
Three-Tier Architecture
In the beginning, there were mainframes. Every program and piece of data was stored in a single almighty machine. Users could access this centralized computer only by means of dumb terminals. (See Figure 1.)

Figure 1. Mainframe Architecture
In the 1980s, the arrival of inexpensive network-connected PCs produced the popular two-tier client-server architecture. In this architecture, there is an application running in the client machine which interacts with the server—most commonly, a database management system (see Figure 2). Typically, the client application, also known as a fat client, contained some or all of the presentation logic (user interface), the application navigation, the business rules and the database access. Every time the business rules were modified, the client application had to be changed, tested and redistributed, even when the user interface remained intact. In order to minimize the impact of business logic alteration within client applications, the presentation logic must be separated from the business rules. This separation becomes the fundamental principle in the three-tier architecture.

Figure 2. Two-Tier Client-Server Architecture
In a three-tier architecture (also known as a multi-tier architecture), there are three or more interacting tiers, each with its own specific responsibilities (see Figure 3):
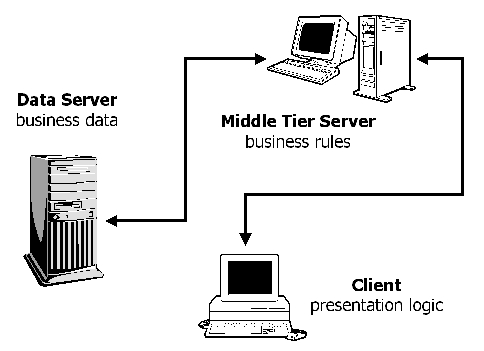
Figure 3. Three-Tier Architecture
Tier 1: the client contains the presentation logic, including simple control and user input validation. This application is also known as a thin client.
Tier 2: the middle tier is also known as the application server, which provides the business processes logic and the data access.
Tier 3: the data server provides the business data.
These are some of the advantages of a three-tier architecture:
It is easier to modify or replace any tier without affecting the other tiers.
Separating the application and database functionality means better load balancing.
Adequate security policies can be enforced within the server tiers without hindering the clients.
In order to demonstrate these design concepts, the general outline of a simple three-tier “Hangman” game will be presented (check the source code in the archive file). The purpose of this game, just in case the reader isn't familiar with it, is to try to guess a mystery word, one letter at a time, before making a certain number of mistakes.
Figure 4. Hangman Client Running in Windows 98
The data server is a Linux box running the MiniSQL database management system. The database is used to store the mystery words. At the beginning of each game, one of these words is randomly selected.
At the client side, a Java applet contained in a web page (originally obtained from a web server) is responsible for the application's graphical user interface (see Figure 4). The client platform may be any computer with a web browser that supports applets. The game's logic is not controlled by the applet; that's the middle tier's job. The client only takes care of the presentation logic: getting the user's input, performing some simple checking and drawing the resulting output.
The server in the middle tier is a Java application, also running within a Linux box. The rules of the “Hangman” game (the business rules) are coded in this tier. Sockets and JDBC, respectively, are used to communicate with the client and the data server through TCP/IP.
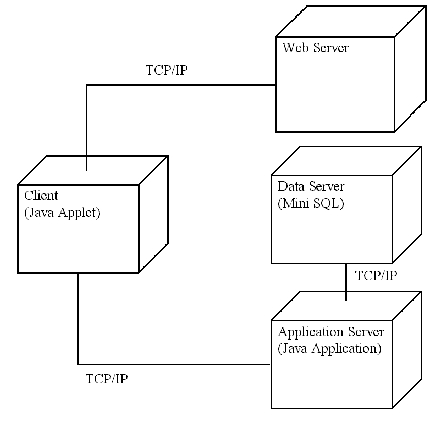
Figure 5. Diagram of Hardware Nodes
Figure 5 presents a UML (Unified Modeling Language) deployment diagram that shows the physical relationship among the hardware nodes of the system.
Even though the design described gives the impression of requiring a different machine for each tier, all tiers (each one running on a different process) can be run in the same computer. This means the complete application is able to run in a single Linux system with a graphical desktop, and it doesn't even have to be connected to the Net!
MiniSQL, developed by Hughes Technologies, is an exceptionally fast DBMS with very low system requirements. It supports a fairly useful subset of the Structured Query Language (SQL). Using it for commercial purposes requires purchasing a license, although free licenses are provided for academic and charity organizations.
The software is distributed in source code form, all bundled up in a gzipped tar file (currently, the latest distribution file is msql-2.0.11.tar.gz). It may be downloaded from the Hughes Technology web site (see Resources). The MiniSQL manual, with all the necessary installation and usage information, is contained in the files msql-2.0.11/doc/manual.ps.gz and msql- 2.0.11/doc/manual-html/manual.html, once the distribution file is extracted. The reader is encouraged to carefully review and follow the instructions contained there. However, it must be noted that two important details are missing from the MiniSQL manual:
