM chips) and virtual addresses (the logical address presented to the application). Architectures with a memory management unit (MMU) allow convenient lookup of a physical address from a virtual address. This is desirable because programs are accessing virtual addresses constantly, and the hardware needs to convert this to a physical address. Moving in the reverse direction, however, is not so easy. In order to resolve from a physical to a virtual address, the kernel needs to scan each page table entry and look for the desired address, which is time consuming. A reverse-mapping VM provides a reverse map from virtual to physical addresses. Consequently, instead of:
for (each page table entry)
if (this physical address matches)
we found a corresponding virtual address
the rmap VM simply can look up the virtual address by following a pointer. This method is much faster, especially during intensive VM pressure. Figure 4 is a diagram of the reverse mapping.

Figure 4. Reverse mapping maps one physical page to one or more virtual pages.
Next, the VM hackers redesigned and improved many of the VM algorithms with simplification, great average-case performance and acceptable corner-case performance in mind. The resulting VM is simplified yet more robust.
Finally, integration between the VM and VFS was greatly improved. This is essential, as the two subsystems are intimately related. File and page write-back, read-ahead and buffer management was simplified. The pdflush pool of kernel threads replaced the bdflush kernel thread. The new threads are capable of providing much-improved disk saturation; one developer noted the code could keep sixty disk spindles concurrently saturated.
Thread support in Linux always has seemed like an afterthought. A threading model does not fit perfectly into the typical UNIX process model, and consequently, the Linux kernel did little to make threads feel welcome. The user-space pthread library (called LinuxThreads) that is part of glibc (the GNU C library) did not receive much help from the kernel. The result has been less than stellar thread performance. There was a lot of room for improvement, but only if the kernel and glibc hackers worked together.
Rejoice, because they did. The result is greatly improved kernel support for threads and a new user-space pthread library, called Native POSIX Threading Library (NPTL), which replaces LinuxThreads. NPTL, like LinuxThreads, is a 1:1 threading model. This means one kernel thread exists for every user-space thread. That developers achieved excellent performance without resorting to an M:N model (where the number of kernel threads may be dynamically less than the number of user-space threads) is quite impressive.
The combination of the kernel changes and NPTL results in improved performance and standards compliance. Some of the new changes include:
thread local storage support
O(1) exit() system call
improved PID allocator
clone() system call threading enhancements
thread-aware code dump support
threaded signal enhancements
a new fast user-space locking primitive (called futexes)
The results speak for themselves. On a given machine, with the 2.5 kernel and NPTL, the simultaneous creation and destruction of 100,000 threads takes less than two seconds. On the same machine, without the kernel changes and NPTL, the same test takes approximately 15 minutes.
Table 4 shows the results of a test of thread creation and exit performance between NPTL, NGPT (IBM's M:N pthread library, Next Generation POSIX Threads) and LinuxThreads. This test also creates 100,000 threads but in much smaller parallel increments. If you are not impressed yet, you are one tough sell.
The long-awaited merge of the advanced Linux sound architecture (ALSA) began in kernel 2.5.5. ALSA has a number of improvements over open sound system (OSS), the previous sound layer. Most importantly, ALSA provides a much more robust and feature-filled API than OSS. ALSA drivers and the accompanying user-space library (alsa-lib) allow for the creation of advanced audio applications with minimal effort.
ALSA supports a large number of sound devices and provides a backward-compatible OSS interface. For users who still require or prefer OSS, however, drivers most likely will remain through 2.6.
It may be a bit irresponsible to begin looking past 2.6 before it is even released. It is interesting, however, to consider what we may see (or at least want to see) in the 2.7 development kernel. With luck, we will see the long-desired tty (terminal) layer rewrite. The tty layer has grown into a large and confusing hack.
Also high on everyone's wish list is a SCSI layer rewrite. Currently, the SCSI layer is too dumb and its drivers are too smart. It also may be possible to unify parts of the IDE and SCSI layers into a generic disk layer. Whatever the case, the SCSI layer needs a bit of cleanup.
After these items, the rest is uncertain. It is risky to make any predictions; the above are mere observations on what we need today. As always, the actual work in 2.7 will depend on the itch the developers feel like scratching.
Regardless of the future, the 2.6 kernel looks great—excellent scalability, swift desktop response, improved fairness and happily cooperating VM and VFS layers.

Robert Love is a kernel hacker who works on various projects, including the preemptive kernel and the scheduler. He is a Mathematics and Computer Science student at the University of Florida and a kernel engineer at MontaVista Software. He hates fish.

