
Bisel Bank
Bisel Bank was born around 1994 as a merging of many small banks. It is now one of the largest banks of Argentina with more than 160 branch offices (and plans to open many more) running in-house software, which will be replaced after the year 2000 with a commercial offering.
The central office runs on a Sun Enterprise 5500 server running Solaris 2.6 (with a similar one as a backup server), and all data is stored in an Informix Online 7 DSA database. The applications, written in JAM and ESQL/C, work quite well.
The branch offices use SCO UNIX and a mixture of Progress, ESQL/C and JAM/Informix applications. It all started when we had to consolidate about eight different systems from different banks. The JAM/Informix and Progress applications running on UNIX boxes won the battle against the other contenders, including some AS/400 hardware and software.
The software is developed and maintained by a group of programmers who continuously have to modify running programs or make new ones from scratch. We have to manage much “traffic” to and from the main server. To do this, we implemented a version control system for the programs using RCS (revision control system), and a system to send them to the main computer.
After the requirement for a new program or change in an existing one has been met and the new or changed program is finished, the program passes through a set of testing and authorization stages before it moves into the production environment.
When all is okay, the programs are sent to the central office or to an automatic distribution system (as required), which sends the modifications to all the branch offices overnight. This system was implemented using rsync (on a Solaris server), so the amount of data transferred over the network is kept to a minimum.
Finally, Linux makes its triumphant entrance. It all began when I came to this bank as a formal employee in November 1997. Being a Linux user since kernel 0.99, I believed that Linux deserved its place in this bank scenario.
I decided to install a Linux server to use as a test box. First, I used this equipment to test several software packages, then when I was satisfied, I moved the software to the Solaris environment. SCO was out of the question for testing purposes, because it was the old SCO 3.2.4.2, which makes it difficult to port software for it.
I began using the Linux box to test products such as Samba, rdist, rsync, Apache Web Server, PHP/FI, PHP3, MSql, MySQL, Solid Server, Solid Web Engine, VNC, Squid and even Informix SE for Linux. Much of this software is being used now at the bank on either the Solaris, SCO or Linux platforms or a combination of them.
I implemented various projects, such as designing and implementing networks using Samba; RCS for source code; an Intranet for manuals, documentation and internal procedures; automatic distribution of applications using rdist, which was soon replaced with rsync to save transfer time; a couple of backup procedures over the network; and even some tests with Java and JDBC to access database servers.
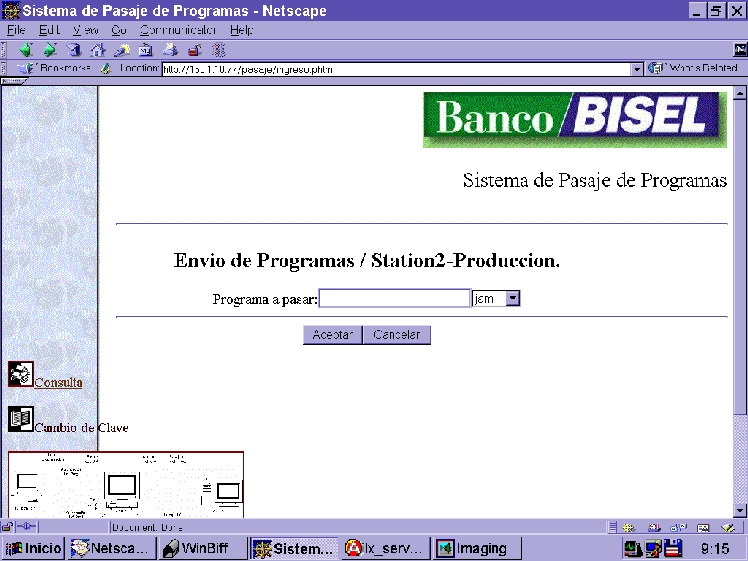
One day, a new project came about: build an application to use the Intranet to send programs to the production environment. What I wanted was to have complete control over where a program is at every moment.
Figure 1. Program Management Entry Screen
First, the programmer writes a new program or a modification to an existing one using RCS (with a front end designed to ease the programmer's work) to keep control of the versions. Then he or she must tell someone the program is finished, so someone else can have a look at it and make the appropriate tests before passing it to the production environment.
This is done by logging in to the “Sistema de Pasaje de Programas” system and entering the name of the program. At this point, the program is ready to receive an authorization to be sent to the testing environment. Once the authorization is granted, it can effectively be sent to the testing environment.
After all the necessary tests are passed successfully, the program is ready to go to the production environment. This is done by a similar process. In the first stage, the program is left “ok” to be passed, so it requires another authorization, then the final pass to the production environment.