The “system” section contained in the /usr/local/Hughes/msql.conf file has a parameter called Remote_Access that has a default value of false. It must be changed to true in order to allow access to the database from remote systems.
Like other server dæmons (for example, the HTTP web server), the MiniSQL 2.0 server, called msql2d, should be run as a background process. Executing the following command as root should achieve this: /usr/local/Hughes/bin/msql2d &
In addition to the database server, MiniSQL comes with some other useful utilities: a server administration program, an interactive SQL monitor, a schema viewer, a data dumper and a table-data exporter and importer. The server administration program is required to create the Hangman database that will contain the mystery words. The following command must be executed as root:
/usr/local/Hughes/bin/msqladmin create hangmanAfterward, a mystery-words table needs to be created. Only two columns will be contained in this table: word (the mystery word or sentence) and category (a classification for the mystery word: computers, animals, movies, etc.), both of them being character strings. Also, a few rows should be inserted. The interactive SQL monitor may be used for both purposes. Executing the command
/usr/local/Hughes/bin/msql hangmanenters the interactive monitor with the “hangman” database. The MiniSQL prompt should appear. SQL queries can now be issued, followed by “\g”(GO) to indicate that the query should be sent to the database server. Here are the SQL commands for the Hangman application:
create table mystery (word char(40), category char(15))\g
insert into mystery values ('elephant', 'animals')\g
insert into mystery values ('rhinoceros', 'animals')\g
insert into mystery values ('gone with the wind', 'movies')\g
The application's middle tier uses Blackdown's Linux Port Java Development Kit 1.2.2, release candidate 4, and CIE's mSQL-JDBC driver for JDBC 2.0. The Java tutorial is one of many excellent places to learn how to access databases from within a Java program; that's why only the specific issues on accessing MiniSQL will be dealt with here.
Before attempting to access the MiniSQL server from a Java application, the corresponding JDBC driver must be installed. The driver may be freely downloaded from The Center for Imaginary Environments web site (see Resources). The distribution file comes with many things, but the most important part is the JAR file that contains the driver itself (currently, the file is msql-jdbc-2.0b5.jar). The easiest way to install the driver is to copy the JAR file to the /usr/local/jdk1.2.2/jre/lib/ext directory (root privileges are required to copy files to this directory).
In order to load the driver from the Java program, the following statement should be executed:
Class.forName("com.imaginary.sql.msql.MsqlDriver");
The connection to the database server is established when executing this statement (ignore line wrap):
Connection con = DriverManager.getConnection
('jdbc:msql://localhost:1114/hangman');
Inside the JDBC URL, the URL of a remote system should replace
“localhost” if the MiniSQL server is not running in the same
machine. 1114 is the default port number to which the MiniSQL
server is listening. The msql.conf file can be modified in order to
specify another port number.
The three-tier architecture is a versatile and modular infrastructure intended to improve usability, flexibility, interoperability and scalability. Linux, Java and MiniSQL result in an interesting combination for learning how to build three-tier architecture systems. Nevertheless, more convenient implementations than the one presented here may be produced using component technology in the middle tier, such as CORBA (Common Object Request Broker Architecture), EJB (Enterprise Java Beans) and DCOM (Distributed Component Object Model). The interested reader should review these topics to get a better understanding of the current three-tier architecture capabilities.

Ariel Ortiz Ramirez (aortiz@campus.cem.itesm.mx) is a faculty member in the Computer Science Department of the Monterey Institute of Technology and Higher Education, Campus Estado de Mexico. Although he has taught several different programming languages for almost a decade, he personally has much more fun when programming in Scheme and Java (in that order). He can be reached at aortiz@campus.cem.itesm.mx.
