
Flight Simulators
Have you ever wondered how full-flight simulators and CATS (computer-aided training systems, Figure 1) are made? The answer, as one might expect, is that they are made with a lot of high-tech hardware and a million lines of code. It is a true marvel of technology where hardware and software meet to produce some of the most incredibly realistic simulations in the world today. Full-flight simulators are based on three principles: visuals, sound and motion. Using these three basic concepts, we are able to produce the most sophisticated flight simulators in the world. A full-flight simulator is an invaluable training tool for helping a pilot acquire the necessary skills and abilities to react to unpredictable situations.
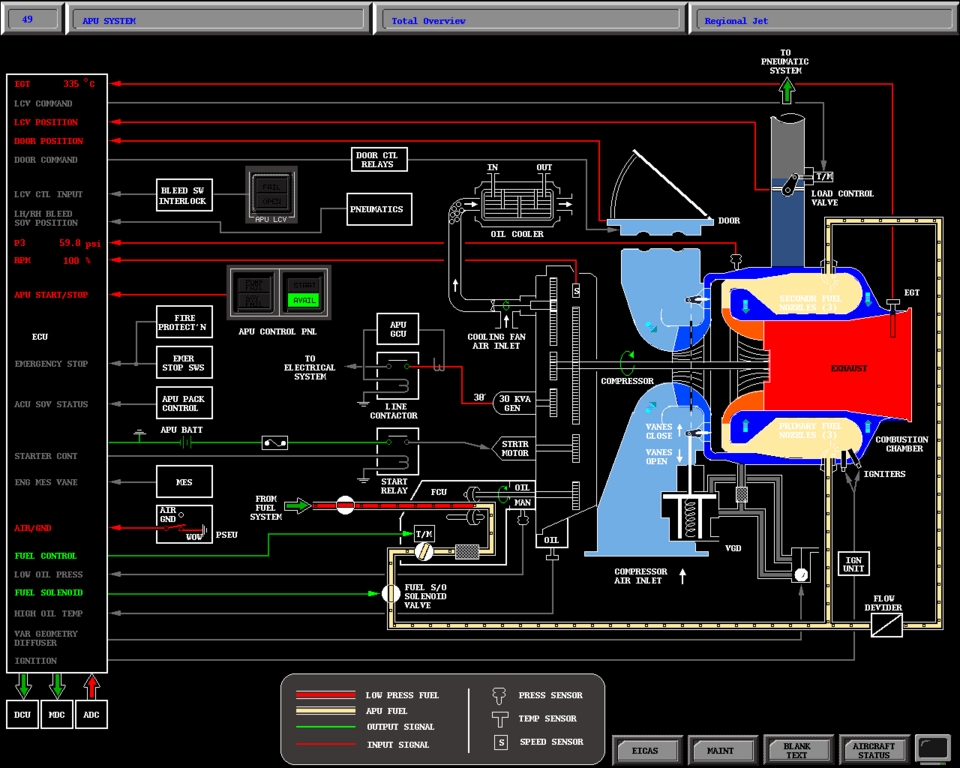
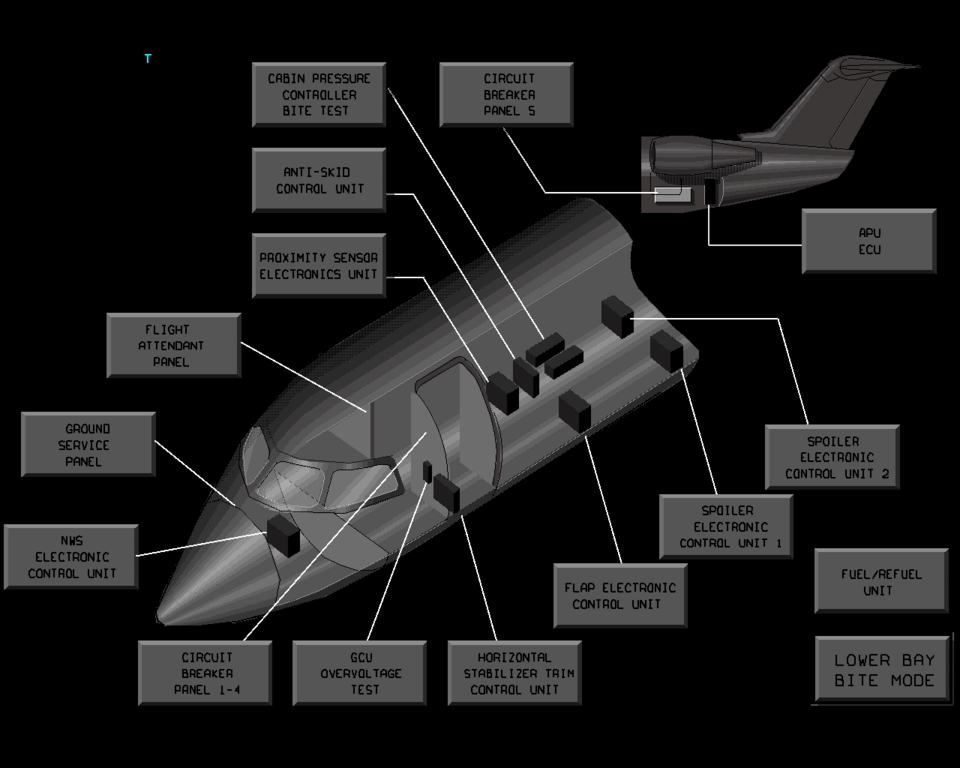
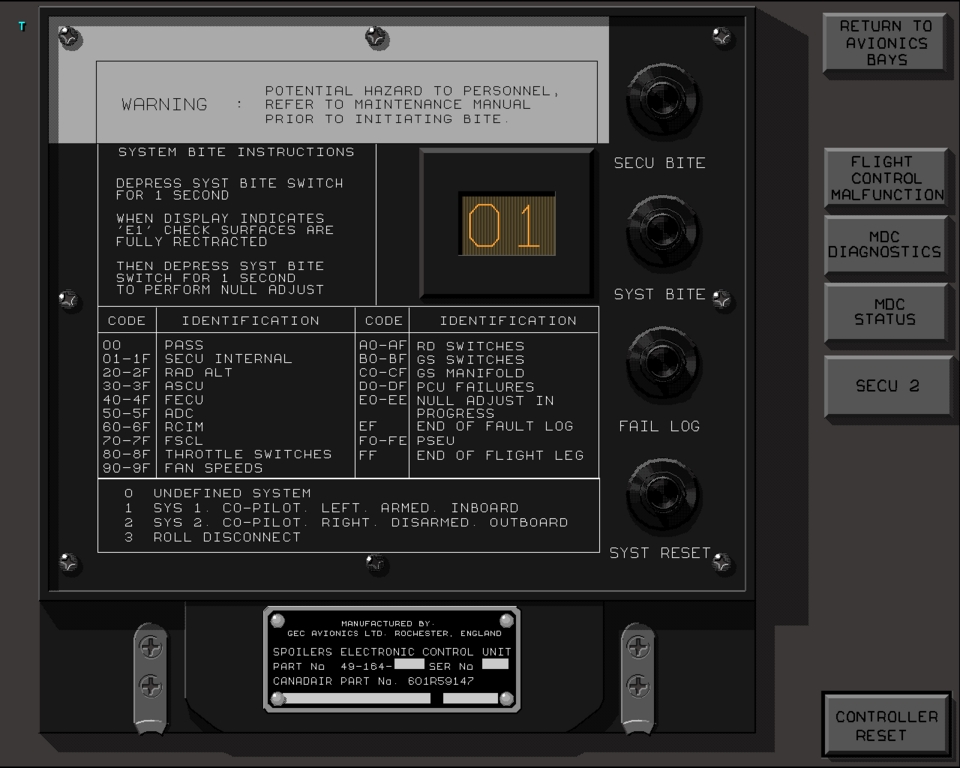
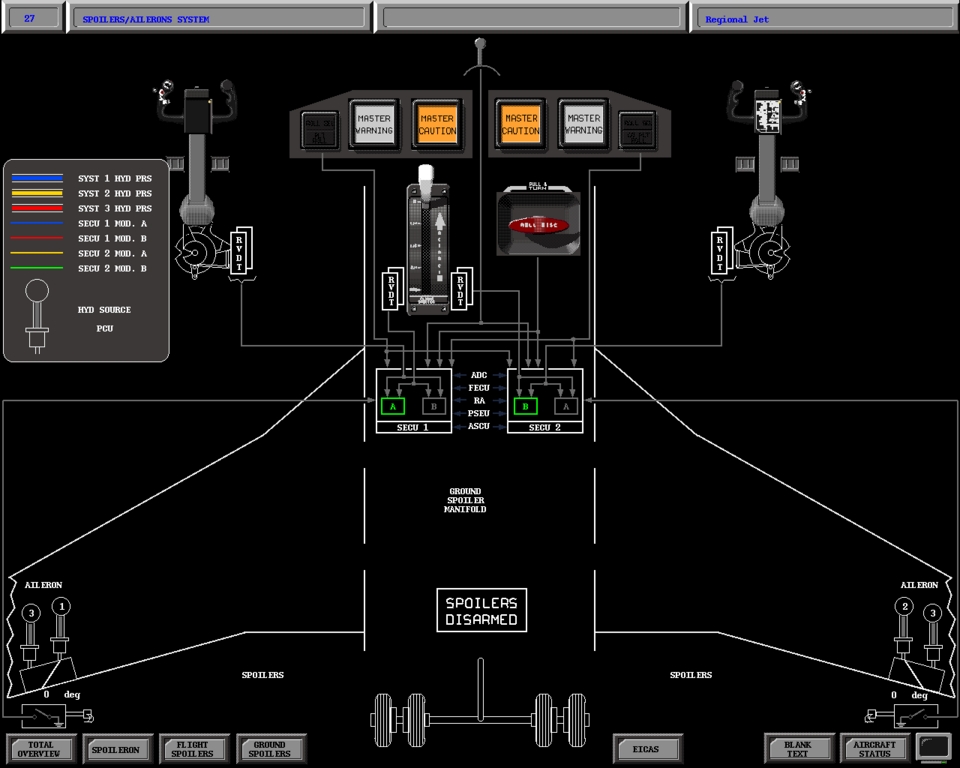
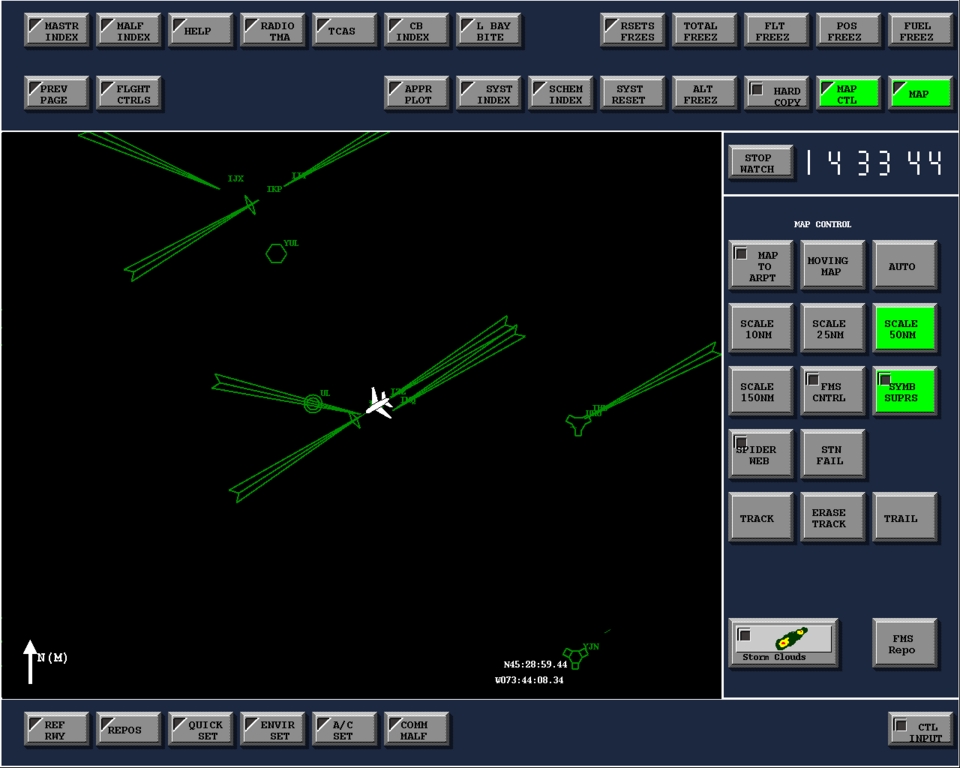
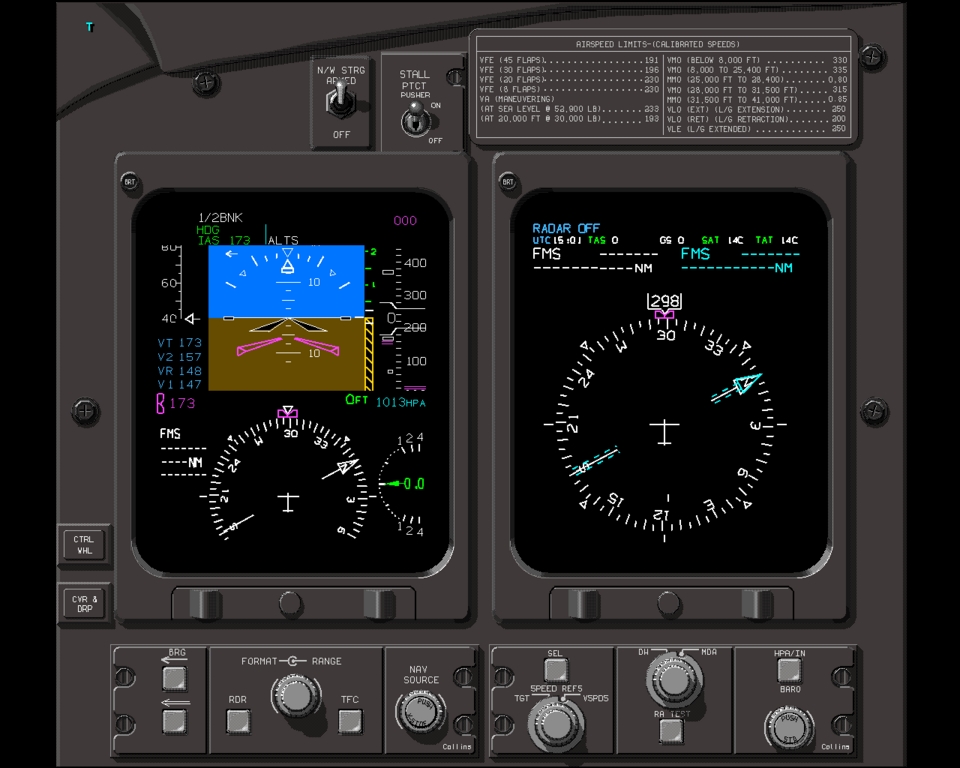
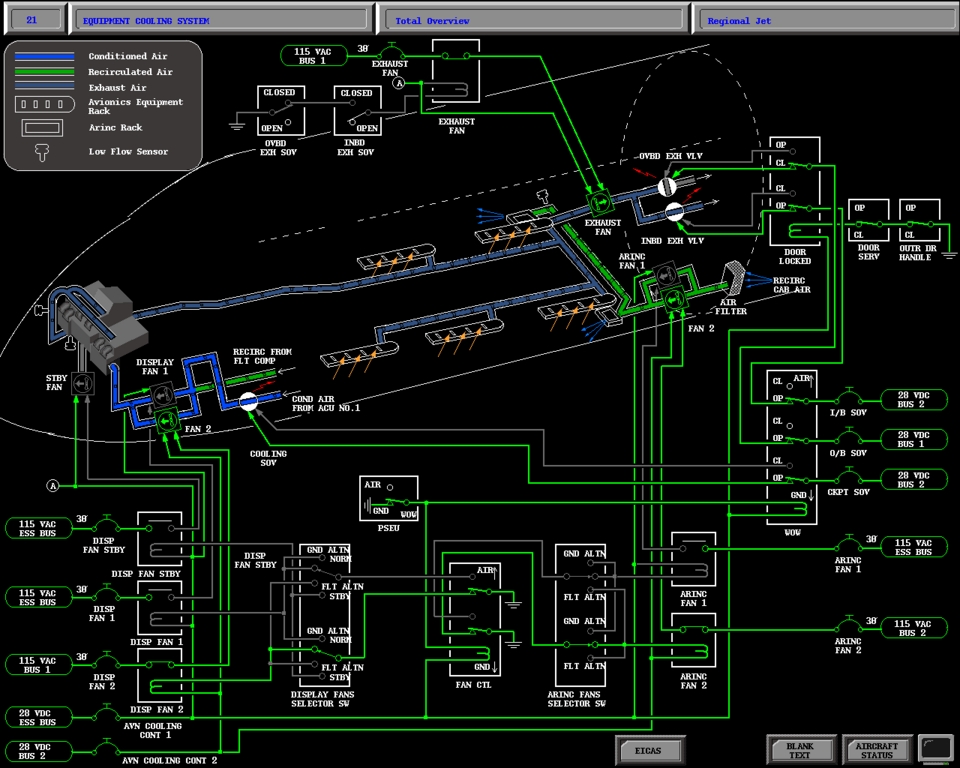
