
DSP Software Development
In this article, I describe a Linux success story based on researching and developing DSP (Digital Signal Processing) speech coding algorithms. I chose Linux over Windows for good reasons—reasons that may provide you with ammunition to persuade the bosses that Linux really does mean business. To emphasize this, I developed the software for the next generation of digital radio products in the headquarters of the world's largest private mobile radio manufacturer.
Luckily, I had an open-minded boss, but there were still difficulties. These included interoperability issues with existing systems, resource sharing, accessibility, documentation and the non-availability of some crucial software for Linux.
A typical project life cycle begins with university research and proceeds through initial investigation and prototyping, a complex coding route and various testing stages to a fully documented software package for passing on to system integrators.
My project was advanced speech processing software for fixed-point DSP. Bearing this in mind, audio capabilities topped the list of requirements for any development machine. Also needed were good mathematical processing and visualization software and a whole set of code-development tools. Finally, some DSP-specific software was required.
Given recorded speech files, research often involves processing and evaluating the changes by listening to them. For this, a sound card is useful, and with the availability of the OSS drivers, sound output is no problem for Linux. The easiest way to generate sound is to copy a sound data file to /dev/audio. Tradition specifies this data file should be in Sun's 8-bit logarithmic format, sampled at 8KHz. The command
cp audiofile.au /dev/audio
outputs sound, assuming everything is set up properly (see Resources for good audio information).
How do you get Sun format audio? The answer is to use sox (SOund eXchange). Its command-line options seem a bit unfriendly at first, but the following command converts a .wav file into a Sun format .au file:
sox audiofile.wav -t ul -r 8000 audiofile.au
Traditional processing is done by writing a C or similar program to read in the speech file, perform some processing and write the output either directly to /dev/audio (if the program can output the data in real time) or to a temporary file first (if it cannot). This works okay, but the compile-link-test-modify cycle can be too lengthy to permit efficient trial-and-error testing (sometimes called research).
One alternative is MATLAB, the excellent commercial mathematical manipulation package; however, I found an alternative with a GPL—Rlab. Although not promoted as a MATLAB clone, this high-quality suite of software is at least as usable, truly multi-platform and free. The range of built-in functions in Rlab is impressive and allows the seamless addition of user functions. Data can be imported/exported, processed and displayed graphically, as shown in Figure 1. See Resources for some useful additional Rlab functions, including an audio playback routine.
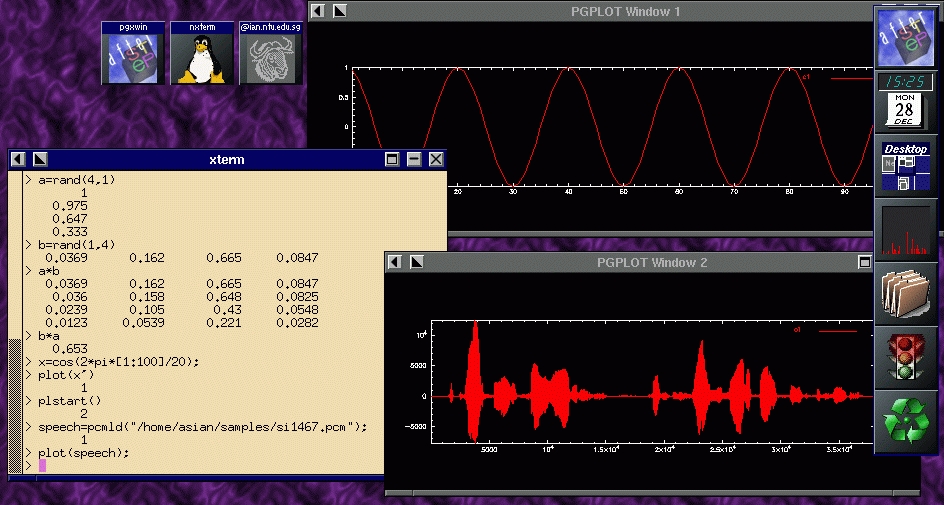
Figure 1. Using Rlab to Modify and Plot Speech Waveforms
All this gives us an ideal platform for speech algorithm research. We can listen to audio, make modifications and build up a library of speech processing routines to use in current and future investigations. The modifications can be tried and evaluated with little effort.
Now the algorithms found after playing with Rlab must be converted manually to DSP code. This isn't actually easy for a number of reasons: the Rlab code makes use of built-in library routines and is floating-point. The humble DSP is only fixed-point, so normally this conversion is done in three steps.
