
Economical Fault-Tolerant Networks
In the past decade or so, we have seen the evolution of computer networks as a merger of the communication and computing worlds. This revolution has made the dream of global connectivity possible, and with it has brought an explosion in the number of people utilizing computer networks for numerous vital tasks. The sheer volume and importance of tasks being ported to network-based applications and services has made reliability an undeniable need. On the other hand, networks fail all the time for a variety of reasons, including but not limited to power failures, communication link breakdowns, hardware failures and software crashes. Overcoming these failures and maintaining network services to users is addressed by implementing fault tolerance.
One common method for implementing fault tolerance is redundant data replication. Employment of an exact copy in place of a failed network component ensures availability of services on the network. The process of fault detection and replacement must be quick and automatic in order to make the fault invisible at the client end.
Our solution bases itself on a cluster of identical Linux servers, providing various network services. We did not employ any additional links other than the standard network connectivity. Various components within the solution include an algorithm to select a successor to a failed component, and both clock and data synchronization procedures among the processes. The services and data are replicated on all computers within the cluster. In the event of failure of a server, it is to be replaced by a replica, which carries a redundant copy of all data and service configurations offered by the crashed machine. After the detection of a failure, an election process is enacted among the identical servers and a replacement for the crashed server comes forward. Under normal working conditions of the network, the current server regularly pushes clock time, data and key configuration files to the rest of the cluster in order to maintain them as peers.
The standard techniques for improving the reliability of the network can be divided into two broad groups.
Dedicated hardware: this is expensive, and needs special maintenance. Examples of such a method include RAID (redundant array of inexpensive disks) and non-IP solutions requiring secondary communication links between machines.
Secondary backup machines: these are machines identical to the primary server and are maintained as mirrors of the primary. Their major drawback is not their high cost, but that under conditions of network failure, the switchover to the backup machine is not transparent to the clients. In fact, the clients need to be configured in advance with secondary (or slave) server parameters. The clients for most of the services will usually try the primary server first; then, on timeout, attempt to use the secondary server. This introduces unnecessary overhead and delay. Another important thing to note is that the backup machine is 100 percent redundant, used only when the primary server is under fault.
The problem is in achieving a software solution to ensure reliability, without the need of additional hardware and to keep the switchover transparent to the clients. Furthermore, we would not like to waste resources by completely dedicating one or more machines to a backup role.
Our solution finds its roots in the already-established backup system of primary and secondary servers. Instead of using two computers, we employ a set of computers. One of these computers is selected to act as a master machine to coordinate the network services, while the rest assume the role of slave machines: general-purpose server-class machines that take part in the election. The master server sets up a virtual IP address and starts all services required for normal operation of the network. The slaves monitor the status of the master for failures. If a failure occurs, a new master will be chosen and services to the network restored; the change is transparent to the clients. The slaves are not intended to be dedicated solely to this purpose; rather, they may be employed to perform other tasks (compute servers, workstations, etc.). Only on being chosen master does a machine also take on the task of establishing the virtual server.
The most crucial task in the event of failure is the selection of a new master machine. It is not possible to predict which machines in the chain would be unavailable due to earlier failures or being switched off. Therefore, a simple pre-established hierarchy of switchover, like the one in primary/secondary servers, is not practical. Moreover, a single coordinator for selecting a master cannot be used, because failure of this coordinator would result in total failure of the network.
With these facts in mind, we used a distributed election algorithm to select the appropriate successor to the dead master. Election algorithms are widely used to select a coordinator process in parallel and distributed computing. Initially, we tried the “Bully Election” algorithm. (See Resources.) This suffers from a handicap in that when a failed master is fixed and brought back into the network, it bullies the already-established master into handing over services. This creates an unnecessary switchover and results in loss of newer and updated data, besides causing network delay. The data loss occurs because updates may have been made in the new master machine, and when the original crashed master revives, it does not have the updated data.