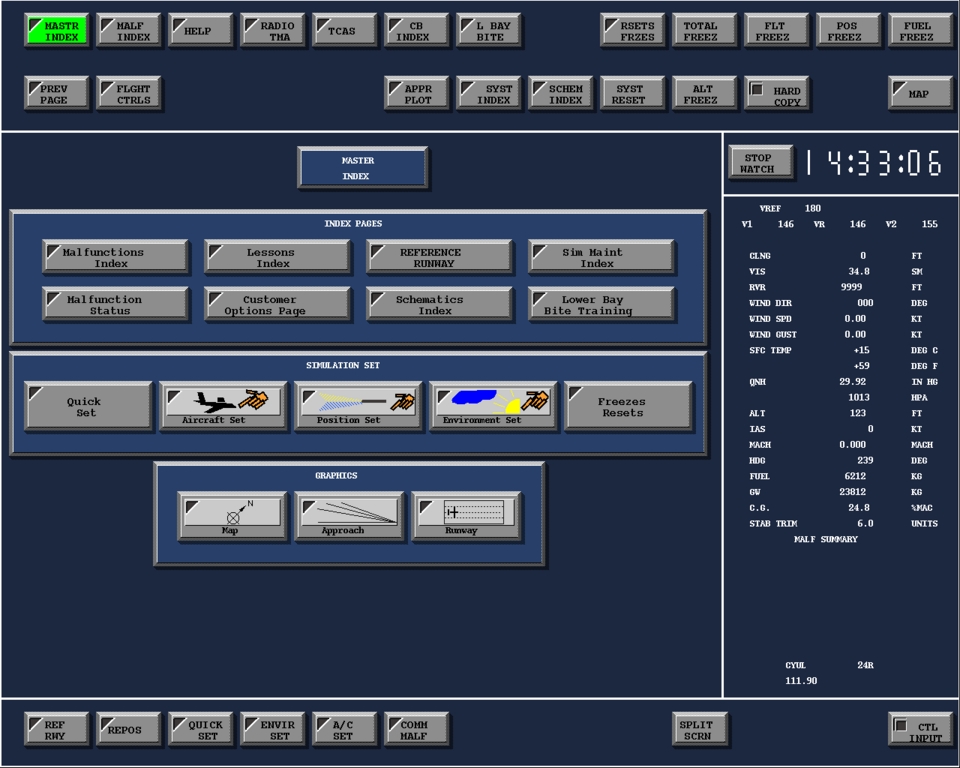
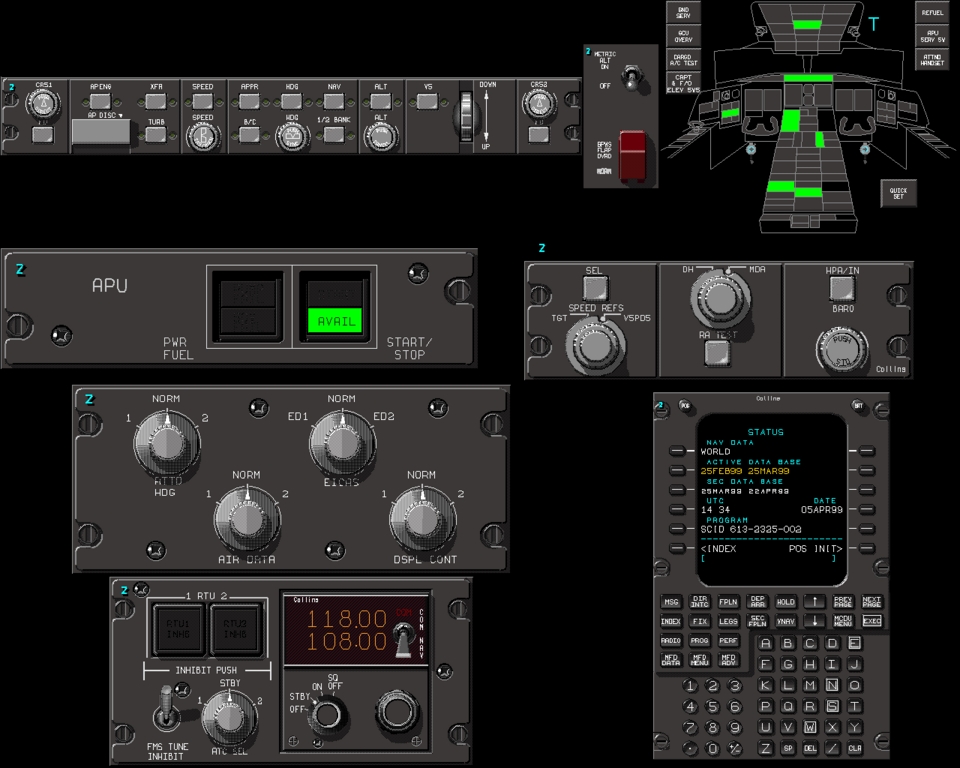
Full-flight simulators (Figure 2) are built with a complex and effective six-degrees-of-freedom motion system. This motion system is responsible for producing the realistic feeling of takeoff, landing and in-flight turbulence. The visual projectors generate the real-world images as visual references. The heart of the entire system is the host computer, which is responsible for interacting with all the avionics hardware, motion and visual systems as well as simulating the aircraft's aerodynamics. CATS are a different breed of aircraft simulation. Instead of defining a hardware interface to interact with all the aircraft panels, CATS produce a graphical representation of all the aircraft panels (Figure 3), schematics (Figure 4), Line Replaceable Units (LRUs, Figure 5), and black boxes as they are sometimes called (Figure 6). By contrast, CATS provide a quite useful tool for training aircraft maintenance personnel involved, as