
Archaeology and GIS—The Linux Way
Since the days of Heinrich Schliemann's search for Troy, archaeologists have been confronted with the dilemma of how to record the spatial characteristics of archaeological data, and once recorded, how to analyze those data. This spatial information has historically been recorded on paper maps of varying accuracy and scales. When researchers wanted to perform analyses of these data, they were required to spend hours, if not days, transposing this information to new paper maps and making arduous measurements by hand. This time-consuming process is nearing its end as researchers have moved to take advantage of geographic information systems (GIS) for spatial analysis. A GIS is best thought of as a dynamic database for spatial data. Fortunately for budget- and quality-conscious researchers, one of the oldest and most robust GIS packages, GRASS, is available for free on Linux.

In the late 1970s, the method of storing archaeological data began to slowly change from paper to digital. As access to affordable computers became more common, archaeologists could see the advantages of digitally storing their spatial data for analysis. During this era, several commercial vendors began to develop primitive GIS systems in an attempt to meet the needs of researchers for storing spatial data. Unfortunately, these products worked only with vector data, completely ignoring the utility of raster data for analysis. The Construction Engineering Research Laboratory (CERL) of the U.S. Army Corps of Engineers found this oversight in the commercial packages too great and decided the solution was to build their own UNIX-based GIS which would meld vector and raster analysis capabilities. Because this code was written with federal dollars, it was made freely available to the public. From this project, the GIS package Geographical Resource Analysis Support System, more commonly known by the acronym “GRASS”, was born. From its beginnings in 1982, GRASS has grown into a powerful GIS package that rivals expensive commercial packages, yet remains free to the public.
The McGregor Guided Missile Range, located on Ft. Bliss in western Texas and southern New Mexico, is just a bit smaller than the state of Delaware. As part of the army's long-standing commitment to effective management and research, Ft. Bliss hired the Archaeological Research Center (ARC) at the University of Texas-El Paso to do a 100% pedestrian survey of 180 square kilometers of the McGregor Range. Principal Investigator Tim Church and Ft. Bliss Lead Archaeologist Galen Burget realized that utilizing old-fashioned survey methods, which are primarily paper-based, would not be feasible for a survey of this size. Furthermore, the research team was keenly interested in utilizing spatial environmental and ecological information collected by other scientists at the post for a landscape analysis.
Archaeologists/computer jockeys Trevor Kludt and R. Joe Brandon were hired to help develop the most efficient method of dealing with the anticipated high volume of data, and to insure this data would be compatible with existing ecological data. R. Joe also directed the archaeological field crew during the project to monitor the feasibility of the data acquisition methodologies being developed. This hands-on approach allowed Trevor and R. Joe to tweak the methodology for collecting data so that all aspects of the project were integrated seamlessly.
The research team decided from the outset that a flexible and powerful GIS package was critical if we were to accomplish our goals. Considering that virtually no money was in the budget for additional hardware or software and the whole show would have to be run on a single mid-level Pentium PC (Gateway P-133 with 2GB hard disk and 32MB memory), we were in a bind. After considering a number of commercial GIS packages, we determined that GRASS running under Linux was the answer. GRASS offered the full suite of sophisticated GIS functions this project demanded, while Linux provided us with a wide range of tools to tackle the myriad customizations we knew were inevitable. Once the decision was made, we had Linux (Red Hat 4.0) up and running in no time, then downloaded the compiled binaries of GRASS (v4.2). This was all done for about what the field crews would spend on refreshments after a day surveying in the desert heat.
Knowing from the outset that our field data were to be integrated with raster (cell)-based environmental and ecological data, the research team decided to develop a raster-based field methodology for the survey. At first blush, this decision seemed very practical. In practice, it turned out to be the biggest challenge of the project. Traditional field methods focus primarily on defining the boundaries of archaeological concentrations (sites) and are therefore vector-based. The methods we were developing, focusing on the distribution of materials within the grid units or “cells”, were raster-based. How could we put these individual raster units together to define our sites?
For speed, flexibility and consistency, we decided to develop computer routines to do this monotonous work for us. As we needed these routines quickly, initial prototyping was done using Qbasic while Linux and GRASS were being set up. Eventually, we translated these routines into a comprehensive Tcl script suite and a number of Bash shell scripts. These scripts allowed us to automate the importation of the field-collected data, dynamically define site boundaries, provide reports on site inventories, import data into GRASS, run a suite of spatial tests and comparisons, and output the finished site and project maps. Without the power and stability of Linux and the interoperability of GRASS, these tasks would have taken a significant amount of time.
