
Visualizing with VTK
Most scientists and engineers are adept at approaching and solving problems. If they use the scientific method, they may even get the right answer. However, analyzing results and measurements is often difficult because visualization tools are lacking. If your experience has been like mine, the tools for investigating data are either too specialized (vis5d), too weak (plotmtv) or too expensive (AVS). While good commercial packages exist such as Tecplot from Amtec Engineering, they often place restrictions (such as no remote displays in X) and constrictions on the user.
To solve this problem, three very intelligent men put their heads together (for nine months before coding began) and wrote The Visualization Toolkit (VTK). Will Schroeder, Bill Lorensen and Ken Martin have created one of the best systems available for performing scientific visualization. It is far and away the best value to be found today.
In this article, I will briefly describe what is required to obtain, compile and use VTK. The goal is to leave you with a sense of the scope of VTK and the level of commitment required to use it. You probably won't be able to immediately start creating visualization pipelines; however, you will have a good idea of the range of problems it is suited to solve and what will be required of you to solve them.
VTK is a collection of visualization “objects” which can be connected to make a visualization pipeline. VTK strictly follows the object-oriented model, whereby there is a hierarchy of objects, and any object which is a “sub-object” of another inherits the parent object's methods and properties. Objects are also broken down into “classes” which represent the authors' best estimate of the most effective set of tools required to put together a visualization. The objects are broken down into 14 categories by function: Foundation, Cells, Datasets, Pipeline, Sources, Filters, Mappers, Reader/Writer/Importer/Exporter, Graphics, Volume Rendering, Imaging, OpenGL Renderer, Tcl/Tk and Window-System Specific. The user will most often be concerned with Dataset, Pipeline, Sources, Filters, Reader/Writers and Graphics and/or Imaging or Volume Rendering, though the other classes are implicitly used in most cases.
With these classes, we have the ability to construct a “pipeline” which reads or creates data, filters it as required, and finally renders it on the screen or exports the rendering to a file. While the classes follow the object model, the pipelines are procedural, which is most often needed when reducing data. The pipeline starts with a source (data), is operated on by any number of filters (even recursively) and is finally presented as output. The “data” source may be unstructured points, structured points, structured grid, unstructured grid, rectilinear grid or polygonal data. The class of data determines the types of filters which may be used to operate on the data, with the more structured data having the most filters available. For example, unstructured points may not be contoured, but they can be remapped to a structured points set, which can be contoured. Armed with these tools, all that is required to visualize almost any data is a sound approach to reducing it. With the ability to visualize data well in hand, the rate limiting step is now relegated to performance, and it can be a big issue. Datasets can easily get quite large or require a lot of computational effort to manipulate. VTK has tools to deal with these issues as well.
To start, I recommend the book The Visualization Toolkit, Second Edition, by Will Schroeder, Ken Martin and Bill Lorensen, published by Prentice Hall. It is an invaluable reference for understanding both the visualization process and VTK. After you've read the terse (yet complete) man pages, you'll understand why the book is needed.
All of the following examples were created using the Tcl/Tk bindings to VTK. These examples can also be created in C++, Python or Java; the latter two are relatively new to VTK, so your mileage may vary. Some examples were borrowed with permission from the VTK distribution, and all are biased toward reduction of computational data as opposed to imaging data or graphics applications.
Often, the first thing we ask to see when we have a large dataset is “Where is the data?” A simple enough request, but most tools will not easily give it to you. Let's say we have smooth-particle hydrodynamics code which uses and generates unstructured points. For each point, we have the x, y and z coordinates as well as several scalar values (for now, tensor components will be considered scalars).
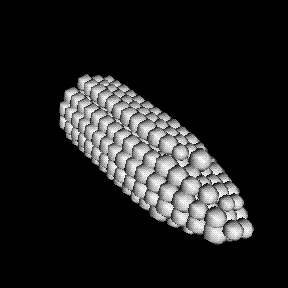
While not the most memory-efficient, one way to “see” the particles is to place glyphs at every particle position, scaled by the particle size. The visualization pipeline must take in the point data, create a glyph object and place one at each point location, scaled by the particle size. The set of glyphs must then be rendered on the screen. Listing 1 is the Tcl version of the code to do that, assuming you have read the point positions into the arrays xpos, ypos and zpos and the radius into rad.