The first is to go directly from the Rlab script to C—replicating all the Rlab functions with C functions of the same name, which you write and test, and rewriting the glue code. This produces an executable that is bit-exact with the Rlab code, so halting or single-stepping the code with gdb can allow direct comparisons between the C and the Rlab script.
The second step is to replace all the floating-point variables and functions with fixed-point alternatives. For each data variable, we need to know maximum and minimum values and the effect of truncation, then truncate and scale appropriately.
For trigonometric functions, a number of established techniques such as approximation and table lookup may be used, but these can be difficult to code. It doesn't help that DSP memory is extremely limited and the law of code size applies (i.e., code size will expand until it's just larger than the available space).
However, fiddling with numbers can be good fun, and trying to write a fixed-point log function by hand may require a few more visits to Rlab in order to work out exactly what a logarithm does.
Eventually, a C program emerges that has no floating-point variables (use grep to make sure); other than scaling and truncation errors, it performs the same function as the original Rlab code. Again, gdb can be used to investigate execution. We can import array data to Rlab for plotting by selecting the data and dropping it into an Rlab script.
One trick is to write a C function that, when passed an array, prints the array formatted so that it can be selected and pasted into Rlab—code such as:
void rprint(int length, int *array) {
printf("\narray=[");
for (int i=0;i<length;i++)
printf("%d,",array[i]);
printf("\b];\nplot(array)\n"); }
When used frequently in the debugging cycle, this can be very effective.
The last point to mention under prototyping is the benefit of using some form of version control, or perhaps I should say the foolishness of not using it. Effective version control is one of the major reasons UNIX/Linux is a stable and capable development platform. We used RCS throughout the development process. In fact, the main RCS directory was on a Sun accessed via an NFS mount and shared by a number of developers working under Solaris.
Now comes the DSP involvement—for this a DSP starter kit is needed. For simple and easy development, two main contenders are available. Both have patchy support for Linux, cost in the region of £80 and are aimed at the hobbyist, small business or university user.
The original was from Texas Instruments, the TMS320C50 DSK (there was an earlier, less powerful C26 board), with the newer contender being the Analog Devices ADSP2181 EZ-KIT Lite. Both have audio I/O—the latter has 16-bit CD-quality stereo audio, while the former can manage only 14-bit voice quality. On the software side, both provide a nice set of DOS executables—assembler, linker and (for the Analog Devices kit) a simulator. The ADSP has an edge with its assembly language syntax being much more user-friendly than the TI chip. I won't stick my neck out too far and comment on which DSP is more powerful—both are fairly competent.
Linux versions of most DSP development tools are floating around on the Internet, but some are still missing, notably for the ADSP2181. These omissions are the assembler, linker and simulator, which is a pity since I had to use the ADSP.
The freely available cross-assembler as will soon include ADSP21xx compatibility. It already handles TMS320Cxx code along with a staggeringly wide array of other processors, with more added whenever the author, Alfred Arnold, has free time. Analog Devices have been approached about providing Linux versions of assembler and linker, but stated they do not currently have plans to support Linux.
For DSP code development, we need an assembler, linker and a code downloader that sends an executable through the PC serial port to the DSP development board. For the ADSP21xx, few Linux tools are available just now, only the downloader.
The solution is to use DOSEMU, the Linux DOS emulator, which has an impressive feature called the dexe (directly executable DOS application). This is basically a single DOS file or application in a tiny DOS disc image that can be executed within Linux without the user being aware that it is actually a DOS program.
To use this method, the entire ADSP21xx tool set can be incorporated into a single .dexe file. With a little ingenuity, a few simple shell scripts and batch files, the user will never know the assembler and linker he is using are actually DOS programs (see Resources for a HOWTO).
With the newly created dexe, we now have an assembler and a linker for our DSP code. Hidden in the depths of the Analog Devices web site is the source code for a UNIX (Linux/Sun) download monitor to load the DSP executable into the EZ-KIT Lite through the PC serial port. This means the assembler source can be compiled and downloaded all (more or less) under Linux.
The one irritation is the simulator. Analog Devices supply a DOS version of their simulator which will not run under the emulator, but this is no reason to throw Linux out, as we shall see later.
Analog Devices does have a 21xx C compiler based on good old gcc and even released the source. The C code integrates neatly with the assembly language and speeds up development time, but it is quite inefficient both in terms of code size and instruction cycles.
We now have an algorithm that runs on a DSP system. The complete software package generated by this effort includes:
Rlab research and investigation scripts
Test vectors and speech files from Rlab
Floating-point C implementation
Fixed-point C implementation
Assembly language version of the code
A working DSP executable
Does this list look complete to you? If so, you must be a born programmer like me. Anyone else would realize that documentation is missing.
