
Inner Workings of WANPIPE
From the start, Linux has been the operating system of choice for network appliances—devices that provide services such as network address translation (NAT), firewalling, virtual private networks (VPN), mail services and web caching. It was therefore a natural requirement, from the earliest days, that Linux provide internal support for wide area network (WAN) connectivity.
In 1994, Sangoma began developing its WANPIPE code and utilities for Linux to supplement drivers that had been written by third parties to support Sangoma WAN cards.
WANPIPE supports the Sangoma S series. Included in this series are cards such as the S514 PCI and S508 ISA—intelligent adapters that support most WAN protocols in firmware, including Frame Relay, PPP, HDLC, X25 and BiSync.
Because protocols are supported in firmware, design of the device driver is much simpler. It is easier to port to a new operating system as there are fewer chances of failure and CPU load is kept to a minimum. These characteristics enable a relatively slow machine like a 486 to use a Sangoma adapter and Linux to create a powerful T1 router.
With protocols isolated on the board, it is possible to test and certify the protocol implementations of one operating system and know that they will work identically on any other operating system. If necessary, a protocol update can be installed on the fly, without recompiling the driver or the kernel.
Sangoma adapters can have two different physical interfaces, T1 (CSU/DSU on board) or serial V.35/X.21/EIA530/RS232. The card with the T1 interface allows the server to connect directly to the T1 line without an external CSU/DSU.
Sangoma S514 and S508 cards support up to four high-speed sync lines, each carrying a multichannel WAN protocol. The driver architecture was based on the following requirements:
Multi-adapter support, where each adapter can have up to four physical links
Each link can have a maximum of 255 logical channels
Control and configure each link separately
Control and configure each logical channel separately
Support multiple protocols: Frame Relay, CHDLC, PPP, X25, SDLC, etc.
Easily expandable (future protocols)
Support for both Routing and API applications simultaneously
Secure socket for API applications (No silent packet dropping allowed)
Local and remote debugging support
SNMP Support
Fast Tx and Rx paths
Proc file system support: statistics and debugging
Driver Message/Event Logging
Easy updates and upgrades
The following design rules were adopted in developing the driver:
1. WANPIPE drivers map each active physical link to a separate device in the kernel. Each physical line can be configured, restarted or debugged without conflicting with other sync lines. WANPIPE drivers can support up to 16 devices, four cards with four physical links.
2. Since WAN protocols can have many logical channels on a single physical link, each channel is mapped to a network interface. WAN protocols, such as Frame Relay or X.25, support one-to-many connections through the use of logical channels. For each physical line, WANPIPE supports up to 255 logical channels for X.25 and 100 logical channels for Frame Relay. Each logical channel can be restarted or reconfigured without bringing down all other channels on the same physical link.
3. Management/debugging interface calls are user datagram protocol (UDP) based and OS independent. Sangoma adopted a common UDP-based interface for collecting statistics and managing WAN links to provide an alternative to SNMP-based tools that are often complicated and costly. Sangoma felt that users should be able to easily interrogate and manage the system remotely, using tools that are included in the WANPIPE package.
The system developed is UDP-based and operating system independent so that, for instance, a Windows GUI application can be used to monitor a remote Linux system. The system is password-free but can be made to operate in a highly secure manner.
4. Each network interface can support either API or ROUTING mode. Aside from IP routing, many of Sangoma's customers use the Sangoma S series as communication building blocks for their own applications, using our published applications program interfaces (API). These applications include such diverse uses as:
Providing unidirectional broadcasts of financial information and newscasts over satellite links.
Monitoring cellular switch information using X.25.
Emulation of IBM mainframes or controllers over SDLC, X.25 or BSC.
Controlling military hardware using HDLC LAPB.
For maximum flexibility, the architecture was designed so that API calls and standard IP routing traffic can coexist on any physical port. For instance, a set of X.25 logical channels can be used to provide standard IP connectivity between a series of locations while other channels are used to exchange point-of-sale (POS) credit card swipe information that is not IP-based. The driver can accept API or routing packets simultaneously, depending on the network interface setup.
5. No API packets to be dropped by the stack. IP stacks are designed to silently discard packets when congested. This is accepted behavior in the IP world, where data integrity is ensured by higher-level TCP protocol. However, in the case of error-correcting protocols such as BSC, HDLC LAPB, X.25 and SDLC, it is assumed that once a packet has been acknowledged at the link level, delivery to the application is guaranteed. Therefore, it was absolutely necessary that the WANPIPE raw socket stack would not silently drop packets.