well as pilots. They are also invaluable as a diagnostic tool for maintenance personnel in troubleshooting and diagnosing aircraft system failures. CATS are available in three configurations: single-screen (mini-CATS, Figure 7), three-screen (CATS, Figure 1), and seven-screen (CATS System Trainer, Figure 8). This last one is a full graphical representation of the aircraft cockpit with touch-sensitive screens. This system provides the entry-level pilot and/or aircraft maintenance personnel an opportunity to master his cockpit procedural skills.
Figure 1. Computer-Aided Training Systems
What kinds of software and computing power are required to produce the realism required for flight simulation? Until not too long ago, this field has been the playground for big players in the industry such as IBM, Digital VAX/VMS and Gould. Today, with powerful CPUs being commonplace and mainframes almost obsolete, Intel has just about dominated the marketplace.
The company I work for (CAE Electronics Inc., Montréal, Quebec, Canada) employs 4000 people, half of whom are software engineers in the simulation hardware and software domain. Speaking objectively, I am proud to say that CAE Electronics builds the most technologically advanced full-flight simulators in the world today. It is up to CAE engineers to come up with new technologies in software simulation, both with respect to the CPU hardware and the OS required to produce quality products for our customers. Linux can be used as a dependable and reliable platform for commercial flight simulation software in the airline industry.
CAE has always been a company that believed in building its own software tools and basic software development environment. For the last nine years, CAE has been an IBM AIX RS/6000 house. IBM has been our foundation for building a stable platform under AIX to run thousands of software modules in a real-time environment, a tough task for Linux to undertake. In the last four years, however, Linux has been used as a basic development platform for CAE engineers requiring a complete simulation environment.
