
Apache 2.0: The Internals of the New, Improved
The Apache Project is a collaborative software development effort aimed at creating a robust, commercial-grade and freely available source code implementation of an HTTP web server. The project is jointly managed by a group of volunteers located around the world, using the Internet and the Web to communicate, plan and develop the server and its related documentation. These volunteers are known as the Apache Group. In addition, hundreds of users have contributed ideas, code and documentation to the project.
According to the Netcraft web servers survey, Apache has been the most popular web server on the Internet since April 1996. This comes as no surprise due to its many characteristics, such as the ability to run on various platforms, its reliability, robustness, configurability and the fact that it is free and well-documented. Apache has many advantages over other web servers, such as providing full source code and an unrestrictive license. It is also full of features. For example, it is compliant with HTTP/1.1 and extensible with third-party modules, and it provides its own APIs to allow module writing. Other interesting features that have made it a popular web server include the capability to tailor specific responses to different errors, its support for virtual hosts, URL rewriting and aliasing, content negotiation and its support for configurable, reliable piped logs that allows users to generate logs in a format they want.
Apache 1.3 has been a well-performing web server, but it suffers a few drawbacks, such as its scalability on some platforms. For instance, according to Martin Pool, AIX processes are heavyweight, and a small AIX machine serving a few hundred concurrent connections can become heavily loaded. In such situations, using processes is not the most effective solution and a threaded web server is needed.
Furthermore, with the evolution of the requirements imposed on web servers, new functionalities like higher reliability, higher security and further performance are required. In response, web servers must evolve to satisfy these demands. Apache is no exception, and it continues its drive to become a more robust and a faster web server with its new 2.0 version (see sidebar).
Apache is renowned for its portability because it works on several platforms. However, having the same base code of Apache portable on so many platforms comes with a high price, which is the ease of maintenance. The Apache server has reached a point where porting it to additional platforms is becoming more complex. Therefore, in order to give Apache the flexibility it needs to survive in the future on more platforms, this problem had to be addressed and resolved. As a result, Apache will be able to use specialized APIs, where they are available, to provide improved performance, making it easy to port to new platforms.
Apache was intended initially to work on standard UNIX systems. However, its support for other platforms grew and the number of platforms supported affected the simplicity of the source code. One effect is that the code makes extensive use of conditional compilation to cope with platform peculiarities. Writing to a standard POSIX API is also undesirable on some platforms that provide substandard implementations or faster paths.
To solve these problems, Ryan Bloom is leading efforts to develop a solution, a layer called the Apache Portable Runtime (APR). The APR presents a standard programming interface for server applications and covers tasks such as file I/O, logging, mutual exclusion, shared memory and managing child processes and asynchronous I/O. APR shields the application from incompatibilities in the implementation of the standard, and thus it will use the most efficient way to achieve each function on each supported particular platform.
Another component that helps to resolve portability problems is Ralph Engelschall's MM library, which hides the details of setting up shared memory areas between processes and provides an interface similar to malloc to manipulate them.
The MM library is a two-layer abstraction library that simplifies the usage of shared memory between forked processes under UNIX platforms. On the first (lower) layer, it hides all platform-dependent implementation details (allocation and locking). When dealing with shared memory segments and on the second (higher) layer, it provides a high-level malloc(3)-style API for a convenient and well-known way to work with data-structures inside those shared memory segments.
The traditional Apache structure is based on a single parent process and a group of reusable children (see Figure 1). The parent reads the configuration and manages the pool of children. Each child at any time is either serving a single request or sleeping. Apache 1.x automatically regulates the size of the pool of children so that there are enough to cope with spikes in load without using too many resources to maintain idle processes. Busy children serve one request at a time on a single socket.
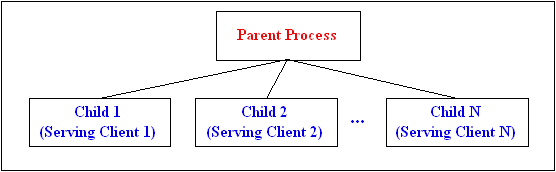
Figure 1. Traditional Apache Structure
Some web sites are heavily loaded and receive thousands of requests per minute or even per second. Traditionally TCP/IP servers fork a new child to handle incoming requests from clients. However, in the situation of a busy web site, the overhead of forking a huge number of children will simply suffocate the server. As a consequence, Apache uses a different technique. It forks a fixed number of children right from the beginning. The children service incoming requests independently, using different address spaces. Apache can dynamically control the number of children it forks based on current load.
This design has worked well and proved to be both reliable and efficient; one of its best features is that the server can survive the death of children and is also reliable. It is also more efficient than the canonical UNIX model of forking a new child for every request.
