
Software ICs
Software engineers should look to their hardware counterparts for approaches to managing complexity. Before the advent of Integrated Circuits, electronic circuits were generally complex creatures with many interconnected discrete components. The complexity of the circuit was visible, difficult to manage and adversely affected the cost of products. With the advent of ICs much of this complexity was hidden inside the chips themselves. The job of designing complex functionality into products became much easier.
Despite many attempts over the years, software design has never been able to replicate this IC design paradigm. The advent of object-oriented programming languages and tools was supposed to address some of these issues. While object-oriented design offers some significant improvements in areas such as GUI programming it doesn't always do a great job of hiding complexity. In fact, they often simply shift the complexity into other areas in the software development chain such as testing, toolsets, class library design or the learning curve.
Modern hardware design requires a complex skillset. What the advent of ICs did, however, was allow the hardware designer to use a given chip in a product design without having to understand the exact physics and layout of the circuits contained within the chip itself. As long as the designer conformed to the specs at the external interface to the chip (pins) the chip will react in a very predictable manner. This is what encapsulation of complexity offers: complexity hiding and predictable/reproducible behavior. Objects in software design offer partial complexity hiding, but the software designer often still has to know and master a complex language (e.g., C++) in order to be able to wire objects together into a product. Objects are very poor at providing predictable and reproducible software behavior. Furthermore, the language of the objects themselves often dictates the language used to “wire them together”. In our opinion, true encapsulation of complexity behind a universally simple and extendable API is what is required to produce a software IC. The software designer should not have to master a complex object-oriented language and toolset in order to be able to “wire together” these software ICs. At the very least the software designer should be able to choose the wiring language independent of the chip language.
Many RTOSes have pioneered the use of user-space processes as an encapsulation scheme. One of the oldest to use this scheme is QNX TM (http://www.qnx.com/). Since 1980, QNX has released a continuous series of innovative OSes that were based upon a set of cooperating processes all using a Send/Receive/Reply messaging paradigm. QNX's approach to kernel design differs greatly from that used in Linux and we do not wish to reinflame the infamous microkernel vs. monolithic kernel debate. Suffice to say that we believe that the process model and the Send/Receive/Reply messaging paradigm first pioneered by QNX offers the key ingredients of a successful software IC.
In most modern operating systems, including Linux, the process is a very robust computing entity. There are several layers of protection offered to a process and the resources it embraces when running on a processor. It is very difficult for two processes to inadvertently adversely affect one another. If a given process encounters a fatal bug and crashes, it is rare that the entire system will be compromised. So the userispace process in Linux offers us a great container for our software IC. Now all we need is the software analog of the pins. This is where the messaging paradigm comes in.
One of the most powerful message formats is also one of the simplest. We can view a message as simply a collection of bytes. This collection of bytes is divided into two parts. The first field of bytes which is of fixed length is always present in every message and taken together, these bytes represent a unique message identifier called a token. The balance of the message (which can be of variable length) represents the token context-sensitive data. When two processes wish to exchange such messages they simply agree on a token scheme and on the format for each tokenized message they want to exchange. The interprocess message transport layer need not be concerned at all with the message content.
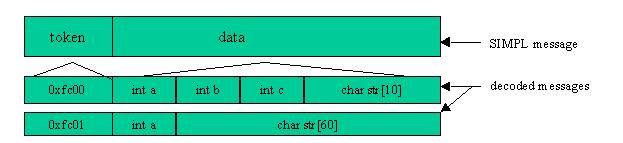
Figure 1. Tokenized
One of the goals of any software design is to produce software which behaves predictably and reproducibly under a given stimulus. Many object-oriented and message-oriented design paradigms suffer because they introduce a degree of unpredictability and randomness into a software product. If a message is exchanged with a mailbox scheme and the sender and the receiver are never brought into synchronization it will be exceedingly difficult to replicate or predict all possible states that two process system can be in. Much depends on the environment and timing considerations in which these two processes find themselves. These modules may work fine in one environment and suffer sporadic failures in another. This leads to increased testing and maintenance costs and a poorer software product. Often the blame is incorrectly directed at the multiprocess design paradigm. How often have we heard it said that client/server software design does not handle complexity well. The original designers of Send/Receive/Reply synchronized messaging believed that the answer lies in forcing a state-machine-like synchronization to occur on each message pass.
