
Why Application Servers Crash and How to Avoid It
Too often, the success of a web site brings its doom. After a good publicity blitz, or a healthy growth of its popularity, the number of users visiting a site becomes very large. Then, at certain point, these users witness painfully slow response time, then one crash, then another, etc. The site administrators add some RAM, more machines, faster processors, and the crashes keep coming. At some point, rumors spread, and the users stop visiting.
Interesting web sites all use dynamic content: an application server drives the show and is helped by an RDBMS (relational database management system) to store the data. Web servers don't use a lot of static HTML pages anymore, which is too bad because when they did, they did not crash so much. Why? And, why does the application server crash? We will look at a little bit of queuing theory to analyze various scenarios that lead to web site crashes.
Queuing theory is about using math (statistics) to model the behavior of a server system. The server is not necessarily a computer. Queuing theory can be used to model the waiting queue at a bank teller or the flow of cars at the entrance of a bridge. It is also a good tool to predict the performance of telecom and computing systems.
To simplify things, we will use the single-server queue model with exponential service times. The words single server basically mean that the systems we will model have only one database server (the number of processors in the machine is not relevant here). Also, the phrase exponential service times means that the response time is random but follows a known mean average with a standard deviation equal to that average. We have to use even more queuing theory buzzwords now and say that we will use the M/M/1 model. We have already said that here we have a single-server (the 1 in M/M/1) and that we assume exponential service times (the second M). The first M indicates that we expect random arrivals following a Poisson distribution. With that all said, we can then use a few neat and simple formulas. First, we need to name a few variables:
[Ed. note: so that everyone may see them, the Greek letters below are presented in text form.]
<lambda> = average number of requests per second
s = average service time for each request
<rho> = utilization: fraction of time that the server is busy
q = average number of requests in the server (waiting and being processed)
tq = average time a request spends in the server (response time as perceived by the user)
w = average number of requests waiting in the server
The first formula is:
<rho> = <lambda> * s
With this formula, we can find the maximum number of requests that the server could process per second:
<lambda>max = 1/s
We will see that peculiar things happen when the number of requests per second gets close to this maximum, <lambda>max.
A few more formulas:
q = <rho> / (1 - <rho>)
tq = s/(1 - <rho>)
w = <rho> 2 / (1 - <rho>)
If we use these formulas, we can see why a web site can become very slow. Let's use queuing theory to model a system with two tiers on the server: the web server and the database server. Also, let's ignore the overhead of the HTTP server as the database server is orders of magnitude slower. Let's say that the average service time of the system is equal to that of the database server.
In Figure 1, we suppose that the database server has an average service time for each request of 50ms (s = 0.05 second). We vary the number of requests per second <lambda> and put it on the X axis. The Y axis has the perceived response time (tq).
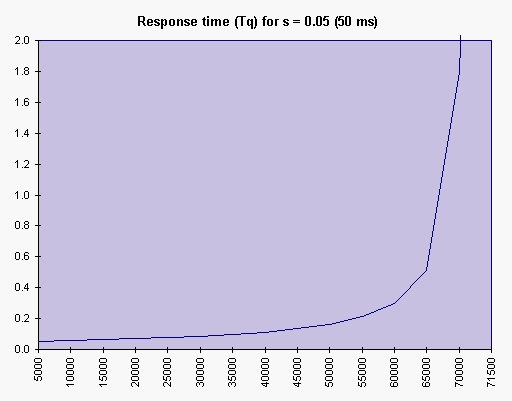
Figure 1. Response Time tq for s = 0.05 (50ms)
We see in Figure 1 that the curve is almost flat and then rises suddenly. This happens when the utilization <rho> approaches 1. But, there is more to it than just slow response time when a server becomes more and more busy. RAM becomes a problem as soon there is an important peak in the number of requests.
For the sake of simplicity within queuing theory, we usually assume that the waiting queue has an infinite size. In practice, that is where ugly things can happen: queues do not have an infinite size because memory is not infinite. Whether you have 1GB or 8GB of RAM, you eventually run out of it.
The next graph (Figure 2) is similar to the first one, but on the Y axis we put the number of requests still in the server (q).
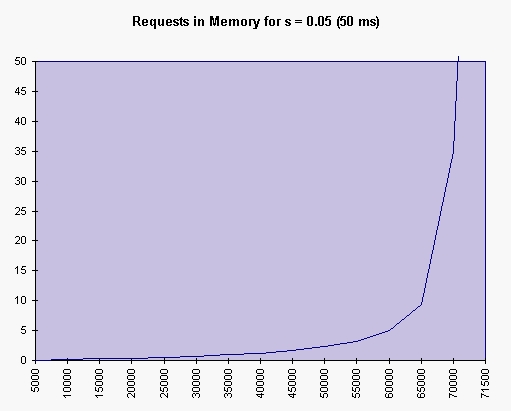
Figure 2. Requests in Memory for s = 0.05 (50ms)
What happens is that when the number of requests coming in reaches the point where the utilization <rho> is almost 1, the number of requests waiting in RAM grows toward infinity. If you have 1,000 requests in RAM and each takes only 100KB (that is roughly 100MB), you are probably okay. With s = 0.05 second (50ms), q = 1000 when you have 71,928 requests per hour. When you have 71,993 requests per hour, you will have 10,284 requests waiting in RAM. That's about 1GB RAM. Let's say you have 2GB--with six more requests per hour, 71,998, you get q = 35,999. That's about 3.5GB. Theoretically, your users would have received a response after 30 minutes (1,800 seconds). But very few will get any response because the machine is swapping to get some virtual memory. Since this increases the service time by a factor of 100 or 1,000, your server appears to the world to have died.