Figure 3. Aircraft Panels Representation
Can Linux be used to develop CAE commercial software simulation systems? Yes. Linux has matured a great deal in the last couple of years. With that in mind, CAE engineering has been instrumental in supporting Linux. Will our customers react favorably to Linux? Will the Linux community support the product in the years to come? Both are serious questions. Full-flight simulators are a long-term investment for our customers. These and many other questions must be answered before we can fully commit and support future Linux development. Current industry trends show Linux being supported more and more by companies such as IBM, H-P, Compaq and Dell. The future for Linux looks bright.
Our basic principles in software simulation are simple. We produce C code in straight-line execution within a CAE software environment called SIMEX (simulator executable). This environment provides the basic software dispatcher required in controlling software module execution in a real-time environment. SIMEX also provides software configuration control under RCS to maintain multiple configurations for testing and integration. SIMEX is capable of building different executables for runtime execution from a collection of different source modules. This provides an invaluable environment for the engineers to test new software code without destroying the previous working configuration.
Since AIX is a non-real-time OS, the question arises as to how one would create a real-time environment on a non-real-time OS. The answer is simple: produce your own library of asynchronous I/O control functions that the software engineer will require for all I/O system calls. Setting the system priority of the software dispatcher code to the highest level is not enough to create a real-time environment. All simulation I/O requests must be handled in an asynchronous manner in order to maintain a real-time simulation environment. We call this environment CAELIB (CAE Library).