Has this happened to you? When your management says documentation must be in a standard format, you think LaTeX and they think Microsoft Word. ASCII is insufficient because of the lack of text formatting and graphics support.
However, one irrefutable standard that even your boss can agree to is HTML. Once a common standard has been agreed upon, it is time to produce a set of documentation templates. After that, any editor can be used to add content, including Netscape composer, Emacs or even Word. Graphics are more of a problem, but a combination of xfig and GIMP can handle most situations. The resulting web documentation can be read under Linux, Windows, RISC OS, etc. and is even accessible on palmtop computers.
We used RCS to manage our documentation versions too, in order to comply with company quality control standards. This allows a construct such as <li>RCS id: $Id$</li> to be embedded in the HTML. When the HTML document is checked into RCS, the RCS identifier will be inserted between the “$” symbols and will therefore be displayed on the HTML page.
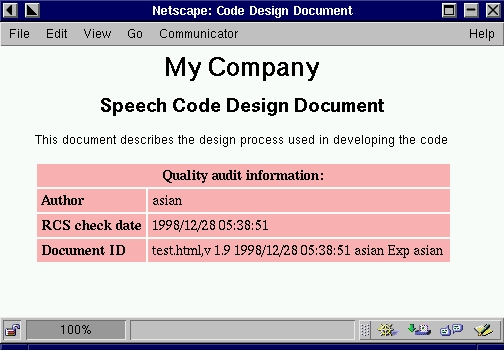
Figure 2. RCS Information Used in Inter/Intranet-Based Documentation
A prettier method is to use JavaScript for display in Netscape to format the page and remove the unwanted $ symbols. The HTML page in Listing 1 forms the front cover to some code documentation, as shown in Figure 2.
We all know HTML isn't perfect, but at least it is a compromise that can be agreed upon in striving toward a paperless office. Some other features we incorporated were placing the RCS log entries into a scrollable text area on the HTML pages and judicious use of hyperlinks to commented source code, data flow diagrams and flow charts.
To enhance our documentation, the C prototype code was compiled using GCC -pg which inserts extra code to write a profiling information file during program execution. Then gprof was used to interpret this profiling information. xfig was used to manually convert this into a function-call, graph GIF, and a sensitive image map was created for it. A set of HTML templates was created and edited to document each function; these pages can be accessed by clicking on this top-level GIF.
The result was a single HTML page showing the entire code in a pyramidal layer structure starting from main and the calling links between each function, with passed variable names written next to each calling link. The functions were named inside clickable boxes, which pointed to an explanation of that function.
This HTML documentation process is now being automated; see Resources for more information.
As an added bonus, my colleagues used the new documentation standard to justify buying more Linux machines. One was used to serve the documents on the company intranet using the Apache web server. This system can control access to the documents on a need-to-know basis, and keep a log of user accesses versus date and document version. It is even possible to automatically notify affected parties by e-mail when a document they accessed recently has changed.
Finally, let's consider the alternatives to Linux. The Analog Devices tools supplied with the EZ-KIT all run under DOS and are command-line programs. Of course, they could be run from a Windows DOS prompt, but this provides no advantage over Linux. Furthermore, an xterm is more flexible than a Windows DOS prompt, especially when you want to refer back to a page of error messages that flashed past. Also, the ADSP21xx simulator will not run under Windows, which would have to be rebooted cleanly into DOS, just as a Linux machine that needed to run the simulator would.
UNIX versions of the tools are supplied by Analog Devices at extra cost and are functionally identical to the DOS versions. However, they run only under SunOS; they do not run under newer versions of Solaris.
MATLAB is available for Linux, other UNIX systems and Windows, as is Rlab, but I would argue that only the flexibility of a UNIX operating system can allow the full use of these applications to interact with other command-line-based code development and debugging tools. Of course, debugging tools are available for all platforms. They may sometimes be more user friendly, but are probably less capable than gdb and are seldom freely available.
Revision control systems are also available for many platforms, but not all can cope with code development and integrate with a hyperlinked HTML-based documentation system being served via Apache. The revision control system you choose must also have the capability to interface with your favourite editor and be utilized within the make hierarchy.
Obviously, Linux makes a good DSP development system. All you need to buy is a DSP starter kit—everything else is on your installation CD or freely downloadable. This system has been used in the real world—it takes a little setting up, but it works. It is reliable and a lot more fun than Windows.
In the future, it will only get better: more DSP development tools will be available under Linux. I encourage you all to advocate the use of Linux-based development systems for both university and corporate research and development.