It works like this: a sending process composes a message and arranges to send it to a receiving process. While waiting for a reply the sending process is blocked. The receiving process, on the other hand, is held blocked until a message arrives destined for it. It unblocks, reads the message, processes its contents and then replies to the sender. This reply then unblocks the sender and the two processes are free to operate independently once again.
Many have argued that this blocking/forced synchronization introduces unnecessary complexity into a message exchange, but when properly applied it achieves exactly the opposite effect. By forcing synchronization to occur at each message pass, one finds that our multi-process applications now start to behave in a very predictable and reproducible manner. Gone are the timing and environmental effects that often plague nonsynchronized message passing schemes. When dealing with huge complex applications, this represents a huge strategic advantage. As an added bonus, since the sender is blocked during message transmission and is explicitly unblocked by the receiver process with the reply, it is very simple to arrange to transport these messages over a variety of media (including some which are “slow”). The messages could be exchanged via shared memory if the processes were on the same processor, or they could be exchanged via the Internet if the processes were physically separated or on a serial line in a dial up situation. While the performance of the collective of processes would obviously be affected by the message transmission speed, the predictability and reproducibility of that performance would not be.
The importance of predictability of software cannot be overstated when it comes to software testing. Nothing makes software QA people wish for a career change more than an application which exhibits unpredictable and unreproducible behavior.
To help promote this software IC paradigm in the Linux community we started the SIMPL open-source project (www.holoweb.net/~simpl). SIMPL enabled processes are Linux processes with all the features and protections that affords. SIMPL enabled processes are able to exchange tokenized binary messages using a blocking Send/Receive/Reply messaging scheme. In short SIMPL processes have the makings of some great software ICs.
Before going into more detail on how these software ICs might be built, it is worth emphasizing the advantages of this model.
In principle, SIMPL processes can be written in any language. While much of the code on the SIMPL web site is still written in C, there is no reason why a C++ or JAVA SIMPL process could not be created and talk transparently to another SIMPL process written in Tcl/Tk or Python.
The language used to write the software IC itself in no way dictates the language of another software IC with which interaction takes place. Furthermore, a given SIMPL process has no way of discovering what language was used to construct another IC with which it is exchanging a message.
A SIMPL software IC has no way of discovering or knowing the physical location of its exchange partner. This means that the same binary image can be tested with local message exchanges and then deployed with remote message exchanges. Overall collective application performance would differ but the individual software IC would not need to change in any way. In may instances even a recompile is unnecessary.
A SIMPL software IC has no way of discovering the internal algorithm of an exchange partner. This means that test stubs can be created which completely simulate and replicate the environment in which a given software IC finds itself. In particular, error conditions which would be costly or difficult to reproduce in the full system can readily be simulated in a test environment. These SIMPL software ICs can be rigorously tested before being deployed in the real-world application.
SIMPL software ICs lend themselves well to projects with multiple developers. The implementation details of a SIMPL enabled process cannot affect any interacting process, provided that implementation conforms to the agreed upon message API. While a poor IC implementation will certainly adversely affect the overall application performance, the application will still operate. Once a poor algorithm has been identified it can be worked on in isolation from the real application and substituted once tested without even recompiling the adjacent ICs.
The most basic SIMPL processes types are:
senders—those processes that compose messages and wait for replies
receivers—those processes that wait for messages and compose replies
All the software ICs discussed in this section will be composites or special types of these two basic building elements. The SIMPL project is governed by the LGPL or similar open licenses. All of the source code for the software IC discussed below is available on the SIMPL web site.