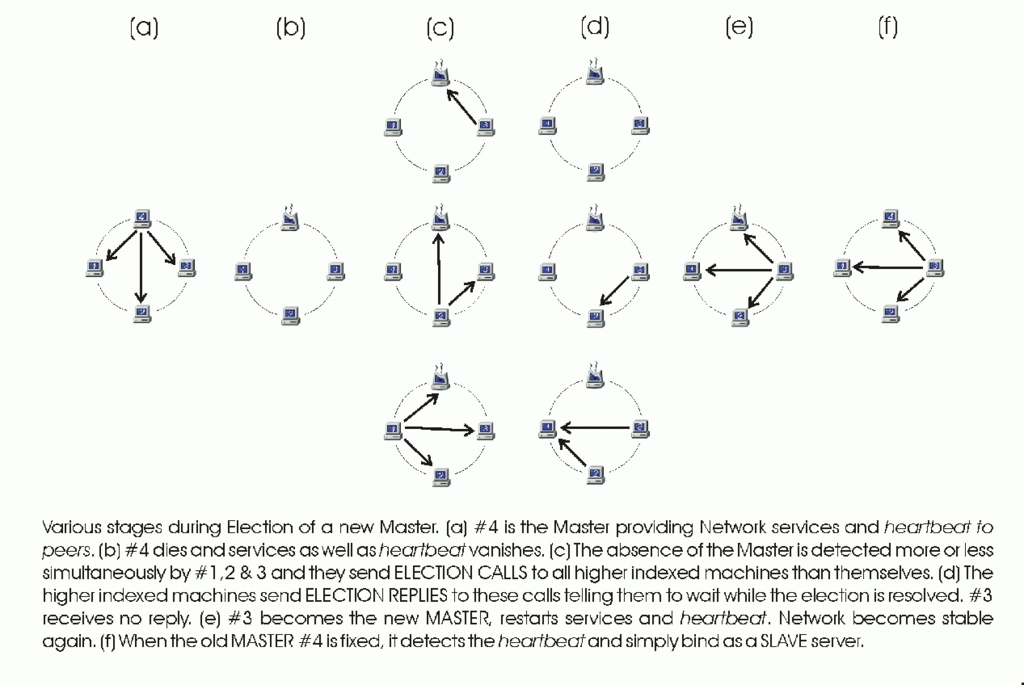
Figure 1. Election Algorithm
The “Modified Bully Election” algorithm is our modification of the basic Bully Election algorithm. Assume a stable network in which an array of servers is available. One of these machines is acting as the master machine and providing services to the network. The master server also multicasts a “heartbeat” signal to all slaves, apprising them of its existence. All the machines are assigned a performance index number. This number depends on various parameters such as processor speed, availability of latest data, available resources, etc. It may be dynamically assigned at each election, or in the simplest case, is an IP address. The higher the sequence number of a machine, the more it is suitable to act as the master server.
Now, assume a fault occurs, causing the master to crash. The rest of the machines detect its failure from the absence of the heartbeat and move into the election state. In this state, a machine sends election calls to all those with a higher index number than it has. If a higher-indexed machine is available, it will reply to this election call. On receiving an election reply, the machine moves into a “bind-wait” state. If a machine in election state receives no reply within a specified amount of time, it concludes that it has the highest index number. It then moves into “init” state. In this state, it starts the interrupted network services and resumes the heartbeat signal. It also sends a bind signal to other machines, moving them into slave state. Finally, it moves itself into master state, and the network becomes stable again.
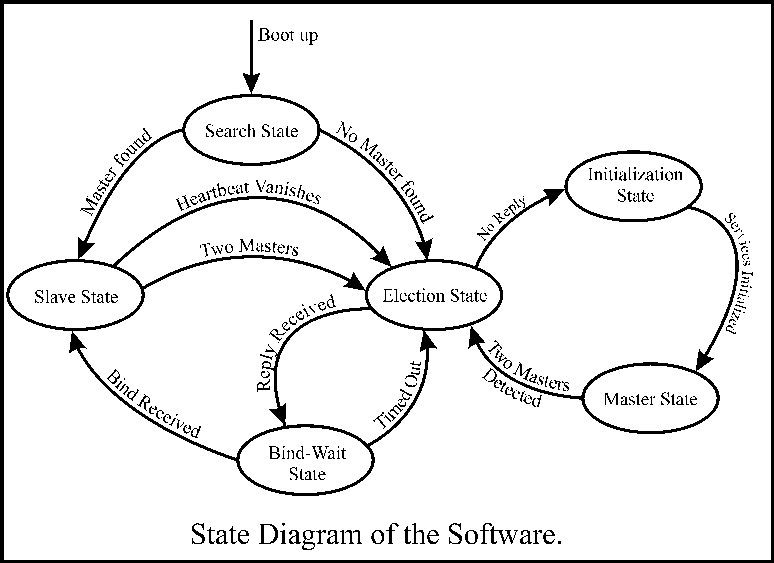
Figure 2. State Diagram
After receiving election replies, if the lower-numbered machines are unable to reach the slave state within a specified time, the election is timed out and restarted. Hence, this distributed process will elect a master under any sequence of failure. If the failed master is now fixed and brought up again, it will not initiate an election. In fact, it starts by listening to the heartbeat. If a master is found, it simply moves to slave state until the next failure occurs.