This traditional Apache design works well up to quite high loads on modern UNIX systems. On Linux in particular, context switches and forking new processes are cheap, and accordingly this simple design is nearly optimal. One drawback, however, of the isolation between processes is that they cannot easily share data, and consequently sharing session data across the server takes a little work.
Another approach is to serve each request in a separate thread: this is the model used by most NT-based web servers. Although this approach eliminates most of the protection between tasks, it allows the module programmer more flexibility and it can be faster on systems where threads are cheaper than processes, such as Windows NT and AIX.
Apache 2.0 introduces MPMs (multiple-processing modules) that hide the process model from most of the code. At runtime, Apache can be configured to use threads, processes, a hybrid of both or some other model. Modules can register new process models to suit their operating systems or the applications. One proposed example is to fork processes that run as different users to give increased security on machines that offer virtual hosts to multiple customers.
Apache's developers have always emphasized the security, correctness and flexibility of the server. However, as of Apache 1.3, many efforts were directed towards bringing performance up to par with other high-end web servers were minimal. With the continuous explosive growth of web traffic, Apache 2.0 tries to improve its throughput without compromising its other qualities.
Web servers have several key performance determinants. Some of these factors include the amount of memory available to hold the document tree, disk bandwidth, network bandwidth and CPU cycles. In most cases, people add to or upgrade the hardware to improve the performance of their web servers. Nevertheless, with the explosive growth of the Internet and its increasingly important role in our lives, the traffic on the Internet is growing at over 100% every six months. Thus, the workload on the servers is increasing rapidly and these servers are very easily overloaded. Several options exist to overcome this problem, besides hardware upgrades or additions.
For very busy web servers, the kernel overhead of switching tasks and doing I/O becomes a problem. Apache provides a solution for the high traffic problem through the mod_mmap_static module. This module ties files into the virtual memory space and avoids the overhead of “open” and “read” system calls to pull them in from the filesystem. This process can result in a good increase in speed when the server has enough memory to cache the whole document tree.
Furthermore, to improve the performance and to serve more requests per second, administrators can run a specialized web server that handles simple requests and passes everything else on to Apache. Another approach that cuts the operating system overhead is to have a small HTTP server built into the kernel itself. These two approaches are discussed later (see HTTPD Accelerators).
Apache modules through version 1.3 wrote directly to the TCP connection back to the client. This arrangement was simple and efficient, but it lacked flexibility.
An example of this inflexibility would be secured transactions over SSL. To perform encrypted communications, the SSL module must intercept all traffic between the client and the handler module. With no abstraction layer in place, this was a difficult task made even more difficult by the cryptography laws of the 1990s that prohibited adding convenient hooks. Administrators wanting to run secure sites had the choice of applying inelegant patch sets to the Apache source or using a proprietary and perhaps incompatible binary distribution.
In Apache 2.0 (with APR), all I/O is done through abstract I/O layer objects. This arrangement allows modules to hook into each other's streams. It will then be possible for SSL to be implemented through the normal module interface rather than requiring special hooks. I/O layers also help internationalized sites by providing a standard place to do character set translation.
In addition, with later Apache releases, I/O layers may support a “most requested module” feature that will have one module filter the output of another. However, this may not happen with Apache 2.1.
The original reason for creating Apache 2.0 was to solve scalability problems. The first proposed solution was to have a hybrid web server, one that has both processes and threads. This solution provides the reliability that comes with not having everything in one process, combined with the scalability that threads provide. However, this approach has no perfect way to map requests to either a thread or a process.
On Linux, for instance, it is best to have multiple processes, each with multiple threads serving the requests. If a single thread dies, the rest of the server will continue to serve more requests and the server will not be affected. On platforms that do not handle multiple processes well, such as Windows, one process with multiple threads is required. On the other hand, platforms with no thread support had to be taken into account, and therefore it was necessary to continue with the Apache 1.3 method of preforking processes to handle requests.
The mapping issue can be handled in multiple ways, but the most desirable way is to enhance the module features of Apache. This was the reasoning behind introduction of multiple-processing modules (MPMs). MPMs determine how requests are mapped to threads or processes. The majority of users will never write an MPM or even know they exist. Each server uses a single MPM, and the correct MPM for a given platform is determined at compile time.
Currently, five options are available for MPMs. All of them, except possibly the OS/2 MPM, retain the parent/child relationships from Apache 1.3, which means that the parent process will monitor the children and make sure that an adequate number is running.
MPMs offer two important benefits:
1. Apache can support a wide variety of operating systems more cleanly and efficiently. In particular, the Windows version of Apache is now much more efficient, since mpm_winnt can use native networking features in place of the POSIX layer used in Apache 1.3. This benefit also extends to other operating systems that implement specialized MPMs.