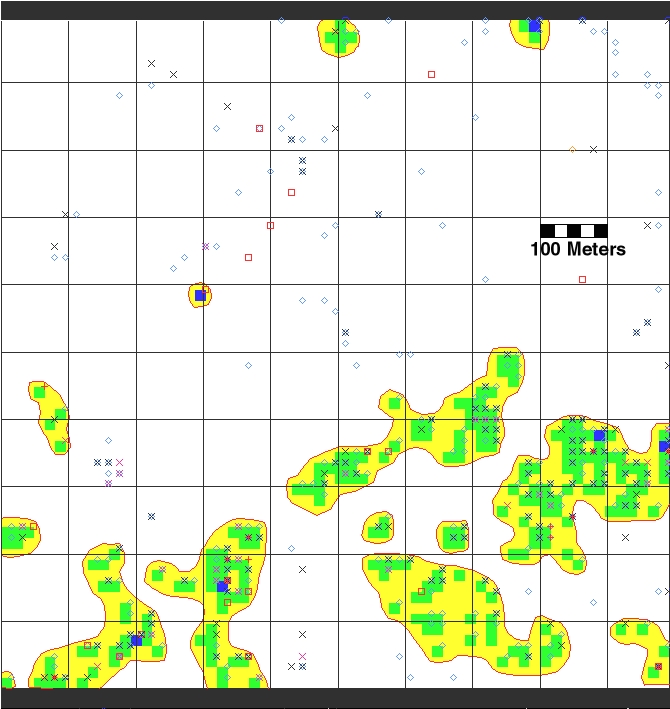
Figure 1. Single Survey Unit Results
Fieldwork proceeded rapidly. Each of the 180 square kilometer survey areas was divided into a grid of 16m2 “cells” which matched the size of the analysis raster cells within GRASS. Figure 1 shows the results of a single km2 survey unit, displaying artifact distribution, site boundaries and a 100-meter grid. The site boundaries were created using the GRASS module r.to.vect. The map output was created in a script file that can be sent to the screen or the printer. The size of the cells, 16m on a side, was a trade-off between the desire for precision (smaller units) and efficiency (larger units). Field crews would traverse these survey areas using 1:3,000-scale aerial photographs with the 16m2 grid superimposed on the photo. The detail of these air photos allowed the crew chief to navigate to near sub-meter precision quickly and consistently. As the crews walked through the survey areas, crew members would call out when they had spotted an artifact or feature, and the crew chief would then call back the corresponding row and column number for that “cell”. This information was then noted on a data recording form. In the lab, this information was checked for accuracy and errors, entered into a DOS-based data file (on a 386 with 40MB hard disk and 2MB memory salvaged from the scrap heap), then migrated to the Linux environment.
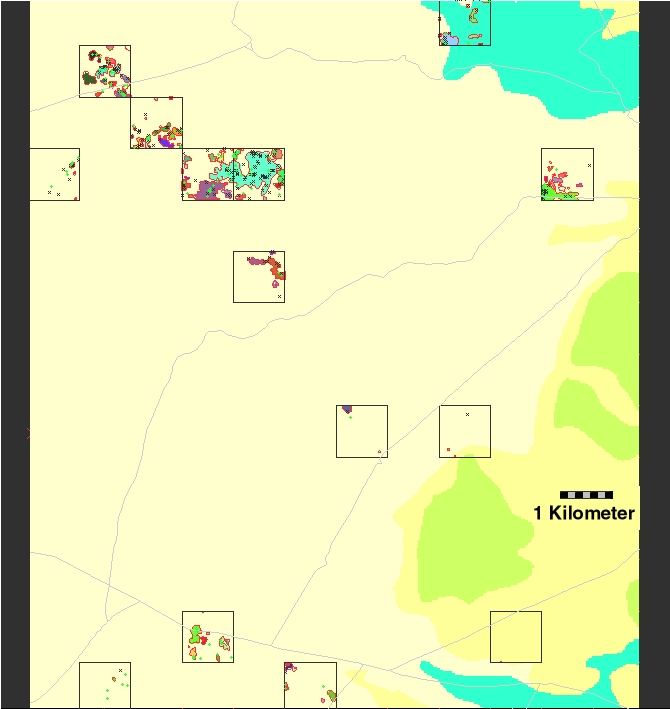
Figure 2. GRASS-generated Results
As the project unfolded, it became clear that the sheer volume of incoming data would give us no rest. Each day, the six field crews were covering thousands of cells on the ground and sending in mountains of data. Figure 2 shows the display results generated by GRASS for a small portion of the study area. This displays the variety of survey units, roads, site boundaries, artifacts and features. The map output was created in a script file that can be sent to the screen or the printer. Since development of the data processing routines coincided with the start of fieldwork, we quickly developed a backlog of data to process. And since each of the 180 survey areas was treated the same, we counted on the power of scripting redundant tasks to increase our efficiency in keeping up with the data stream. Once our routines were tested, debugged and on-line, we caught up quickly and were able to keep pace with the field crews. In the end, we accomplished what had at times seemed impossible. We are convinced the powerful scripting and developmental tools available under Linux, coupled with the sophisticated GIS routines available under GRASS, enabled us to successfully tackle the difficult and interesting challenges encountered during our project. Equally important, we were able to complete this project on time and under budget while creating one of the most dynamic spatial archaeological databases anywhere. In retrospect, we realized that even with a greater budget, we could not have fared better than we did utilizing the strengths of Linux and GRASS.
