
The IP Security Protocol, Part 1
Real-world communications over the Internet are becoming more and more widespread. In particular, commercial transactions, which deserve a high level of security, often take place over our beloved--though insecure --packet network. Furthermore, VPNs (virtual private networks, i.e., private networks deployed over a public packet infrastructure) are definitely emerging as the solution of choice for the interconnection of distant offices belonging to the same company.
Unfortunately, IP packets carry our precious data in a clear form that is easily intercepted by malicious users. Doing this on a common Linux-based PC is actually quite easy, provided that one has access to the network segment over which the desired packets are traveling.
Several different solutions exist that allow us to cope with this problem, each operating at a different level of abstraction. In this article, we will discuss the differences between and purposes of application-level security, socket-level security and network-level security.
An application that needs to transmit protected data over an insecure network may adopt internal mechanisms in order to achieve data integrity and privacy. The application developer must take care of all the intricacies of authentication, encryption and key exchange. Eventually, he or she will come out with an allegedly secure mechanism allowing the application to achieve what was requested. Other developers, working on different applications, will have to do it all over again, coming out with different solutions. The probability of a security flaw hidden inside one of those applications greatly rises as their number increases. Also, most programmers are not security experts, and even if they are, they usually are not skilled mathematicians with a deep knowledge of encryption algorithms as well. Chances are high that, sooner or later, one of them will make a mistake that spoils the whole security infrastructure.
It is amazing to discover how a single bit that turns out to be not quite random enough can dismantle a thoroughly designed security system. The case of GSM (Global System for Mobile Communications, the cellular phone standard adopted in Europe) card cloning is an example of how such subtle details can become baleful. The bottom line is developers should always rely on widespread, possibly open-source solutions for their encryption needs.
Transport Layer Security (TLS) and Secure Sockets Layer (SSL) are common solutions to protect users' data from the prying eyes of malicious eavesdroppers. They basically provide applications with enhanced sockets that automatically encrypt any data flowing through them. SSL is used, for example, by web browsers when they are using the HTTPS protocol. The advantage of TLS and SSL over generic application-level security mechanisms is the application no longer has the burden of encrypting user data. Using a special socket and API, the communication is secured.
The problem with SSL is an application wishing to exploit its functionality must be written explicitly in order to do so (see Resources). Existing applications, which constitute the majority of data producers on the Internet, cannot take advantage of the encryption facilities provided by SSL without being rewritten. Think of the common applications we use everyday: mail clients, web browsers on sites without HTTPS, IRC channels, peer-to-peer file sharing systems and so on. Also, most network services (such as mail relays, DNS servers, routing protocols) currently run over plain sockets, exchanging vital information as clear text and only seldomly adopting application-level counter-measures (mostly integrity checks, such as MD5 sums).
Going one step down the OSI stack, IP Security (IPSec) guarantees the data privacy and integrity of IP packets, regardless of how the application used the sockets. This means any application, as long as it uses IP to send data, will benefit from the underlying secure IP network. Nothing has to be rewritten or modified; it even is possible that users won't be aware their data is being processed through encrypting devices.
This solution is the most transparent one for end users and the one most likely to be adopted in the future in the widest range of situations. The main drawback of IPSsec lies in its intrinsic infrastructural complexity, which demands several components to work properly. IPSec deployment must be planned and carried out by network administrators, and it is less likely to be adopted directly by end users.
IPSec has been designed to meet four different goals:
Privacy to ensure data confidentiality. In other words, it must not be possible for eavesdroppers to sniff your data over the network and read what you are sending. In one of its two working modes, IPSec also allows for traffic flow confidentiality; not only will the eavesdropper be prevented from reading your data, but he will not even know who you are communicating with.
Integrity to guarantee that data has not been tampered with. No one will be able to modify your data as it is flowing by without the legitimate receiver noticing it. An interesting property of IPSec is it provides connectionless integrity, in the sense that protection is applied to each individual IP datagram.