2. The server can be customized better for the needs of the particular site. For example, sites that need a great deal of scalability can choose to use a threaded MPM, while sites requiring stability or compatibility with older software can use a “preforking” MPM. Additionally, special features like serving different hosts under different user IDs (perchild) can be provided.
The prefork MPM implements a non-threaded, preforking web server that handles request in a manner similar to the default behavior of Apache 1.3 on UNIX. A single control process is responsible for launching child processes that listen for connections and serve them as they arrive.
Apache always tries to maintain several spare or idle server processes, which are ready to serve incoming requests. In this way, clients do not need to wait for a new child process to be forked before their requests can be served.
The StartServers, MinSpareServers, MaxSpareServers and MaxServers (set in /etc/httpd.conf) regulate how the parent process creates children to serve requests. In general, Apache is self-regulating, so most sites do not need to adjust these directives from their default values. Sites that need to serve more than 256 simultaneous requests may need to increase MaxClients, while sites with limited memory may need to decrease MaxClients to keep the server from thrashing.
While the parent process is usually started as root under UNIX in order to bind to port 80, the child processes are launched by Apache as less-privileged users. The User and Group directives are used to set the privileges of the Apache child processes. The child processes must be able to read all the content that will be served but should have as few privileges as possible beyond that.
MaxRequestsPerChild controls how frequently the server recycles processes by killing old ones and launching new ones.
The PTHREAD MPM is the default for most UNIX-like operating systems. It implements a hybrid multi-process multi-threaded server. Each process has a fixed number of threads. The server adjusts to handle load by increasing or decreasing the number of processes.
A single control process is responsible for launching child processes. Each child process creates a fixed number of threads as specified in the ThreadsPerChild directive. The individual threads then listen for connections and serve them when they arrive. The PTHREAD MPM should be used on platforms that support threads and that possibly have memory leaks in their implementation. This may also be the proper MPM for platforms with user-land threads, although testing at this point is insufficient to prove this hypothesis.
When compiled with the DEXTER MPM, the server starts by forking a static number of processes that will not change during the life of the server. Each process will create a specific number of threads. When a request comes in, a thread will accept it and answer it. When a child process sees that too many of its threads are serving requests, it will create more threads and make them available to serve more requests (see Figure 2).

Figure 2. Dexter MPM Model
The DEXTER MPM should be used on most modern platforms capable of supporting threads. It will create a light load on the CPU while serving the most requests possible.
The WINNT MPM is the default for the Windows NT operating systems. It uses a single control process, which launches a single child process that in turn creates threads to handle requests.
The PERHILD MPM implements a hybrid multiprocess, multithreaded web server. A fixed number of processes create threads to handle requests. Fluctuations in load are handled by increasing or decreasing the number of threads in each process.
A single control process launches the number of child processes indicated by the NumServers directive at server startup. Each child process creates threads as specified in the StartThreads directive. The individual threads then listen for connections and serve them when they arrive.
An MPM must be chosen during the configuration phase and compiled into the server. Compilers are capable of optimizing many functions if threads are used, but only if they know that threads are being used. Because some MPMs use threads on UNIX and others don't, Apache will always perform better if the MPM is chosen at configuration time and built into Apache.
To choose the desired MPM, you need to use the argument --with-mpm= NAME with the ./configure script, where NAME is the name of the desired MPM (dexter, mpmt_beos, mpmt_pthread, prefork, pmt_os2, perchild).
Once the server has been compiled, one can determine which MPM was chosen by using % httpd -l. This command will list every module that is compiled into the server, including the MPM.
The following list identifies the default MPM for every platform:
<il>BeOS: mpmt_beos<il>OS/2: spmt_os2<il>UNIX: threaded<il>Windows: winnt
As mentioned previously, web server performance can be improved in many ways. Besides upgrading the hardware running the server, HTTPD accelerators can be deployed. Users can either run a specialized web server to handle simple static requests and pass all other requests to Apache (or any other web server) or have a small HTTP server built into the kernel itself. Proofs of concept for both approaches are phhttpd (pointy-headed httpd) and khttpd (kernel HTTP dæmon).
phhttpd serves all requests from a single process and uses the “sendfile” system call to put most of the work back into the kernel, besides interpreting the HTTP protocol. phhttpd cannot run on its own, as it requires a backing full server that knows how to talk with phhttpd, such as Apache. The two servers establish a line of communication while running. phhttpd listens to all the incoming connections, and if it can't parse the request for whatever reason, it hands the connection over its line to Apache to process. phhttpd keeps an aggressive cache of content that doesn't change at each request. It uses this content to reduce the amount of processing that must be done per request. It also features a nonblocking event model that allows a single thread to serve many connections. The number of threads may be scaled to match the size of the hosting machine.