There is a human factor that makes such response time crises even worse. The users will not wait patiently for 30 seconds. They will click Stop or press Esc and resubmit their requests. This will only add more requests to the system.
Table 1 shows the increase of q and tq for a server with a 50ms service time under increasing loads.
Table 1. Increase of q and tq for a Server with a 50ms Service Time
But, what would have happened if the server had used 1MB or 2MB per concurrent request? Table 2 shows also the usage of RAM if the per request footprint is 100KB, 500KB, 1MB or 2MB. If all requests really had a service near the average of 50ms (if the distribution was truly exponential), nothing much would happen. The server would start swapping a few seconds earlier perhaps. That makes little difference. The curve only becomes steep near the saturation point when the utilization <rho> approaches 1. But, there are scenarios (see the section Why the Server Crashes, Even at Moderate Loads) where reality does not follow the theoretical model. In those cases, RAM usage does make a difference.
Table 2. RAM Usage with Various Typical Request Footprint (with s = 50ms)
These days, a well-tuned relational database (without deadlocks, no I/O contention, separate I/O paths for data and transaction log, etc.) might have a mean service time of 2, 5 or 10ms. That is in the same order of magnitude as the specs of the best disk drives themselves. And, that is also the level of performance announced in press releases from manufacturers on new TPC performance records: 30,000, 12,000 and 6,000 TPM (transactions per minute), respectively.
Table 3 shows what can be the highest volume of requests per hour while preserving a tolerable, yet slow response time (tq <= 20 seconds) for some typical mean service times.
You can see in this table that speed is a very valuable feature. With a very small mean service time (5ms or less), a web application system can support an important load without reaching the limit (<rho> = 1). Not only this, but the almost flat part of the curve in graphs, such as in Figures 1 and 2, is much longer. Also, Table 3 shows that a much longer mean service time (200, 500ms or more) allows a very limited number of requests per hour.
If the database back end easily can be as fast as 5 or 10ms, and therefore process roughly half a million transactions per hour, then why does a web application system die when it has not even one hundred thousand (or less)? In other words, if the database takes 5ms, why does the application server take 50 or 100ms (or more) to complete a request?
Once again, we are reminded of the keep it simple principle. As we will see, its antithesis, complexity, is a monster for which we will pay dearly.
How many tiers does the server side have? With a two-tier architecture, there is only a web server and a database server. With three-tier architecture, we have the two previous tiers and a third one, the application server, in between. Some installations have another tier: they split the work in two phases between two application servers in cascade, perhaps because it fits the Model-Controller-View principle of development methodology. Some other installations have yet another tier, a security server, which must answer access-control requests coming from the various servers in the system.
In all of these architectures, each additional server adds its own service time to the total mean service time of the simple model we have been looking at. Also, there is a communication delay between each server, whether a server is only another program on the same machine or another process on another host. Some of the modern communication protocols used to communicate between object-oriented languages are known to introduce significant overhead. In my experience, the smallest delay I have seen using a rather lightweight TCP protocol on the same machine was around 3ms. If you have many hops because you have three or four servers in cascade to serve one request, the sum of all these delays could easily be 20 or 30ms. And you pay that price (30ms) for each and every request, even if your last application server does a 5ms query to the database that takes only 5ms.
Then there is the question, how fast are the various application servers? Each vendor might have their claims. If you want the real answers, you have to let your application compute the elapsed time at the end of each request and write it to a message log. This will tell you what really happens with your hardware and software configuration. If you have such measurements for each server program, you will be able to identify bottlenecks quickly. The lightest application server I have seen used a few milliseconds to process any request. Your mileage will vary. It would be interesting to compile real-life statistics like this about various products as these numbers are as difficult to find as marble-sized gold nuggets in a stream.
Let's say we started with a high-performance RDBMS crunching at 5ms, and we end up with a web service that has a total average service time of 50ms. Well, that's not so bad actually, as we should be able to process 70,000 dynamic requests per hour.
And, let's say that the main application server of MyBestSport.com crashes at less than 10,000 requests per hour. Why? We know it happens often on evenings when there is a baseball or football game on TV, 15 minutes before the game (the load gets much lighter once the game begins).