Figure 1. Spherical Glyphs Scaled Relative to Particle Size
When this pipeline is run, a visualization window is opened on the desktop with a spherical glyph centered at the location of each point and a radius equal to the particle size (see Figure 1). Objects which are implicitly included in the scene but not listed above can be specified if required. These include lights, cameras and object properties. The implicitly defined objects are also accessible and controllable through their “parent” object; in this case, the renderer. In Tcl, a handy command is available from the VTK shell called ListMethods that informs you of all methods (and the number of arguments) available for any object. Adding the command ren ListMethods to Listing 1 would return the information that about 60 methods are available to you. After using this command on several objects, you will begin to see a structure to the methods and develop a sense of how the objects fit together.
With the addition of Tk entry boxes, all controllable attributes of all objects can be controlled interactively. However, changes to the pipeline will be seen only when the pipeline is re-executed with the new value and an Update is requested. This can be handled either by setting all attributes in a procedure called from the Tk interface or by attaching the method to the “command” argument of the widget that sets the value of the attribute. I recommend the former method.
The main access to the visible attributes of the scene is through the Actor objects and the Mapper objects. Attributes, such as visibility, color, opacity, specular reflectance, specular power and representation (wireframe, points, surfaces), are set with the vtkProperty object that is automatically created for the vtkActor, if one is not explicitly defined.
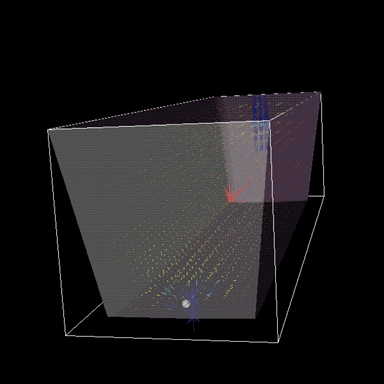
Now, let's say you want to evaluate a mesh created with an automatic mesh generator, and furthermore, you want to tag the cell with the smallest spacing. Starting with the nodes and connectivity list, the “mesh” can be built by connecting the connected nodes with line segments and placing a geometric object at each of the nodes containing the shortest and longest connection. Listing 2 is a “quick and dirty” bit of code that took me about 15 minutes to write (well, maybe a little longer). It assumes the nodal positions are known, and their right, back and upper neighbors are known and stored in the arrays i1tab, i3tab and i8tab, respectively.
Figure 2. Mesh Nodes, Connectivity and Minimum Cell Dimension
The code in Listing 2 creates the visualization shown in Figure 2. This pipeline does not include the code to make the boundaries visible. We will cover that next. The key features of this pipeline are the multiple sources (mesh data, sphere) presented in one scene. The sphere is placed on the node with the nearest neighbor in one of the three coordinate directions mentioned above. The polygonal data represented by the vtkPolyData object called mesh consists of two-point polygons, i.e., lines. Polygonal data is often read in with a reader or created automatically by a source or filter such as the vtkSphereSource (Listing 1) or a vtkContourFilter. Notice that the mappers for the mesh and for the sphere are different. The mesh mapper takes the mesh directly as input, but the sphere mapper operates on the vtkSphereSource, which is not vtkPolyData. The reason for this is that the mapper reads vtkPolyData as input. The mesh is vtkPolyData. The sphere is a source which can send out vtkPolyData, when requested, as we do when employing the GetOutput method on the vtkSphereSource.
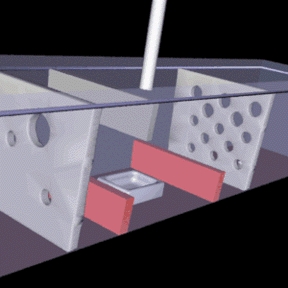
Satisfied with our mesh, let's look at some data. The pipeline excerpt in Listing 3 is based on the same mesh data as above, but includes methods to show the boundaries in the model and vector fields. [Complete listings for this article are available by anonymous download in the file ftp://ftp.linuxjournal.com/pub/lj/listings/issue53/3010.tgz.]
