
Securing Applications on Linux with PAM
The basic concepts of PAM (Pluggable Authentication Module), developing a PAM-enabled application and writing the PAM configuration file.
by Savio Fernandes and KLM Reddy
Authentication is a mechanism that verifies whether an entity is who it claims to be. On a Linux system, applications, such as su, passwd or login, are used to authenticate users before they are given access to the system's resources.
On almost all Linux distributions, user information is stored in /etc/passwd. This is a text file that contains the user's login, the encrypted password, a unique numerical user ID (called the uid), a numerical group ID (called the gid), an optional comment field (usually containing such items as the user's real name, phone number, etc.), the home directory and the preferred shell. A typical entry in /etc/passwd looks something like this:
aztec:K52xi345vMO:900:900:Aztec software,Bangalore:/home/aztec:/bin/bash
In reality, though, if you look at your /etc/passwd, it's likely that you actually see something like this:
aztec:x:900:900:Aztec software,Bangalore:/home/aztec:/bin/bashWhere did the encrypted password go?
The /etc/passwd file is readable by all users, making it possible for any user to get the encrypted passwords of everyone on the system. Though the passwords are encrypted, password-cracking programs are widely available. To combat this growing security threat, shadow passwords were developed.
When a system has shadow passwords enabled, the password field in /etc/passwd is replaced by an “x”, and the user's real encrypted password is stored in /etc/shadow. Because /etc/shadow is only readable by the root user, malicious users cannot crack their fellow users' passwords. Each entry in /etc/shadow contains the user's login, their encrypted password and a number of fields relating to password expiration. A typical entry looks like this:
aztec:/3GJajkg1o4125:11009:0:99999:7:::
In the initial days of Linux, when an application needed to authenticate a user, it simply would read the necessary information from /etc/passwd and /etc/shadow. If it needed to change the user's password, it simply would edit /etc/passwd and /etc/shadow.
This method, though simple, is a bit clumsy and presents numerous problems for system administrators and application developers. Each application requiring user authentication has to know how to get the proper information when dealing with a number of different authentication schemes. Thus the development of the privilege-granting application software is linked tightly to the authentication scheme. Also, as new authentication schemes emerge, the old ones become obsolete. In other words, if a system administrator wants to change the authentication scheme, the entire application must be recompiled.
To overcome these shortcomings, we need to come up with a flexible architecture that separates the development of privilege-granting software from the development of secure and appropriate authentication schemes. The Linux Pluggable Authentication Module (PAM) is such an architecture, and it successfully eliminates the tight coupling between the authentication scheme and the application.
From the perspective of the application programmer, PAM takes care of this authentication task and verifies the identity of the user. From the perspective of the system administrator, there is the freedom to stipulate which authentication scheme is used for any PAM-aware application on a Linux system.
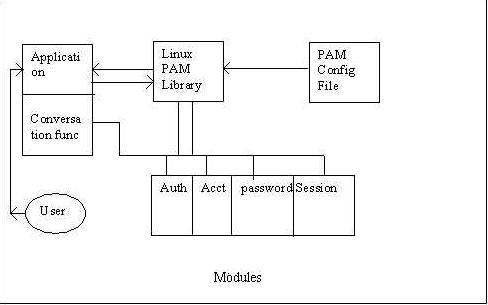
Figure 1. The PAM Ecosystem
Figure 1 shows the four major components of the PAM Ecosystem. The first component is the PAM Library, which provides the necessary interface and functions required for developing PAM-aware applications and modules.
Second is the PAM-Enabled Application, an application that provides some service. It also may need to authenticate the user before granting service. To perform the authentication step, the application interfaces with the Linux-PAM library and invokes whatever authentication services it requires. The application knows none of the specifics of the configured authentication method. The application is required to provide a “conversation” function, which allows the loaded authentication module to communicate directly with the application and vice versa.
The Pluggable Authentication Module is the third component and is a binary that provides support for some (arbitrary) authentication method. When loaded, modules can communicate directly with the application, through the application-provided “conversation” function. Textual information, required from (or offered to) the user, can be exchanged through the use of the application-supplied “conversation” function.