Simulator One of the great advantages of the SIMPL paradigm is that it allows for the ready development of testing stubs. We have adopted the following naming convention with respect to these testing stub processes.
the stub for a receiver process is called a “simulator”
the stub for a sender process is called a “stimulator” A typical simulator setup might look as follows:
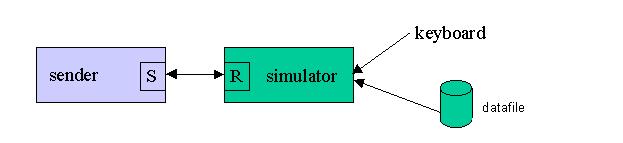
Figure 2. Simulator
The item being tested here is the sender. The key to understanding simulators is understanding the fact that, provided the simulator conforms to the SIMPL naming convention expected at the sender and conforms to all the expected message formats that the sender can exchange, the sender will not be able to detect that it is talking to a test stub. As such, the sender process can be vigorously tested in a very realistic test “sandbox” without having to alter the deployed executable in any fashion. There is no need for conditional compiles, test flags, etc., that are typical of unit test scenarios in non-SIMPL designs. Once tested, the sender executable can be deployed as is in the final application.
The exact composition of the simulator code is highly dependent on the application. The diagram above illustrates a typical scenario whereby one desires to have the ability to interact with the simulator directly via keyboard commands. In addition the canned responses are being fed in from a data file.
One can imagine more sophisticated simulators where the whole test sequence is metered in from the data file in a highly controllable manner.
Stimulator
When the object needing unit testing is a receiver process, one would typically use a stimulator to replace the real senders in the test phase.
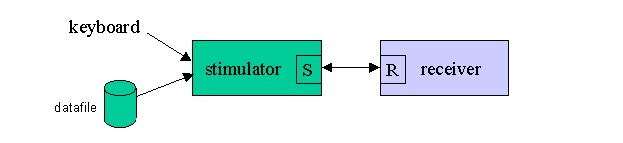
Figure 3. Stimulator
The item being tested here is the receiver. As was the case with the simulators above, the key here is that, provided the stimulator conforms to all messaging and naming conventions, the receiver process will have no way of knowing that it is being sent a message from a stimulator or from the real sender in the final application.
As was the case with the sender process in the simulator example, the receiver under test here can be the final deployable executable in all respects. Once again no conditional compilation or other executable altering techniques are required in the SIMPL paradigm.
As with the simulator, the typical stimulator contains a keyboard interface for the tester to interact with. More sophisticated stimulators may feed the test input from a data file.
The importance of being able to test deployable executables in a SIMPL application cannot be emphasized enough. In our experience this is one of the most important reasons for considering the SIMPL paradigm in designing software applications.
Relay
In a SIMPL system all processes are named. In the simplest of systems the names are normally assigned to processes (and passed to other processes) as part of the startup information on the command line. Occasionally it is desirable to simplify the amount of name information that needs to be passed into the code. The construct called a relay is useful for this type of thing.
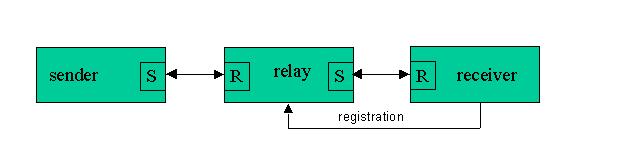
Figure 4. Relay
The basic relay operation is quite easy to grasp. The sender thinks that the relay process is the intended receiver for its messages. It does all the normal name locate and send operations as if it were part of a simple sender/receiver pair. The relay process on the other hand does nothing at all with the message. It simply remembers the ID of the sender and then forwards that ID on to the registered receiver process. When the receiver gets the relayed message it connects to the shared memory block of the sender process and retrieves the message in the normal manner. Once the message is processed the receiver places the reply in the sender's reply area and replies the sender ID back to the relay process. The relay process then simply replies back to the sender in the normal manner. Note that because of the SIMPL architecture, the relay process never needs to copy the message during these activities.