Our modification of the original Bully Election algorithm is that the computer with the highest index number is not necessarily the master at all times. In the original algorithm, a higher-index-number machine will always call for re-election and take control whenever it appears, regardless of the state of the network. In our case, this bullying procedure was found to be impractical for actual implementation. We implemented a variation, such that a stable network with a master will not be disturbed when a higher-indexed computer revives. It detects the presence of a master during startup, and on finding one, moves into slave state. Only if a new election is initiated will the highest-indexed machine take over. The current master is always the winner of the most recent election, and thus of the highest-indexed machine alive at that time but not necessarily at the current time.
A direct consequence of not including the bullying part in the election algorithm is the possibility of the existence of two masters. As we are relying on the master to take control of a key IP address as virtual server, two masters are simply unacceptable. Such a problem may occur when a master is isolated due to network congestion, the other machines conclude it dead and elect another master. As the congestion resolves and the original master reappears, there will be two masters. A very simple technique to overcome this is that all machines monitor the source of the heartbeat signal. If it is not found to be unique, a re-election is done, resulting in a single master once again.
By following this algorithm, we are able to facilitate the infallible presence of a working master server on the network. Since it is a distributed implementation, failure of any single component does not affect the election. Hence, various services can be continuously provided to the network.
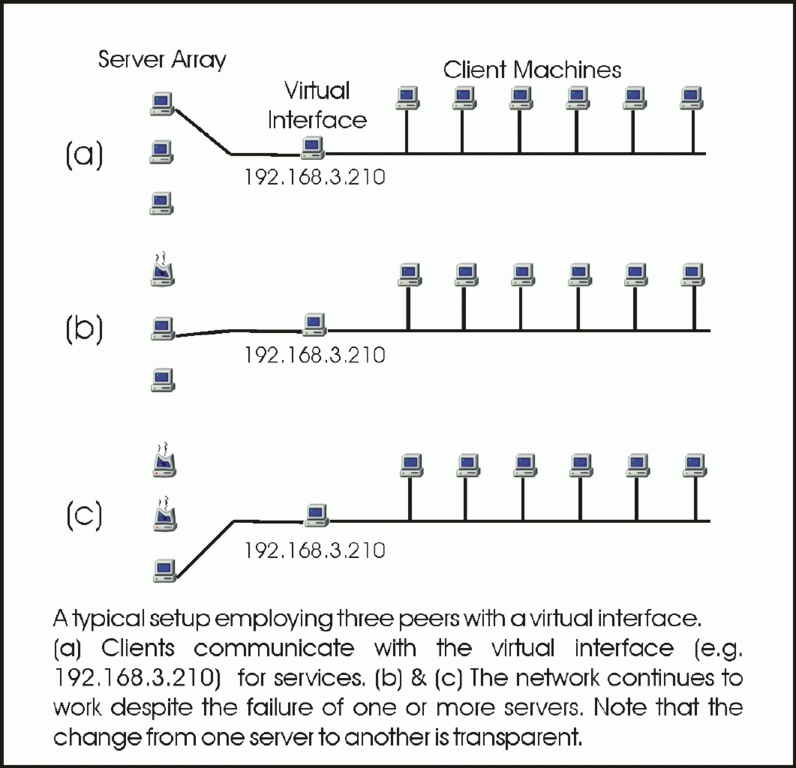
Figure 3. Virtual Server Diagram
The election process elects a master, but we are still far from making this change of masters transparent at the client end. In order to achieve transparency, we choose an arbitrary IP address henceforth referred to as the virtual server address. This address is not that of a machine in the cluster, but a separate one. All the clients are configured to use the virtual server address for requesting services. Whenever a machine becomes master, it takes over the virtual server address and continues with its original. IP aliasing is used to achieve this, i.e., assigning more than one IP address to a single network adapter. The new master then starts providing the network services previously provided by the failed master. Thus, the virtual server is always available, powered by any of the machines taking part in the election process. Since the clients always communicate with the virtual server, the proceedings of the fault-tolerance algorithm remain invisible to them.
The newly elected master server quietly takes over the virtual server address. However, the clients already have an address resolution protocol (ARP) cache entry connecting the virtual server IP address to the machine address (MAC) of the failed master. This cache would inhibit a client from communicating with the newer master, because the client would still try to communicate with the old MAC address. One solution which overcomes this problem is having an arbitrary MAC address be selected and taken over by elected masters. The problem with this approach is that not all network adapters support this function. Another solution would be to bluntly dump the ARP cache of all the clients and then reset the cache, which is also not an efficient technique.
The method we devised is to delete the virtual server IP address entry in the ARP cache of the newly elected master. Now the master automatically tries to update its ARP cache. In this process, it contacts the machines on the network, clients as well as slave servers. This not only updates the master's ARP cache, but also that of the clients. The advantage of this technique is that our software does not have to send special update packets to each computer—the already-working ARP mechanism does that for us.
Updating the ARP cache, followed by the IP address takeover, transparently causes the client to request services from the newly elected master. The clients may experience some delay while the actual election takes place, but other than that, they continue uninterrupted.