This is very likely to happen if certain categories of requests take more time and tend to occur together, without being well distributed in time. This is not like the exponential distribution that we used in our model. Certain types of unequal distributions are especially painful. Let's look at this example (not a real service) in more detail.
Suppose the server side has four tiers: HTTP server, application server, security server and database server. Also, suppose the total mean service time is 50ms: 10ms to leave the HTTP server, cross a firewall and get to the application server; 25ms in the application server itself; 10ms to do an access-control request to the security server; and 5ms to do an SQL request.
But, all these measures are averages. We know from the log files that one server has a less equal distribution: the security server does the access control checks very quickly, in less than 4ms usually, but it takes normally about 500ms to perform a login check. The average is still less than 5ms because there are hundreds of access-control requests for each login request. When we look in the application log, we see that a large number of new logins were beginning before the application server ran out of RAM and started swapping, tied its shoelaces together and jumped out of the window.
Also, we know that the programming power offered by the very high-level, object-oriented features of the application server has its price: each incoming request uses at least 800KB even before it has been forwarded to the security server or the database server. Also, each session object (used to simulate a browser-to-app-server persistent connection, something that the HTTP protocol does not provide, per se) takes 200KB. After more analysis of the log, we find out that just before the crash there was an average of 200 logins per minute, much more than the average. Looking at the 15 minutes of log before the crash, we find about one thousand login requests and only a few logouts. The application server got bogged down with too many concurrent login requests, and it exhausted the RAM. The machine started paging out virtual memory, requests took too long, users got fed up with waiting and clicked on Stop, pressed Esc and tried logging in again until the operator pressed the big red button.
To fix this problem, two possible solutions seem interesting at first glance: add more RAM in the application server machine or increase the speed of the login check in the security server. Adding RAM is only a false solution as, even if it fixes the problem temporarily, it will be used up entirely again later because the site has a growing popularity. The security server is not a solution (in this example) because it is in a black box that comes with the explicit condition that it not be messed with. Neither of those two solutions is a good one.
A technically effective solution would be to rewrite the application in a lower-level language, one that is much less memory-hungry. The memory footprint of each concurrent request or session could be reduced from 1MB to something like 100KB (using C or C++). But, this would take too much development time and thus is not a practical avenue.
There is a way to keep the same object-oriented technology if the application server product offers enough flexibility. The developers can add a pool of request processor resources (RPRs) in the application server application. An RPR is an abstract resource, a proxy resource like a ticket that allows the use of a memory-hungry data object or series of objects. An RPR does nothing by itself. What is useful is that the application server manages a pool of RPRs and has a FIFO queue through which all incoming requests must go before acquiring an RPR and the huge memory resource for which it stands. If all RPRs in the pool are in use, the request should wait in the queue, which follows a FIFO discipline (first in, first out). With this technique, the memory usage can be predicted and controlled.
This technique does not accelerate the security server nor the application server. What it does is prevent the application server from pushing the whole machine into an out-of-memory scenario. Basically, this approach simplifies the problem of response time: we are now back at a simpler situation (with a normal distribution of service time), and eventually, the users will get responses and the machine will not die (assuming that the HTTP server has plenty of RAM for many concurrent requests and that HTTP servers are much less memory-hungry, it should be okay).
The following list summarizes the suggestions explained previously:
Get a good database server and fine-tune the queries and the database at the physical level (your DBA person might be more important than the database product itself).
Make sure that the application server product you select provides fast and stable throughput.
Remember that if something is slower downstream, the server at the front end will accumulate a very large number of requests in memory (fast downstream processing is an asset).
If your application server uses a memory-hungry, object-oriented language, add a pool of Request Processor Resources in your application to control the use of resources right away when the requests enter the server.
Keep it simple. If you have a cascade of application servers before a request is finally processed by the database server, your application will never be fast (no matter how fast the machines are: a hop is a hop and an I/O remains an I/O).
Measure everything. Time stamp each phase of the processing of a request and write that to a log. You will be able to compute interesting stats on normal days, and on bad days you will be able to find where things went wrong and correct the situation after a much shorter analysis.
If a web page or a graphic element can be stored statically, without being impractical, do it.
Do not make a request to the security server for each static web page or element (find another way to guarantee the required level of security in the HTTP server environment).
Evaluate security server products yourself, and reject all products that are too slow for the performances you expect to need in the next five years.
Plan for success now: expect extremely large loads.
Consider that a simple and fast architecture can be less expensive and more robust than a fancy distributed computing solution relying on a leading-edge software/hardware solution. Test the products first, believe the hype later.
Data and Computer Communication, 6th Edition by William Stallings. Prentice Hall, 1999.
"A Practical Guide to Queuing Analysis" by William Stallings. BYTE, February 1991, pp. 309-316.
John T. Francois has been developing transactional systems since 1981 and gateways and servers using various protocols since 1985. He has been working with C and UNIX since 1987.
email: johntfrancois@yahoo.ca