6. WANPIPE device drivers should be loaded as modules into the Linux kernel.
Using modules, rather than compiling the kernel, makes it easy to update the driver. Also, because only the modules need to be compiled, no reboot is needed.
Employing the above design rules, WANPIPE device drivers maximize the utility of the S series cards. Clearly defined data, debugging and (re)configuration paths enable simultaneous multiprotocol operation to be efficient, configurable and manageable. The design of the driver is shown in Figure 1.
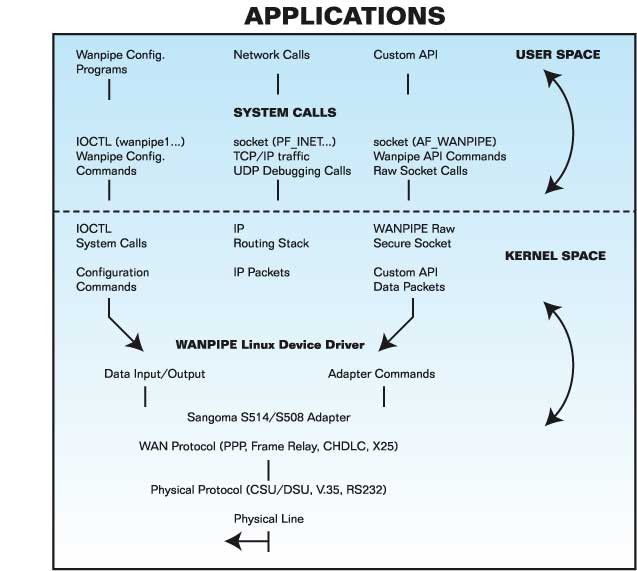
Figure 1. How the WANPIPE Device Driver Fits into the Linux Kernel
Figure 1 shows how the WANPIPE device driver fits into the Linux kernel architecture. Linux is divided into two operating regions, the user space and the kernel space. All applications, dæmons and utilities execute in the user-space, while kernel and device drivers execute in the kernel space. Communications between user space applications and the kernel are facilitated through system calls such as ioctl.
Device drivers, an integral part of the Linux kernel, interface hardware components to the operating system. Drivers are usually compiled into the kernel or provided as independent, separate modules that can be dynamically loaded or unloaded at run time.
Sangoma used modular drivers in WANPIPE because modules can easily be updated and reloaded while the kernel is running, eliminating the need for costly system reboots.
WANPIPE, being a network device driver, uses network interfaces to bind to the Linux kernel stack. The network interfaces contains Level 3 protocol information (IP) as well as driver entry points, enabling the Linux kernel stack, via the network interface, to control driver operation: interface shutdown, startup, statistics and data communications.
The WANPIPE configuration process starts with creating a detailed configuration file that outlines the hardware, protocol and IP options as well as location of the adapter firmware. Once completed, WANPIPE driver modules are loaded into the kernel. The initial module load allocates necessary resources, initializes and sets up the proc file system directories and enables the ioctl system calls. Since loaded modules do not have enough information to completely configure the card, ioctl system calls are used to pass the contents of the configuration file to the driver. The final step in WANPIPE configuration is to configure and start up network interfaces using the ifconfig() command. The sequence is shown in Table 1.
The kernel IP layer provides a packet transfer service; that is, given a packet complete with addressing information, it will take care of the transfer. In conjunction with the IP layer, the routing table (see Table 2) determines the forwarding order of all incoming packets.
Table 2. Kernel IP Routing Table
Once the WANPIPE network interface (wp1_fr16) is up and running, the kernel routing table is updated with the interface's IP information. The wp1_fr16 interface has two entries. The first one specifies the destination network and the second indicates a default route, meaning that all IP addresses not specified in the above routing table will be forwarded to wp1_fr16 interface.
Upon successful driver configuration, network interfaces and routing tables can be viewed and modified from the user space using the standard Linux commands:
ifconfig—display or modify network interfaces
route—display or modify the routing table
An API is used to send and receive custom RAW, non-IP packets to and from the card. Since data is not communicated in IP format, the network interface is configured without the IP address. This effectively removes the kernel routing table entry and unhooks the IP routing stack from the WANPIPE driver. Non-IP communication is achieved using the RAW socket calls to the driver. As the name implies, packets are transferred without any modification.