Authenticity to protect against identity spoofing. Attackers will no longer be able to pass themselves off as you by simply forging packets bearing your IP address or carrying data allegedly written by you. Each packet carries a type of "signature" that uniquely identifies you as the sender. This is also important for putting sophisticated access control mechanisms in place.
Robustness to prevent DoS and replay attacks. IPSec detects the arrival of duplicate IP datagrams, thus preventing attackers from recording a legitimate session and playing it back (by sending the packets again to the destination).
Depending on how IPSec is used either data integrity alone or data integrity and confidentiality are guaranteed. This allows for a modular adoption of IPSec's mechanisms. IPSec works with IPv4 as well as with IPv6, in which it is a mandatory component.
IPSec is specified by a set of IETF standard track documents, namely RFCs 2401 to 2411 and 2451, which define an architecture composed of an encryption facility (the IPSec protocol proper) and a key exchange infrastructure (named IKE, for internet key exchange). As we will see in part 2, IKE sets up the trust relationship between two peers.
The IPSec framework does not specify exactly which encryption algorithms must be used by its implementations. Instead, it provides an empty infrastructure where the desired algorithms may be set. This actually is a smart design decision, because it allows the implementations to be modular, customizable for specific problems and easily upgradable with new algorithms. A standard set of default algorithms is specified by the relevant RFCs in order to foster the early adoption of IPSec.
Depending on which devices it is deployed on, the adoption of IPSec takes the form of one of the following typical scenarios:
Host-to-host communication: IPSec is deployed on each host that requires secure communication services. Each host pair negotiates its own IPSec parameters and establishes its own connection. This is typically the case when two private users wish to share a private connection over the Internet.
Gateway-to-gateway communication: IPSec is deployed on network gateways (thus called security gateways), which can be either routers or special firewalls. Each pair of security gateways establishes a secure tunnel over which all the hosts in the LAN send protected packets. This is completely transparent to the hosts, hence it is well suited for connecting distant LANs over the Internet.
Host-to-gateway communication: IPSec is deployed both on a security gateway (as defined above) and on a host (typically, a mobile PC) that remotely connects to it. In this scenario, a remote user (e.g., a teleworker) is able to reach a private LAN (e.g., his office) without requiring a dedicated connection, such as a dial-up link. The IPSec connection between the PC and the gateway ensures that all the packets will be protected. This set up is often referred to as the "road warrior" scenario.
IPSec goals are met by two new mechanisms added to the plain IP protocol: the authentication header (AH) and the encapsulating security payload (ESP). The former guarantees data integrity, whereas the latter provides data confidentiality. Both mechanisms involve adding a new header to the IP packet. This header is placed between the normal IP header and the Layer 4 (TCP or UDP) header. In this way, an IPSec packet is not different from a plain IP packet as far as the network is concerned. Legacy routers will be able to handle IPSec packets without even knowing they are somewhat special. Only the two IPSec peers, either the communicating hosts or the tunnel endpoints, will need to deal with the additional headers. This is an important point, because it deploys only a few IPSec-compliant devices (i.e., routers) and leaves the rest of the Internet as it is.
The authentication header (AH) format is specified in RFC 2402. Usage of this IPSec feature guarantees data integrity and uniquely authenticates the sending peer. AH operation depends on algorithms called hash functions. These are basically one-way functions that, given an arbitrary-length data sequence, produce a fixed-length hash ( group of bytes) guaranteed to be different for input sequences differing even by one bit.
When the AH packet is built, a hash function is applied to the whole IP packet. The resulting value is stored inside an additional header attached to the packet itself. This new packet is then sent on the network. Upon reception of the packet, the destination host applies the same hash function to the received packet and compares the obtained value to the one stored in the AH header. If the two values differ, it means the packet integrity is compromised, and the packet is rejected.
Actually, some fields of the original IP header are not considered while computing the hash, because their value is subject to change along the path. Examples of such fields are the time to live (TTL) and the IP checksum.