The advantages of this construct over a basic sender/receiver pairing lie in the name hiding that can occur with the receiver. It is also possible to start and stop receivers dynamically in this scheme without having to recommunicate naming information to the various senders in the system. If that occurs the startup message exchange, called registration in the diagram above, takes care of notifying the relay task of the new receiver's name information.
The ability to start and stop processes dynamically without cycling the whole application can be a significant advantage, particularly if the receiver logic is undergoing frequent upgrades or enhancements. These can be rolled in dynamically, and if problems occur the original copy can quickly be rolled back into play. In fact, with the registration scheme, both receiver processes could be running and a quick message exchange will have the effect of “routing” messages to the new receiver (or back again). With the registration scheme, the receiver in question can override an existing registration. While some may view this type of thing as a potential security hole it is only open to someone with privileges for running a new process on the system. It is relatively easy to build a certificate-type check on top of the registration process to close this hole considerably if that is an issue.
Obviously the relay will incur a performance penalty over the straight message exchange, but in many circumstances the advantages which come with the construct outweigh the disadvantages. The relay is a powerful SIMPL construct.
Agency
In addition to the name-hiding capabilities of the relay construct, it is sometimes desirable to exert greater control on the messages and their sequencing. The agency is a useful construct for these types of applications.
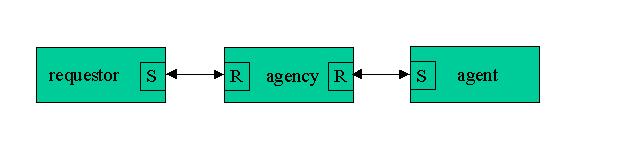
Figure 5. Agency
To understand the agency, one needs to understand the concept of reply blocking. In a normal SIMPL message exchange the receiver is receive blocked. Once the sender sends a message it is then said to be reply blocked. The key to the agency construct is that the receiver does not need to reply right away to that particular sender. It can simply remember the ID and go on about its business. In fact the receiver can “hold” the sender waiting and go back to being receive blocked for a new message. When new information arrives via a message from a second sender the receiver could choose to reply to the original sender with that information using its previously remembered ID. Another way to look at a reply blocked sender is as a “receiver” that doesn't block its “sender”.
To avoid some confusion of semantics, we have adopted the naming convention for the agency processes as per the diagram above. The requestor is simply another name for the normal sender. As far as this process is concerned the intended receiver for the message is the agency itself. The agency process however is completely neutral to the actual message content. It is simply going to act as “store and forward” for the requestor(s) messages. It is important to note that with the basic SIMPL package all “sender” type processes place their message in a block of shared memory which they own and control. The actual message does not need to be copied out of the sender's buffer by the receiver but can be read directly by linking to the shared memory area. The agency construct takes advantage of this fact. When the requestor sends a message to the agency, the agency does not copy the message anywhere. It simply notes the ID of the requestor and does one of two things:
Queues the requestor ID
Forwards the requestor ID on to the agent process
The agent in this scheme contains all the normal “receiver” logic for this application. It is, however, working as a reply blocked sender. In its simplest form the agent talks to the agency in three different message formats:
WHAT_YA_GOT request for any queued messages
To which the agency will reply GOT_ONE requestor messages for it to process
To which the agent will respond by sending AGENT_REPLY messages which contain the processed reply destined for the requestor
To the requestor it all went exactly as if it had been sending any SIMPL message to a basic receiver. In fact there is no difference in the requestor code for dealing with agencies. Why then go to all this trouble?
First of all, it is now possible to dynamically start and stop the agent process in this system without affecting the requestor (other than delaying responses to a request that arrived while the agent was being cycled). In systems where the agent might be undergoing significant revisions or upgrades, this might be a distinct advantage.