The final component is the PAM Configuration File. It is a text file where the system administrator can specify which authentication scheme is used for a particular application. On the Linux system, this configuration information can be stored either in a file under the /etc/pam.d folder or as a line in the /etc/conf configuration file. The PAM configuration file is read when the application initializes the PAM library. The PAM library then loads the corresponding authentication modules configured to support the authentication scheme specified for a particular module.
To PAM-enable an application, we need to invoke the appropriate authentication routines in the PAM library. We also need to provide a “conversation function” that the module can use to communicate directly with the application.
The authentication routines of the PAM API consist of the following three primary functions:
pam_start(): the first of the PAM functions that must be called by an application. It initializes the PAM library, reads the PAM configuration file and loads the desired authentication modules in the order in which they are mentioned in the configuration file. It returns a handle to the PAM library that the application can make use of for all further interactions with the library.
pam_end(): the last function an application should call in the PAM library. Upon its return, the handle to the PAM library is no longer valid, and all memory associated with it will be invalidated.
pam_authenticate(): this function serves as an interface to the authentication mechanisms of the loaded modules. It is called by the application when it needs to authenticate a user who is requesting service.
In addition to the authentication routines, the PAM API also provides the following functions, which the application can invoke:
pam_acct_mgmt(): checks whether the current user's account is valid.
pam_open_session(): begins a new session.
pam_close_session(): closes the current session.
pam_setcred(): manages user credentials.
pam_chauthtok(): changes the user's authentication token.
pam_set_item(): writes state information for the PAM session.
pam_get_item(): retrieves state information for PAM session.
pam_strerror(): returns an error string.
These PAM API routines are made available to the application by the security/pam_appl.h interface.
The conversation function facilitates direct communication between a loaded module and the application. It typically provides a means for the module to prompt the user for a user name, password and so on. The signature of the conversation function, conv_func, is as follows:
int conv_func (int,const struct pam_message **,
struct pam_response **,void *);
The loaded authentication module prompts the application for some input via the pam_message structure. The application sends the requested information to the module through the pam_response structure.
But, how does the module get a pointer to the conversation function? The answer is the conversation structure: struct pam_conv. The conversation structure needs to be initialized by the application with the pointer to the conversation function. After initialization, the conversation structure is passed as an argument to the PAM library during the call to pam_start(). Using this pointer, the module can then begin communication with the conversation function.
Now, let's develop an application that returns the current time. This application is one that is required to authenticate the user before providing service.
First, include the necessary headers. The header file security/pam_appl.h is the interface to the PAM API. Then, initialize the conversation structure:
static struct pam_conv conv = {
my_conv, //function pointer to the
//conversation function
NULL
};
Then write the main() method. To do this, first load the PAM library. We know that an application needs to call the methods in the PAM library in order to delegate the required authentication tasks. But how does the application get a handle to the PAM library, libpam? A call to pam_start() initializes the libpam with the service_name of the application requiring the authentication service, the user name of the individual to be authenticated and a pointer to the pam_conv structure. This function returns a handle to the libpam, *pamh, that provides continuity for successive calls to the PAM library:
pam_handle_t *pamh = NULL;
int retval = 0;
retval = pam_start("check_user",NULL,&conv,&pamh);
if(retval != PAM_SUCCESS)
exit(0);
If we do not want to pass the user name to pam_start(), we can pass
NULL. The loaded authentication module then will prompt the user
for it at a later point in time with the conversation function.
The second step in writing the main() method is to authenticate the user. Now comes the moment of truth where we decide whether the user is who he claims to be. How do we discover this? The function pam_authenticate() serves as an interface to the authentication mechanisms of the loaded modules. It verifies the user name and password supplied by the user by interacting with the appropriate authentication module. It returns PAM_SUCCESS on success, and if there is no match, some error value indicating the nature of failure is returned:
retval = pam_authenticate(pamh,0);
if(retval == PAM_SUCCESS)
printf("%s\n","Authenticated.");
else
printf("%s\n","Authentication Failed.");
You may notice we pass the handle pamh, which we have obtained from the earlier call to pam_start().