Although we were able to automate many of the tasks associated with survey work, we were never able to realize the full potential of the Linux/GRASS combination to automate virtually all of these tasks in concert with each other. We feel that a future project could be designed building on the work completed so far. This project could include equipping field crews with differentially corrected GPS receivers and data loggers to record and correct field data in real time. These data could then be downloaded at the end of the day and fed into the Postgres database engine which would provide seamless data entry and manipulation. Text formatting packages such as nroff/troff or LaTeX would be used to automate the production of site-specific reports and documentation. GNUplot could be used to produce the necessary graphs and charts. GRASS would be used for spatial display analysis.
Linked via scripts, we envision a time when field data collected in this manner could be downloaded, and within an hour, fully formatted and detailed site reports and maps would begin to pop out of the printer. Considering that with traditional methods the time gap between the input of raw data and the finished site-specific documentation is most often measured in weeks or months, we feel that this next level of integration is not only feasible, but advisable. By harnessing the tools Linux has made freely available, we believe there is much to offer researchers in this arena. We are glad to see development for both Linux and GRASS is so actively promoted by their respective communities and look forward to utilizing these tools to their fullest potential.
Although the project described above is of interest mainly to other archaeologists, the availability of a powerful GIS package for Linux is of interest to a larger segment of the Linux community, notably geographers, geologists and other researchers dealing with spatial data.
Development of GRASS languished for several years in the mid-90's after funding for future development at CERL came to a halt. There was concern among the international GIS community that GRASS, the father of raster analytical GIS packages, might finally be on its way to that great clippings bag in the sky. That fear was ended in November 1997 when the “GRASS Research Group” was established at Baylor University in Texas. This group pledged to continue development of GRASS. Interested in the ongoing maintenance and development of the GRASS GIS platform, they received the copyright for GRASS from CERL.
Coinciding with this renewed support for GRASS was the meteoric rise in the numbers of Linux GRASS users around the world, coupled with the availability of CPUs with sufficient speed to handle the volumes of data robust GIS package can deliver. The authors feel it has been the growth of the international Linux community that has been a major catalyst in giving GRASS a new lease on life. As Baylor continues to blaze new trails, a large audience of users eagerly awaits each update. Today, development is actively continuing, much of it pushed forward by users in the Linux community. Due to the stability, speed and power of Linux and its ability to turn even a modest PC into a strong UNIX workstation, GRASS has found a place in the Linux user community.
Since 1998, Linux GRASS has been developed by Markus Neteler, and the code is freely available at http://www.geog.uni-hannover.de/grass/ and several mirror sites. Additional UNIX flavors of GRASS are available from this site. Monthly updates of the GRASS 4.2.1 packages are published out of Hannover. Beside error corrections, these updates include new modules from independent GRASS programmers that have been collected from the international community and integrated into the system package.
GRASS was the last major GIS package to be completely command-line driven. A recent major improvement in GRASS has been the creation of a platform-independent graphical user interface based on the freely distributed Tcl/Tk libraries. The main work for this undertaking has been by Jacques Bouchard in France. This interface, TCLTKGRASS, gives users a clean GUI interface for GRASS commands and modules, as well as access through the standard command line. This GUI compliments the key strength of GRASS—it operates at the system level, allowing users to utilize the full suite of Linux utilities in conjunction with GRASS.
Figure 3. Sub-Pixel Analysis Results
The current release of GRASS 4.2.1 now comes with more than 350 modules. In addition to standard GIS functions for raster, vector and point data, it offers statistical and image processing capabilities. Markus has recently written an algorithm, called “spectral mixture analysis”, that performs sub-pixel analysis and true coverage degrees in percent. Figure 3 shows the results from a module for GRASS that allows the user to perform sub-pixel analysis on vegetation and soil types with the spectral mixture analysis module. The left map shows the covered soils in percent. The right map shows the difference between a remotely sensed image and ground-truthed imagery. Black indicates no difference, red indicates high difference. Known field errors account for the red in the middle. This module can be used for geological analysis as well as detection of minerals based on their spectra. The vector lines in this image were created using the module r.line on the remotely sensed image, which was much faster than digitizing. This figure was created using xfig, a free drawing tool with good map scale features. xfig is supported in GRASS through a vector and raster exporting module. GRASS users can also rectify off-nadir aerial images taken with a hand-held camera from a small plane and convert them into quasi-orthophotos usable for area or distance calculations or mapping purposes. An overview of Linux GRASS, the tutorials and sample data are also available from Markus's University of Hannover, Germany, web site at www.geog.uni-hannover.de/grass/welcome.html.