To cut out the operating system overhead, a small HTTP server can be placed into the kernel itself to respond to requests for static files. It runs from within the Linux kernel as a module, handles only static web pages and passes all requests for nonstatic information to a regular user space web server such as Apache. Static web pages are not complex to serve, but they are important because virtually all images are static, as are a large portion of the HTML pages. A regular web server has little added value for static pages; it is simply a “copy file to network” operation, and the Linux kernel is good at this.
ARIES (Advanced Research on Internet E-Servers) is a project that started at the Open Architecture Research Lab at Ericsson Research Canada in January 2000. It aimed to find and prototype the necessary technology to prove the feasibility of a clustered internet server that demonstrates telecom-grade characteristics using Linux and open-source software as the base technology. These characteristics feature guaranteed continuous availability, guaranteed response time, high scalability and high performance.
Building a high-performance and scalable system requires a web server that can keep up with hundreds of requests per second. The Apache web server is one of three web servers that we have tested. Our test system is a telecom grade 16-processor cluster targeted for carrier-class server applications. It was featured in the April issue of Linux Journal, where we discussed our experiments with the Linux Virtual Server.
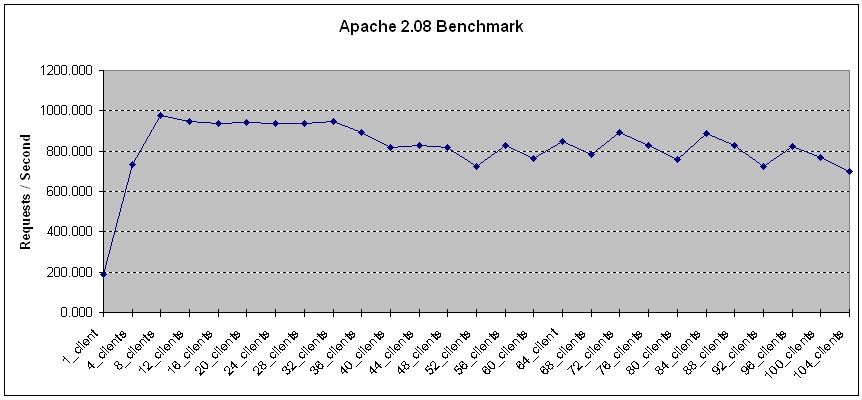
In an upcoming article, we will discuss Apache's performance in more detail and evaluate the performance of several other web servers, such as Jigsaw and Tomcat to see how they compare to each other. However, to give you a sample of how Apache 2.0 performs, we installed Apache 2.08 on a PIII server node with 512 MB RAM and started to generate HTTP requests to it using WebBench, a web server's benchmarking tool (see Figure 3).
Figure 3. Apache 2.08 Performance
Apache 2.08 was able to respond to an average of 817 requests per second, servicing up to 104 concurrent clients. One important factor is that this server node is diskless and Apache was serving the documents from an NFS partition (which presented some limitations). In other tests, we noticed much better performance (more requests/second) when Apache was servicing documents sitting on the server disk itself.
Based on our tests, we believe that Apache is considerably faster, more stable and more full-featured than other web servers. We look forward to testing and experimenting with the 2.0 release version, which promises clean code, well-structured I/O layering and enhanced scalability.
The Apache project will continue to be an open-source project that keeps up with advances in the HTTP protocol and web developments in general. The people behind the project are open to suggestions for fixes and improvements, and they respond to needs of large volume providers as well as occasional users. Part of Apache's original success was due to the numerous tests conducted by both developers and users. The Apache Group maintains rigorous standards before releasing any new version of the server, and when bugs are reported, the developers release patches and new versions as soon as they are available. If you are an IT manager or a system administrator currently using Apache 1.3.x, I highly recommend upgrading to Apache 2.0 once the release version is available.
Thank you to Martin Pool for his permission to reuse material from his presentation given at the AUUG2k Winter Conference.
Ibrahim F. Haddad works for Ericsson Research Canada researching Carrier-Class Server Nodes in real-time all IP Networks.
The Apache Software Foundation: www.apache.org
Apache Week: www.apacheweek.com
IPv6 Information Page: www.ipv6.org
Kernel HTTP Dæmon: www.fenrus.demon.nl
MM Shared Memory Library: www.engelschall.com/sw/mm
Netcraft: www.netcraft.com
phhttpd: www.zabbo.net//phhttpd
Ryan Bloom's Index for Apache Portable Runtime: www.ntrnet.net/~rbb/aprpres
WebBench Benchmarking Tool: www.zdnet.com
WebDAV: www.webdav.org

{kind=link}