A very critical perspective of the whole switchover scenario is that the machines should be maintained identically. Only then will the switchover become truly transparent. Steps must be taken to ensure that in the event of a failure, the likely new masters would have as much updated data as possible. Two important aspects of maintaining the peers are time and file synchronization.
Important and critical files need to be circulated on all the servers. Any server could have been a master, and might have newer versions of files. Thus, it becomes imperative that the servers be time synchronized, so that their file timestamps are comparable. This ensures that only the updated versions are distributed at the time of file synchronization. An important thing to note is that the time does not have to be matched with the real time. The only requirement is that all the servers have the same time. We relied on simply setting the clock to the time of the master server, using a remote shell procedure. No special time servers were used, although running NTPD or TIMED would have been a better technique.
Another important task in maintaining peers is performing synchronization and replication of data over the entire array of servers in order to keep them consistently identical. The replication process is time consuming and often congests the network. The frequency of replication should be high enough to accommodate replacement transparency and minimize data losses during switchovers, while simultaneously low enough to allow proper network operation without undue congestion.
In a very dynamic scenario, it may not be possible to continuously distribute the updates on all machines taking part in an election. In such a situation, a switchover may cause a retrograde to the last synchronized version of files. Typically, the synchronization is scheduled during low workload hours. Additionally, instead of making backups, data is now distributed to the server array which better serves the purpose.
Having discussed various necessary aspects of the software solution, we move on to its description. We implemented this solution using Perl 5.0 running on Red Hat Linux 6.0. Owing to the portability of Perl, the software runs on any version of Linux/UNIX with minor or no changes. The program is implemented as a daemon that is initiated at startup of the servers. It moves to the background after spawning four processes:
Heartbeat listener process for processing heartbeat signals generated by the master server.
Listener process for receiving and parsing various signals generated from other servers.
Doctor process to interpret the heartbeat signal and decide whether the master server has failed.
Elector process to actually implement the election algorithm and decide which actions need to be taken. It also generates a heartbeat signal if running on a master server.
The main daemon is supplemented with special scripts to handle startup and synchronization. Separate scripts are created for master and slave servers. This makes the configuration of startup services on both master and slave servers very easy.
Besides subordinate scripts, a host of scripts is provided for file synchronization and distribution. They may be initiated for scheduled synchronization and backup.
We employed UDP communication for heartbeat signals in order to minimize network load. For election calls and other signals, TCP is used to ensure reliability.
If unchecked, any alien machine can generate an election call and the servers will move into an unwanted election state. For this reason, security and integrity of the signals exchanged between servers is highly stressed. We have implemented three levels of security for safe operation.
Level 1: a list of all servers taking part in the election is maintained at all servers. Only signals from these machines are accepted; all other messages related to the election process are discarded.
Level 2: the servers are state-oriented. That is, they acquire certain states, e.g., election state, master state, etc. In every state, some signals are anticipated and only these are accepted. Any other signal received, even originating from listed servers, is discarded.
Level 3: an encryption scheme is used to encrypt all the signals. A random key is created for encryption and is valid for only one message. Therefore, even if a signal is intercepted and cracked, the encryption key will not be valid at any other time.
For our implementation, we empirically found that weekly synchronization of large data suffices, while the password databases are replicated on every election. Other scenarios may require a more frequent synchronization.
The level of reliability and fault tolerance of the cluster increases in proportion to the size of the cluster. Increasing the number of servers increases the maintenance time for synchronization and unduly lengthens the election process. In our situation, we determined from experimenting that three to four servers are enough to guarantee a practical working solution.
On average, the slave servers are negligibly loaded, while the master servers are not loaded for more than 0.1% of the CPU usage. Network load is also very low, except during heavy synchronization, which is therefore run as a scheduled process.
Our test bed for this implementation is the Digital Computer Laboratory, UET, Lahore, Pakistan. The lab consists of 10 Pentium-based servers and 60 diskless workstations connected by 10MBps Ethernet.
There is a need for development and implementation of techniques that provide for an immediate synchronization. One method could be that whenever a file is updated, all the servers update their versions of the file. In this way, all data on all servers at all times is perfectly synchronized, thus eliminating heavy network/server loads during scheduled synchronization.
This technique is a practical and feasible implementation of fault tolerance for low-budget LANs running open-source operating systems, such as in developing countries and resource-scarce academic institutions where expensive commercial solutions are just that—expensive.

Jahangir Hasan is a final-year student of EE-Communication Systems at UET, Lahore, Pakistan.
Kamran Khalid is a final-year student of EE-Communication Systems at UET, Lahore, Pakistan.
Farhan-ud-din Mirza is a final-year student of EE-Communication Systems at UET, Lahore, Pakistan.