Secondly, the requestor in this system does not need to know the name of the agent in order to exchange a message with it. The agency construct can be viewed as a message gateway.
To understand the further advantages we need to examine the case where we may have multiple requestors all talking to the same agency and agent. In this scenario the agency will actually receive all the requestor's messages and will queue their originator's ID's. The agency logic can then be in control of the order in which these messages are dispatched to the agent. In a normal sender/receiver pairing the FIFO imposes a first-in, first-out ordering and it is not possible to have a higher priority message jump ahead in the queue. In the agency scheme this is very possible.
In addition, in the normal SIMPL sender/receiver pairing the messaging is synchronous. It is intentionally difficult to kick a sender out of a reply blocked state by any other means than by having the receiver do a reply. This means things like timeouts or “aged data” are difficult to handle. The agency scheme makes these things relatively easy to manage. While messages are pending in the agency queue, the agency can be kicked into examining these periodically for timeouts or aging.
The agency construct will suffer a performance penalty when compared with a basic sender/receiver pair because at least two extra messages need to be exchanged in each transaction. The agency construct, however, is a powerful one and can be used to great advantage in certain designs.
Occasionally it is necessary in a design for two receiver processes to exchange messages. The courier construct illustrated below is a good way to accommodate this requirement.
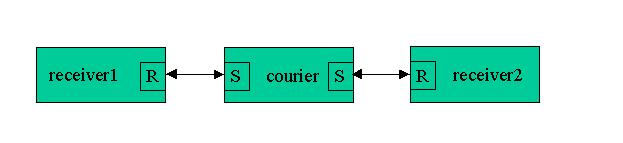
Figure 6. Courier
A typical example would involve a user-interface process. Typically user interfaces, be they simple text-based interaction or GUIs, want to be receiver-type processes. It is not often that you would want the user interface to block on a send. Very often in these designs the user interface (UI) requires information from another receiver process. If you went ahead and coded a blocking send into the UI then you could potentially have a place in the operation of the UI where the interface would freeze while the request was being serviced. This may not be the desired behavior.
The courier construct takes advantage of the delayed reply concept illustrated in the agency construct above. In our discussion we will assume that the UI process is “receiver1” and the recipient process is “receiver2”. When the courier process is started the first thing it does is locate the UI process it is designated to service. Once located, the courier will send a registration-type message to that process indicating that it is ready for action. The UI process will simply note that the courier is available and not reply, thereby leaving the courier reply blocked. At the point in the UI where the asynchronous request to the receiver2 process needs to be accomplished, a message is composed and sent (replied) via the courier. The courier is now unblocked and proceeds to locate and forward the message to the receiver2 process using a blocking send. At this point the courier is reply blocked on receiver2 and the UI is completely free to do other things as permitted by its logic. When receiver2 replies to the courier, the courier simply forwards that reply on to the UI process using a blocking send and once again becomes reply blocked on the UI. The UI receives this message in the normal manner, notes that it came via the courier, marks that the courier is once again available and processes the message in accordance with the logic coded.
This simple courier described above is a single request version. If a second UI request intended for the receiver2 process is generated within the UI before the courier returns its first response that request will be refused, siting the “busy courier”. A simple enhancement to this single request logic is to have a single-message-queuing capability in the UI. The “busy courier” response then would only come if a third UI request is attempted before the original response is received. In most UI processes this single message queue is more than adequate. A larger queue depth algorithm could be constructed readily, but the need for this is often indicative of a poor UI design elsewhere.
Another variation on the courier model is to have a parent process fork the couriers on demand. In some cases this capability is more desirable than having the courier prestarted along with the GUI process. The web applet type GUI applications are examples where this courier spawning technique is desirable.
Especially in user-interface designs, the courier construct is a very useful SIMPL building block indeed.
There are times in a design where there is a need for a one-to-many sender/receiver relationship. For simple cases, one can simply have the sender locate all the intended recipients and loop through sending to each. In more sophisticated designs the broadcaster construct illustrated below is very powerful.