The third step in this process is providing access to the desired service. Now that the user is authenticated, he will be provided with access to the requested service. As an example, our service displays the current time:
return current_time();
Finally, unload the PAM library. After the user has finished using the application, the PAM library needs to be unloaded. Also, the memory associated with the handle pamh needs to be invalidated. We achieve this with a call to pam_end():
int pam_ status = 0; if(pam_end(pamh,pam_status) !=
PAM_SUCCESS) { pamh = NULL;
exit(1);
}
The value is taken by the second argument to pam_end(). pam_status
is used as an argument to the module-specific callback function,
cleanup(). In this way, the module can perform any last-minute
tasks that are appropriate to the module before it is unlinked. On
successful return of the function, all memory associated with the
handle pamh is released.
The implementation of a basic conversation function is shown in Listing 1.
Listing 1. A Basic Conversion Function
The arguments of a call to the conversation function concern the information exchanged by the module and the application. That is, num_msg holds the length of the array of the pointer, msg. After a successful return, the pointer *resp points to an array of pam_response structures, holding the application-supplied text.
The message-passing structure (from the module to the application) is defined by security/pam_appl.h as:
struct pam_message {
int msg_style;
const char *msg;
};
The point of having an array of messages is that it becomes possible to pass a number of things to the application in a single call from the module. Valid choices for msg_style are:
PAM_PROMPT_ECHO_OFF: obtains a string without echoing any text (e.g., password).
PAM_PROMPT_ECHO_ON: obtains a string while echoing text (e.g., user name).
PAM_ERROR_MSG: displays an error.
PAM_TEXT_INFO: displays some text.
The response-passing structure (from the application to the module) is defined by including security/pam_appl.h as:
struct pam_response {
char *resp; int resp_retcode;
};
Currently, there are no definitions for resp_retcode values; the normal value is 0.
Compile the application using the following command:
gcc -o azapp azapp.c -lpam -L/usr/azlibs
The folder /usr/azlibs should be the one that typically contains the Linux-PAM library modules, which are libpam.so. This library file contains the definitions for the functions that were declared in pam_appl.h.
When faced with the task of developing a module, we first need to be clear about the type of module we want to implement.
Modules may be grouped into four independent management types: authentication, account, session and password. To be properly defined, a module must define all functions within at least one of those four management groups.
Use the function pam_sm_authenticate() to implement an authentication module, which does the actual authentication. Then use pam_sm_setcred(). Generally, an authentication module may have access to more information about a user than their authentication token. This second function is used to make such information available to the application. It should only be called after the user has been authenticated but before a session has been established.
For account management model implementation, pam_sm_acct_mgmt() is the function that performs the task of establishing whether the user is permitted to gain access at this time. The user needs to be previously validated by an authentication module before this step.
The session management module commences a session with a call to pam_sm_open_session().
When a session needs to be terminated, the pam_sm_close_session() function is called. It should be possible for sessions to be opened by one application and closed by another. This either requires that the module uses only information obtained from pam_get_item() or that information regarding the session is stored in some way by the operating system (in a file for example).
Finally, pam_sm_chauthtok() implements the password management module and is the function used to (re-)set the authentication token of the user (change the user password). The Linux-PAM library calls this function twice in succession. The authentication token is changed only in the second call, after it verifies that it matches the one previously entered.
In addition to these module functions, the PAM API also provides the following functions, which the module can invoke:
pam_set_item(): writes state information for the PAM session.
pam_get_item(): retrieves state information for the PAM session.
pam_strerror(): returns an error string.
The PAM API functions needed for module development are made available to the module via the security/pam_modules.h interface.
Now, let's develop a module that performs authentication management. For this we need to implement the functions in the authentication management group. Start by including the necessary headers. The header file security/pam_modules.h is the interface to the Linux-PAM library.
Next, authenticate the user; Listing 2 shows a basic implementation of the pam_sm_authenticate(). The purpose of this function is to prompt the application for a user name and password and then authenticate the user against the password encryption scheme.
Listin2. A Basic Implementation of pam_sm_authenticate()
Obtaining the user name is achieved via a call to pam_get_user(), if the application hasn't already supplied the password during a call to start_pam().
Once we get the user name, we need to prompt the user for his authentication token (in this case the password) by calling _read_password(). This method reads the user's password by interacting with the application-provided conversation function.