To ensure that packets that had been acknowledged at the card level were never lost, a secure socket solution was developed: a custom WANPIPE socket that guarantees delivery in both upstream and downstream directions. The WANPIPE socket is based on the Linux RAW socket, developed by Alan Cox and others.
We provide the following as an example of working with the WANPIPE API set. We have chosen X.25 as a line protocol because it is probably the most complicated, involving call set up and tear-down, logical channel management and exception condition handling. X.25 is a packet-switched WAN protocol that (generally) uses a public packet-switched network to route packets to different end points. In operation, it appears to be similar to TCP/IP, although the underlying mechanisms are quite different. Line speeds are almost always below 256KBps, usually below 64KBps. Its operation is analogous to a telephone. A call must be initiated, and once the call is accepted, data can be transmitted. When data transmission is over, the call is cleared. Using the WANPIPE secure socket, X.25API programming is very similar to TCP/IP programming.
To continue our example, we assume that the WANPIPE drivers are configured and successfully started, and that the X25 link is up and running (see Listings 1 and 2 at our FTP site—ftp.linuxjournal.com/pub/lj/listings/issue82).
WANs, by their nature, are quite complicated. There are usually several players, including one or more Telcos, often a public network provider and often a separate ISP that adds to the confusion. The inevitable line teething problems and ongoing line debugging can often denigrate into futile finger-pointing exercises.
For this reason, a major part of the WANPIPE development has been devoted to debugging. Sangoma's philosophy is to provide customers with enough debugging information so that the customers can solve most problems by themselves. Furthermore, if support is necessary, Sangoma tech support must have enough information to solve the problem remotely.
Each WAN protocol has its own debugging utility that is used to determine the status of the driver and physical line, obtain protocol state and statistics, as well as raw and interpreted line traces. The data transfer involved in the monitors is UDP-based. Remote systems can be debugged via the Internet, without logging into the user system, while system security can be tightly managed. UDP calls are OS-independent, meaning that a remote Linux machine can debug a WANPIPE card running in a FreeBSD or Windows machine.
Since system security is an important issue, the UDP debugging commands can be turned off by setting the UDPPORT to 0, or better yet, by setting the TTL (time to live) value to a small one. By setting the TTL value to one, for example, only users that are logged into the machine or located in front of the first router will be able to operate the debugger. The TTL and UDPPORT values are configurable in the WANPIPE configuration file.
A current list of monitors and typical commands is given in Table 3. Under Windows, X and other graphic environments, the complicated command lines are replaced by simple GUI applications.
Table 3. Monitors and Typical Commands
The driver receives management requests via the UDP/IP stack. All received requests are then forwarded into a low priority queue. A low priority thread handles requests and sends the results back up the stack, to the originating IP address. UDP debug requests can also come from the network where the request is sent back through the line. Management connections through the network interface are treated differently from traffic from “above”. Only statistics are available through the network, while access from above allows the user to also reconfigure, test and set up the CSU/DSU and run line traces.
The proc file system is a memory mapped virtual directory structure that is used to provide driver and kernel information. Management systems, such as SNMP, use the proc file systems to obtain kernel/driver statistics and states. The WANPIPE driver binds into the proc file system by setting up /proc/net/wanrouter directory. This directory contains virtual files for each WANPIPE device. WANPIPE configuration and statistics can be obtained by reading/opening supported /proc files. To display tx, rx and error statistics for, say, the wanpipe1 device, use this command: cat /proc/net/wanrouter/wanpipe1
Nenad Corbic, senior data communications specialist—Heading the Linux development team at Sangoma, Nenad works with senior management to ensure Sangoma's Linux customers are provided with innovative wide area network (WAN) communications technology. Nenad is responsible for WANPIPE device driver design and development, WANPIPE quality assurance, new product development and third-level customer/developer support. He also has interests in the Linux routing project and embedded Linux development. Nenad holds a BEng in Computer Engineering from Ryerson Polytechnic University in Toronto.
David Mandelstam, chief technology officer—Spearheading Sangoma's growth since inception, David remains committed to developing and improving technology for wide area network (WAN) communications. As chief technology officer and founder of Sangoma, David directs the technology strategy and corporate research activities, managing development of new product technologies and overseeing the entire manufacturing cycle. David holds a BSc in Mechanical Engineering from the University of Witwatersrand in South Africa, an MSc in Aerodynamics from the Cranfield Institute of Technology in the United Kingdom and a BComm from the University of South Africa.