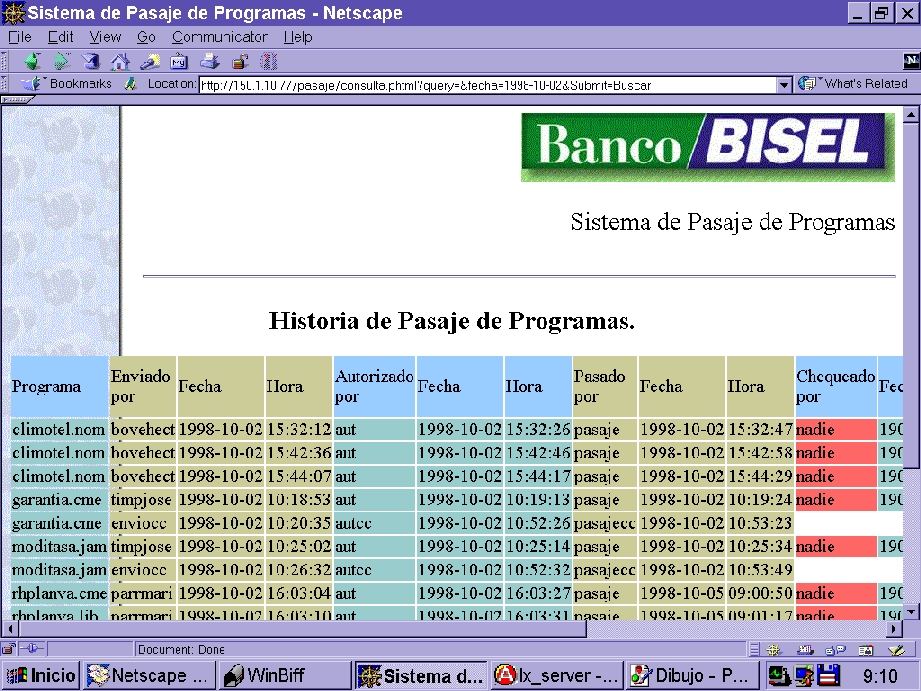
All these authorizations and passages are recorded in a database, so we can know exactly where one program is in every moment, i.e., when it has been authorized or passed to which environment.
All is done with a web-enabled application in which a record is inserted into the database, so the person in charge of the authorization finds it on a list on his screen when he checks whether there is something to be authorized. Then, this record is updated with the current user, date and time, so the person who makes the actual pass finds it on his list. It's easier to actually use than to explain in words. The application can also be sent to another testing environment with large quantities of data to make more extensive tests.
This system is hosted on a Slackware Linux server with 16MB of RAM, 1GB of disk space and a 133MHz Pentium processor. It has an Apache web server and a Solid database. It usually has an uptime of 60 or more days without any kind of problem. The HTML pages were made using a PHP3 build as an Apache module. This system was designed as a test for the Solid engine, which proves to be quite good—I recommend it. Because of the release of Informix SE for Linux and the use of Informix by our organization, I am reengineering the whole system with Informix SE or Informix OnLine, and it will be fully operational by the time you read this article.
One interesting consideration in this system is the stage at which the program is actually passed to the test or production environment. This is done with CGI scripts which execute various commands directly related to our programming environment. The system can be adapted to a totally new programming environment by replacing only those CGI scripts—it is not JAM-dependent. It was created with this independence in mind, because the bank will change its system in the near future, so this independence guarantees we can continue to use it with minor adjustments on our new system.
The method I used to pass a program to a different machine, which runs Solaris using a web application, is simply installing a web server on the Solaris, then using a URL that references a CGI script on that remote machine. This CGI script is responsible for passing the program, issuing the necessary rcp command and any commands necessary to leave the program ready to be used.
As you can see, the actual work is done by CGI scripts and all the HTML pages are used to glue the scripts in a nice-looking, easy-to-use application which stores all the program “flow” between equipment and stages in a database. I easily added report pages to view the activities by day or to search by program name.
In addition to porting all this to Informix, we are currently developing an application for the Human Resources office to retrieve information on employees. This is being done in a similar way and will be hosted on this same Linux server.
Because of the robustness shown by this architecture, we'll be making more and more web applications in the future, and Linux will be there as our web server.
I am quite impressed by PHP3—this product is incredibly flexible and powerful and can handle complex applications without problems. Its database support is getting better, supporting not only the classic freeware and shareware databases such as mSQL, MySQL and Postgres, or commercial databases such as Solid, but also the big databases such as Informix, Oracle and Sybase.
Without any doubt, Linux has a wonderful business future and is my favourite OS for Intel machines, outperforming Windows NT and SCO UNIX. In my opinion, Linux and Solaris are the best operating systems on the market at this time.
One important aspect to consider is the type of technical support available for your OS and for any other product you regularly use. On one occasion, I was stuck with a problem (it was my fault) that forced the Linux server to go down. I received help in 20 minutes from three technicians. Where did I get this kind of excellent support? Of course, it was the Internet. I posted a message, and in 20 minutes my problem was solved. I have not seen this kind of fast response on any commercial product from any company.
Pablo Trincavelli works for Banco Bisel S.A. in Rosario, Argentina as a Technical Analyst. He has been working with Linux since the early 0.99 days. Other than Linux, he has also worked with Solaris, HP-UX, SCO UNIX, WinNT, AmigaOS and many others. He likes playing with his PalmPilot and finding easy ways to do difficult things. He likes everything with chips inside and can be reached at pablo@iname.com.

{kind=link}
{kind=link}
{kind=link}