On Feb. 1, 1999, Baylor and Hannover simultaneously released the GRASS 5.0 beta. This was the first major upgrade to GRASS in a number of years. The demand was so high that downloads at Baylor accounted for 20% of the entire university Internet traffic. To date, several thousand unique downloads of Linux GRASS have been made from the Hannover site, which is currently transferring 5GB a week. This volume is steadily increasing. A stable release of GRASS 5.0 is planned for early summer—by the time you read this. Currently, bug reports are being collected and fixes applied to the code. The code is also being modified to make GRASS 64-bit compliant.
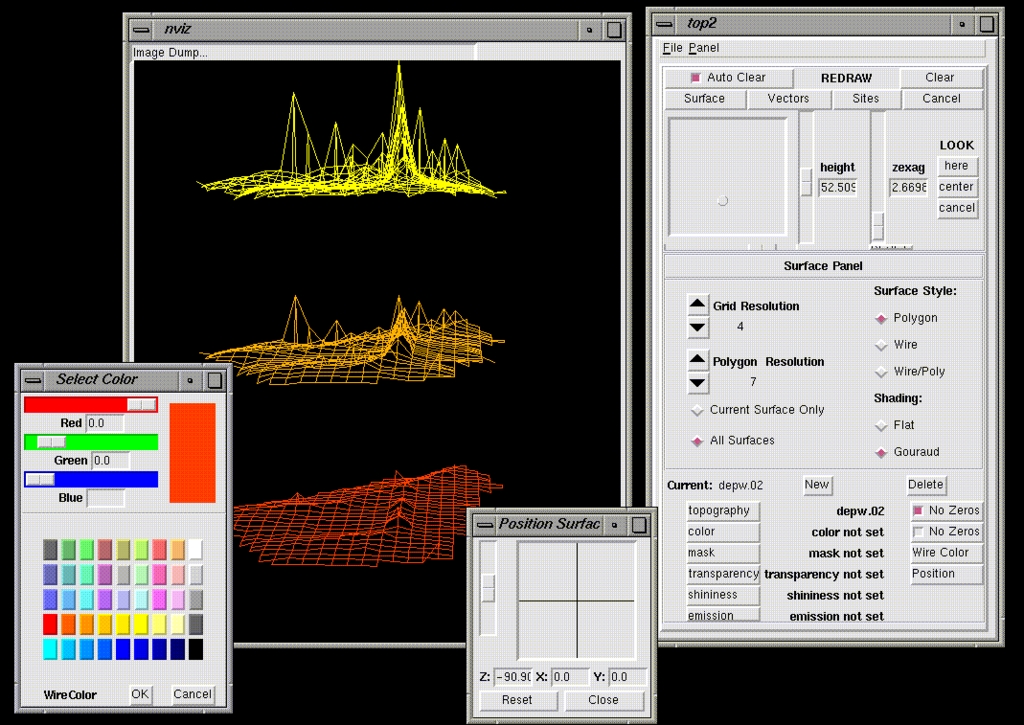
Figure 4. NVIZ, a 3-D Visualization Tool
The most significant new features of GRASS 5.0 are floating-point support in raster format and an improved sites format. Because all raster modules have to be rewritten, this is a major step in GRASS development. For the stable 5.0 version, several other projects are on the list. The NVIZ tool, a robust three-dimensional visualization tool, is currently being ported to Linux and other UNIX systems from SGI to aid in viewing 3-D GRASS data with raster/vector/sites overlaying features (Figure 4). This tool allows users to display 3-D raster data as stacked layers, with raster, vector and sites draped as overlays. It will be a very useful (and much sought-after) tool for data visualization.
To encourage user development of GRASS routines, the GRASS 5.0 programmer's tutorial will be available very soon. In the near future, the growth of GRASS will include introducing a new vector format. This is part of the long-term plan to continue the evolution of GRASS to a true 3-D/4-D GIS system. It will incorporate an improved 3-D raster format and new 3-D vector formats.
A friend recently summed up the future of GRASS and Linux quite well. He was leaving a research position to go work for a state agency using their expensive off-the-shelf GIS and remote-sensing packages; however, he had also worked with GRASS on a Sun box. Before he left, he sat down with me to get some information on setting up a Linux box on his office Wintel machine. As he said, “I need to be able to get the real spatial work done on a stable platform that is not going to crash; those commercial packages on Wintels are just too buggy.” When I sent him a copy of this last paragraph now that he has been in the office for some months, he responded, “You can say that again and again and again....” One more sign that the Linux juggernaut continues on its way into the workplace.




{kind=link}
{kind=link}
{kind=link}
{kind=link}