The software dispatcher is also required to control the sequence and duration of software module execution so as not to allow any overruns to occur. This technique is called banding. Software banding enables the software dispatcher to control the time required to execute a collection of software modules as well as the sequence of code executions. Certain modules need to run before others in order to maintain aircraft system simulation integrity. This allows all modules ample opportunity to execute in the allotted time. For real-time simulation, this is 60 Hertz or 16.66 milliseconds for one full pass for all software modules. The software dispatcher then further breaks the banding down into legs, which are executed in a controlled state.
Figure 5. Line Replaceable Units
Not all modules need to be executed at a rate of 60 Hertz. Most aircraft systems need to be executed at only a third or even a quarter of a second. For this reason, the software dispatcher calls certain modules at an iteration rate of 16.66, 33, 66, 133 or 266 milliseconds. The CAE engineer enters his/her module into a dispatch table. This, in turn, instructs the software dispatcher code to execute and sequence as per the engineer's request. If there are too many modules in one particular leg and the code is unable to complete execution within the allotted time, the software dispatcher will terminate the execution of the code and continue onto the next leg for execution.
This situation is called a software overrun. In order to control software overruns, the integration specialist and software engineer redistribute the software modules into less heavily weighted bands that have excess execution time. This allows critical modules ample time to execute, while non-critical modules are executed at a slower iteration rate. Since all our code is based on legacy FORTRAN 77 and ANSI C, porting our code to a Linux PC platform proved to be a relatively straightforward task, except, of course, accounting for the obvious differences between Linux and AIX compilers. (More to follow on that subject.)
The software simulation configuration discussed in this article was a Bombardier/Canadair Regional Jet RJ-200 aircraft (Figure 9), a successful 50-seat twin jet regional aircraft manufactured and built by Bombardier Aerospace in Montréal and popular with airlines such as Comair, Skywest and Air Canada, just to name a few. The first task at hand for CAE engineers was to port the entire CAELIB and SIMEX software environment to Linux. This proved to be a relatively uncomplicated task for our operating system support group (OSU), since most of our code is in ANSI C. All modules were compiled with relatively minor modifications. Once this was done, the task of transferring and porting the entire software simulation code from SIMEX to Linux proved to be more challenging. Now, I am referring to years of software development on AIX with at least 500 software modules, each ranging from 1,000 to over 100,000 lines of code—the porting of which would be no trivial matter. The third task was to port the required CAE-specific compilers from our own OpenGL-based graphics compiler and editor to our basic support utilities. CAE has developed its own graphical environment called TIGERS (an OpenGL-based system).
At the time TIGERS was developed at CAE, sophisticated graphic systems for simulation use were not yet commonplace. Figures 10, 11, 12, 13 and 14 show the level of graphical detail required for CATS simulation. The main difference between a CATS and a full-flight simulator is simple: CATS requires that all aircraft panels be a graphical representation, as opposed to the hardware-driven interface on a full-flight simulator. Simply put, a graphical representation of a switch is used instead of a real switch in a cockpit environment. In all respects, the amount of simulation software required is much more complex on a CATS as opposed to a real full-flight simulator. All aircraft systems are simulated in the CATS environment, instead of only the simulated black boxes of the full-flight simulator. In flight simulators, we simulate the same black boxes as used on the aircraft. In trying to address the needs of a Bombardier's training department as they sought a portable version of their existing AIX CATS on the PC platform, CAE engineering decided Linux would be the ideal and practical choice for this project.
Figure 8. Seven-Screen CATS System Trainer
We made the decision to use the standard GNU ANSI C compiler and F77 translator for the task. Our FORTRAN77 legacy software modules proved to be the greatest challenge. AIX FORTRAN77 compilers are very forgiving in equating logical to integer data types. For example, if you equate an integer label to a logical label, the AIX FORTRAN compiler would assume you require the value in the logical label to be stored into the integer label. This style of programming is not allowed under F77 Linux. You must declare and equate labels of the same data type, or the compilation will fail. Now, this would be a simple task if the labels were defined in the local module. The problem arises when the software module in question uses a logical label declared in what we call our CDB (common data block) as an integer label. This common data block is used to declare all global labels used by every simulation module to pass variables among each other. If the declaration is wrong in the CDB, a correction must be made in all modules. Then each module must be reprocessed with the new CDB and recompiled.