Some readers may wonder what would prevent an attacker from modifying both packet bytes and the hash value in order to make the latter coherent with the former. Hash functions used for AH are called keyed hashes. In the computation of the basic hash, they also consider a secret key (which has been negotiated between the IPSec peers, as we will see in a while), thus making it impossible for someone who does not know the key to recalculate the new hash.
This is also the reason why AH can authenticate the sending host. Since the secret key is needed to calculate the hash, verifying the latter's correctness simultaneously proves that the packet is untouched and that the sender knew the secret key. Thus, he is the legitimate sender.
The keyed hash algorithm mandated by RFC 2402 is HMAC, which must be used in conjunction with either MD5 or SHA. For more details on these obscure acronyms, see the sidebar. The two working modes are commonly referred to by HMAC-MD5-96 or HMAC-SHA-1-96, respectively. Other hash algorithms may be added in the future without changing the overall AH architecture; only the hash computation modules would need to be modified.
An optional feature of AH is protection against replay attacks. This is possible thanks to a monotonically increasing counter that also is included in the AH header. Generation of the counter is mandatory for the sending peer, whereas its verification by the receiving peer is optional.
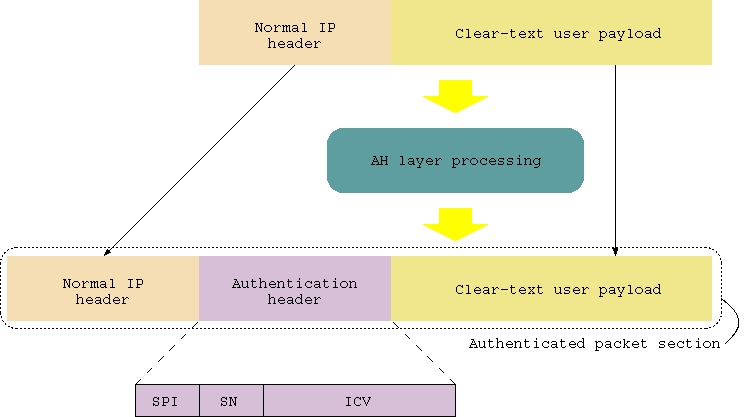
Structure of an IPSec AH Packet
The most important fields contained in the AH header are:
a 32-bit integer called SPI (security parameter index) that is used to associate the packet with a specific security relationship between the communicating peers (more on this in Part 2);
a 32-bit sequence number that is used to protect against replay attacks. The number must be monotonically increasing and can wrap only when a new connection procedure is established; and
the authentication data proper (ICV, integrity check value), computed by the sending peer as described above.
What AH does not provide is data confidentiality. An AH packet carries some information related to its integrity, but the original packet payload is still in clear text. An eavesdropper, therefore, will be able to read packet content and grab any sensitive information that may be present. Anyway, he will not be able to modify the packet and substitute it for the real one. Neither will he be allowed to forge fake data and send it to the receiver by pretending to be the legitimate sender. If data confidentiality is required, IPSec's ESP format must be used.
In Part 2 of this article, we will discuss encapsulating security payloads, IPSec modes, security associations and key exchange mechanisms.
Applied Cryptography, by Bruce Schneier, is an excellent and deep introduction to cryptography issues and algorithms.
Cryptonomicom, by Neal Stephenson, is a good novel romance deeply related to cryptography.
IETF RFCs 2401-2411, RFC 2451, and others (available from www.ietf.org), specify the IPSec architecture and its components.
"OpenSSL Programming", Linux Journal, September 2001. Eric Rescorla gives an introduction on how to use SSL in your own programs.
"Problem Areas for the IP Security Protocols", Proc. 6th Usenix Unix Security Symposium, July 1996. Steve Bellovin explains, among other things, why using confidentiality without authentication is dangerous.
"The 101 Uses of OpenSSH: Part II", Linux Journal, February 2001. Mick Bauer introduces the basic concepts of public key cryptography.
Gianluca Insolvibile has been a Linux enthusiast since kernel 0.99pl4. He currently deals with networking and digital video research and development.
email: g.insolvibile@cpr.it