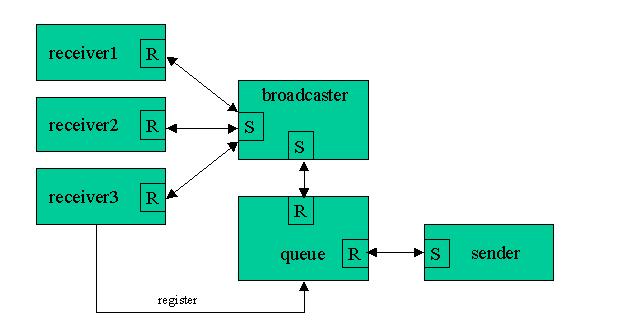
Figure 7. Broadcaster
The broadcaster actually consists of two parts: a receiver and a sender. We call the sender part the broadcaster. The receiver is typically a message queue as we shall see shortly. It works in the following manner: and the queue looks after message queuing and sequencing. The broadcaster maintains a list of processes to send to.
A typical sequence may start with a receiver (say receiver1) deciding that it wishes to receive broadcast messages. As part of that sequence it sends a registration-type message to the broadcaster's queue process. The queue will then place a REGISTRATION-type message onto its internal queue. Meanwhile the broadcaster returns from one of its broadcast sequences by sending a message down to the queue process asking whether there are any new messages queued. In this example the REGISTRATION message for receiver1 is delivered as a reply to the broadcaster. When the broadcaster process detects that the message is a new REGISTRATION, it does a nameLocate on that the recipient (receiver1 in this example) and stores the ID in its internal broadcast list. It sends a confirmation message back to the queue process, which then proceeds to reply and unblock the original receiver (receiver1—who was temporarily a sender). If there were no more messages on the internal queue, the broadcaster would simply be left reply blocked at this stage. At this point the sender may send a message to the broadcaster's queue process that is intended for broadcast. Typically the queue would queue the message and reply immediately to the sender, but one could do a blocking send scheme similar to that of the registration process. If the queue detects that the broadcaster is reply blocked it immediately forwards the message via a reply to the broadcaster. Once the broadcaster gets the message it notes that this is not a registration and therefore is a message to be sent to all the registered recipients in its broadcast list. Once this series of sends is complete the broadcaster will send back to the queue for the next message and the process repeats.
When a recipient wishes to cancel its registration with the broadcaster, it simply repeats the registration process with a DEREGISTER message to the queue. It is typical that the queue would simply queue and acknowledge this request.
If a recipient “forgets” to deregister and simply vanishes, the next broadcast attempt will detect that condition and the broadcaster would proceed to remove that ID from its internal broadcast list.
The broadcaster construct is a very powerful SIMPL tool. A typical example of its use would be to synchronize multiple instances of a GUI applet with the same information.
The SIMPL paradigm adds some important tools to the Linux developer's toolset. With its process centric model of encapsulation, coupled with a blocking Send/Receive/Reply messaging, the SIMPL libraries make an excellent platform on which to develop software ICs. We believe that the advantages of this software development paradigm are significant and cost effective.
All of the source code for these Software ICs is available on the SIMPL web site. While this source code delivery method for these ICs is effective as a means to “seed the thinking” it does not mean that SIMPL ICs must be delivered in source code format. There is nothing in the LGPL license that the SIMPL project uses that prevents software ICs from being deliverable in binary format.
This opens up an exciting era is software design. Software designers may finally be on par with their hardware cousins when it comes to managing project complexity.
Robert D. Findlay (fcsoft@attcanada.ca) has been involved in software development for over 20 years. While many of the projects over the past 15 years have involved QNX and various UNIX systems, the past two years have been exclusively LINUX. In his endless quest for “there must be a simpler way” he co-founded FCsoftware five years ago. When not working to keep the business afloat, he enjoys spending time with his wife Gloria and their two large dogs at their country home—built in 1860.