In _read_password() we first set the appropriate data in the pam_message struct array to be able to interact with the conversation function:
struct pam_message msg[3], *pmsg[3]; struct pam_response *resp; int i, replies; /* prepare to converse by setting appropriate */ /* data in the pam_message struct array */ pmsg[i] = &msg[i]; msg[i].msg_style = PAM_PROMPT_ECHO_OFF; msg[i++].msg = prompt1; replies = 1;
Now call the conversation function expecting i responses from the conversation function:
retval = converse(pamh, ctrl, i, pmsg, &resp);The converse() function basically is a front end for the module to the application-supplied conversation function.
Finally, a call to _verify_password(). The _verify_password() method essentially verifies the user's credentials according to the appropriate cryptographic scheme.
Generally, an authentication module may have access to more information about a user than what is contained in their authentication token. The pam_sm_setcred function is used to make such information available to the application. A basic implementation of the pam_sm_setcred is shown in Listing 3. In this sample implementation of this function, we simply make available to the application the return code of the call to pam_sm_authenticate().
The converse() function acts as a front end for module-application conversations. A sample implementation of converse() is shown in Listing 4.
Listing 4. A Sample Implementation of converse()
The pointer to the conversation function is obtained using pam_get_item(pamh,PAM_CONV,&item). Using the pointer, the module now can start communicating directly with the application.
Modules may be statically linked to libpam. In fact, this should be true of all the modules distributed with the basic PAM distribution. To be statically linked, a module needs to export information about the functions it contains in a manner that does not clash with other modules.
The extra code necessary to build a static module should be delimited with #ifdef PAM_STATIC and #endif. The static code should define a single structure, struct pam_module. This is called _pam_modname_modstruct, where modname is the name of the module used in the filesystem, minus the leading directory name (generally /usr/lib/security/) and the suffix (generally .so).
#ifdef PAM_STATIC
struct pam_module _pam_unix_auth_modstruct = {
"pam_unix_auth",
pam_sm_authenticate,
pam_sm_setcred,
NULL,
NULL,
NULL,
NULL,
};
#endif
Now our module is ready to be compiled as static or dynamic. Compile the module using the following command:
gcc -fPIC -c pam_module-name.c ld -x --shared -o pam_module-name.so pam_module-name.o
The local configuration of those aspects of system security controlled by Linux-PAM is contained in one of two places, either the single system file (/etc/pam.conf) or the /etc/pam.d/ directory.
A general configuration line of the /etc/pam.conf file has the form: service-name module-type control-flag module-path arguments.
We can also specify the PAM configuration for an application in a separate file in the /etc/pam.d folder, in which case the configuration file has the form: module-type control-flag module-path arguments. The service-name becomes the name of the configuration file. Frequently the service-name is the conventional name of the given application, for example, azServer.
Four module types exist: auth, account, session and password.
auth: determines whether the user is who he claims to be, usually done with a password, but may be determined by a more sophisticated means, such as biometrics.
account: determines whether the user is allowed to access the service, whether his passwords have expired and so on.
password: provides a mechanism for the user to change his authentication token. Again, this is usually his password.
session: things that should be done before and/or after the user is authenticated. This might include things such as mounting/unmounting the user home directory, logging the login/logout and restricting/unrestricting the services available to the user.
In addition, there are four control flags: required, requisite, sufficient and optional.
Required: indicates that the success of the module is required for the module-type facility to succeed. Failure of this module will not be apparent to the user until all of the remaining modules (of the same module type) have been executed.
Requisite: same as required, except that in the case of a module failure, it directly returns the result to the application.
Sufficient: if this module has succeeded and all previous required modules have succeeded, then no more subsequent required modules are invoked.
Optional: marks the module as not critical to the success or failure of the user's application for service. Its value is taken into consideration only in the absence of any definite successes or failures of previous or subsequent stacked modules.
The pathname of the dynamically loadable object file (the pluggable module itself) is the module path. If the first character of the module path is /, it is assumed to be a complete path. If this is not the case, the given module path is appended to the default module path, /usr/lib/security.
The arguments are a list of tokens passed to the module when it is invoked, much like arguments to a typical Linux shell command. Generally, valid arguments are optional and specific to any given module.
Finally, to write the configuration file, edit the /etc/pam.conf file to add the following line of code:
check_user auth required /lib/security/pam_unix.so
This indicates that for the service-names, check_user and auth module-type are required. The module to be loaded to support this authentication method is pam_unix.so, which is found in the directory /lib/security/.