Figure 9. Bombardier/Canadair Regional Jet RJ-200
The next problem lies with the memory storage format of logical labels between AIX and Linux. For example, a data type of Logical*4 (four bytes) in F77 Linux is stored from left to right (MSB, most significant bit, to LSB, least significant bit) while AIX stores the logical in reverse order (LSB to MSB). This can create a major problem when using the logical in a bit manipulation operation. If you use each bit for a different function in your code and apply a bit manipulation operation (e.g., FECDE .XOR. Logical Label), then the problems are compounded. You must reverse all masks used in the bit manipulation operation—a considerable amount of work.
Figure 10. CATS Simulation Detail
Another area of concern is the data files used to store navigation and engine data interpolation information. The byte order in these data files must also be reversed to read data correctly into their assigned CDB labels. Our ANSI C code does not have this problem. Most of the C code compiled with relatively little change.
Figure 11. CATS Simulation Detail
Aural warning system conversation required a minor amount of work. Under AIX, all audio warnings were designed to work with a DSP card with one large digital audio file. We were required to convert the large digital aural warnings data files into separate PCM wave files. A newly coded audio software module was then needed to cross-index the requested aural warnings to their corresponding wave file and pipe them to a standard SoundBlaster audio card. Throw in all the graphics files and IOS pages (Instructor Operator System Pages, Figure 15), and we have an enormous porting task.
Linux and CATS proved to be a good match. System reliability and performance met and exceeded our expectations with amazingly predictable results. CAE now has a full-blown aircraft simulation, with graphics and aural warnings, running in a Linux environment. Our Linux development environment consisted of a Pentium II Intel 350MHz CPU with 128MB of memory and a Toshiba 233 MMX Portege 320CT laptop with 32MB memory. As described previously, the CATS comes in three flavors: one-, three- and seven-screen versions. Under AIX CATS, the IBM host drives three separate X workstations, with each screen displaying different information. Under a single-screen configuration, one X workstation provides functionality for all graphics pages while using a cockpit navigational panel as shown in Figure 16. The top right-hand quick-reference panel is a small graphical representation of the aircraft cockpit. When one of the panels is selected, the system displays the selected panel in a designated portion of the single screen, with the seven-screen CATS being displayed on seven separate X workstations. Each displays a full graphical representation of all the aircraft panels (Forward, Overhead, Pedestal and Side panels, Figure 8). With Linux, the hardware configuration is a bit different. The graphics display is the same (one-, three- or seven-screen configurations); the difference is in how and where we display the graphical pages. Under Linux, we use a graphics card called Evolution 4.
Figure 13. CATS Simulation Detail
This card is manufactured by Color Graphics Systems in the UK. It allows us to display four simultaneous X display outputs using Xi Graphics' Multi-Headed X server. AcceleratedX is an excellent product, allowing us to drive up to 16 X displays (using four Evolution 4 Video cards) simultaneously. The hardware cost is reduced significantly when compared to three IBM X workstations with an RS6000 IBM host CPU and a Linux PC with one Evolution 4 video card.
Figure 14. CATS Simulation Detail
In a MINI CATS version (single-screen configuration), we now have the option to install the CATS on a standard PC laptop using the Xfree86 X server included with every Linux distribution. Distribution and installation of CATS has also been addressed. Customers did not want to install a dedicated Linux system on a previously preloaded Microsoft operating system. So, we developed a CD-ROM that would boot into a Linux environment, set up a small virtual Linux file system in memory, and loaded all the required CAE CATS software without installing any software on the local hard disk. This also has proven to be successful. Bombardier can now distribute their CATS systems on a pre-configured bootable CD-ROM. Booting and loading CATS in the field now requires no previous knowledge of or experience in the Linux operating system—no more file corruption or accidental file deletions by the customer. The primary reason for developing PC-based CATS for Bombardier was cost and portability, portability being Bombardier's top priority for their training instructors in the field. All these factors translate into a more affordable CATS for Bombardier and their customers.
Figure 15. Instructor Operator System Pages
Figure 16. Cockpit Navigational Panel
Linux has proven without a doubt that it is a reliable and stable development platform for delivering commercial-grade simulation products to the airline training industry. CAE has recognized the potential in Linux and its potential in future CAE simulation products. CAE may even explore the possibility of running a full-flight simulator on Linux one day. Job well-done, Linus Torvalds.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}