A lot is happening in the pipeline shown in Listing 3. First, the “mesh” polydata set gained two attributes: scalars and vectors (e.g., SetScalars, SetVectors). The vectors were created in a vtkFloatVector object. Their magnitudes were calculated and stored in a vtkFloatScalar field called field. The scalars are used by the mapper to color the vectors, and the vector data is used by the vtkHedgeHog (vector plotter) to create the oriented and sized vector glyphs. A separate pipeline is used to draw the surfaces of the object, and a 7-case switch is used to build the point connectivities for the surface panels per cell. It takes advantage of any connectivity which may exist on a given cell and builds a special type of polydata called “triangle strips”. Triangle strips allow n connected triangles to be created with n + 2 points. The vtkPolyData must be told that the given cell array values are triangle strips in order to properly set up the connectivity. This is accomplished with the SetStrips method, as compared to SetLines in the mesh example. The panels are made transparent by setting the opacity to .5, which allows the vectors to be seen. The color map for the vectors has been explicitly set to range between the minimum and maximum velocity magnitudes. By default, the mapping is red-to-blue from 0 to 1. The SetScalarRange method allows the range to be reset in the mapper. Notice the red vectors in the back left corner of Figure 3—an error is creeping in from the boundary and the location where it begins is very clear. Apart from verifying the correctness of the mesh, boundaries and boundary conditions, I can easily diagnose trouble spots in the calculation.
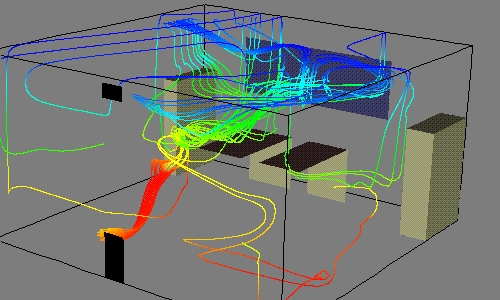
Finally, these last two figures demonstrate some of the advanced features of VTK. Figure 4 is a BMRT-rendered (Blue Moon Rendering Tool) export from VTK. The complex shapes were built entirely from contoured implicit functions. Figure 5 is from the VTK examples directory and shows streamlines emanating from “seeds” that are located at a heater vent.
While this treatment only scratches the surface of VTK's capabilities, you can begin to see the flexibility and power it affords the user. In addition to the features discussed in this article, VTK has objects for image analysis and manipulation, implicit functions, data transformation, data sampling, volume (solid object) rendering, memory management, texture mapping, data manipulation and exporting and more. Admittedly, the learning curve for becoming facile with VTK is somewhat steep, but it pays for itself many times over in saved time when doing complex analyses.
The official source code release of VTK is available from the VTK home page at http://www.kitware.com/vtk.html. For the more daring, almost-daily beta releases are available from http://www.kitware.com/vtkData/Nightly.html. On the average Linux system, software required to compile and run VTK includes the following: C++, OpenGL (or Mesa), tkUnixPort.h (from the Tk source distribution), Tcl 7.4 or higher, Tk 4.0 or higher. If you plan to use the Python or Java bindings to VTK, you will need those packages as well.
The VTK source code is written entirely in C++, and as of version 2.0 with Linux 2.0.31 and either libc5 or libc6, it compiles successfully without error with Mesa 2.5 and Tcl/Tk 8.0. In the README file at the top of the distribution, the user will find all the instructions necessary to do the build. Here's what I did:
Obtained and compiled Mesa (easy).
Retrieved tkUnixPort.h from the Tk source distribution and placed it in the (vtk_top_dir)/unix/directory (I used Tcl/Tk 8.0).
Ran ./configure --with-mesa --with-tcl --with-shared --with-tkwidget --with-patented
Edited user.make to find all the necessary support files.
Ran make.
Ran make install (optional; run only if you have the disk space).
Many more configuration options are available and can be seen by typing ./configure --help. I had trouble with the Python and Java bindings. The build, as configured above, takes about an hour on a Pentium-Pro 200MHz machine.
Many examples are available to test the installation in the (vtk_top_dir)/[graphics|imaging|patented|contrib]/examples[Cxx|tcl|Python] directories. Most imaging examples require the vtkdata archive to also be located at the VTK home site. Graphics examples will, for the most part, run as is. For the C++ examples, compile with make and run. Tcl examples can be run by typing the following from the Tcl examples directory: ../../tcl/vtk example_file.tcl, or, if vtk has been installed, vtk example_file.tcl. Examples employing the TkRenderWidget object cause a segmentation fault when using the XFree SVGA server, but work with the S3 server. (I haven't tested others.) Fortunately, TkRenderWidget is not required for any visualization pipeline; you can't embed the render window in a Tk window. However, this problem will likely be solved by the time you read this article.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}