
Doubly Linked Lists and the Abstract Data Type
Experienced C programmers seeking relief from the drudgery of writing linked lists and dealing with the attending problems of keeping them, somehow, isolated from the rest of their code will appreciate this doubly linked list library. Those who are at an earlier stage in their C programming may also find here a useful tool for enhancing their cross-platform programming skills, as this linked list can serve as an example of an abstract data type (ADT).
Using ADTs allows the data in a specific piece of code to be hidden from other pieces of code that don't need and shouldn't have access to it. This is often called modular programming or encapsulation. The idea behind the ADT is to hide the actual implementation of the code, leaving only its abstraction visible. In order to do this, one needs to find a clear division between the linked list code and the surrounding code. When the linked list code is removed, what remains is its logical abstraction. This separation makes the code less dependent on any one platform. Thus, programming using the ADT method is usually considered a necessity for cross-platform development as it makes maintenance and management of the application code much easier.
The ADT concept is developed here via the example of how the doubly linked list Application Programming Interface (API) was created. The doubly linked list (DLL) can also be an independent C module and compiled into a larger program.
The DLL package consists of two C modules: dll_main.c comprises the DLL itself and dll_test.c creates an executable program for testing the DLL's functionality. There are also three header files: dll_main.h is included in dll_main.c, linklist.h is included in your application program, and dll_dbg.h is used for debugging the DLL or the DLL's implementation in your application. A word of warning needs to be expressed here: the header dll_dbg.h should never be compiled into a production program, as doing so circumvents the whole concept of ADT programming. The entire package has been compiled on three platforms with four compilers and includes three of the respective Makefiles. Only one of the platforms exhibited any problem because of a compiler that was not fully ANSI compatible. More will be said about platforms later.
Before we get into the philosophy behind this DLL, I want to explain what my goals were when I decided to write this library. It first had to be platform-independent and instantiable; in other words, the DLL had to handle an unlimited number of instances of linked lists in any one or multiple programs concurrently. Also, it had to be robust.
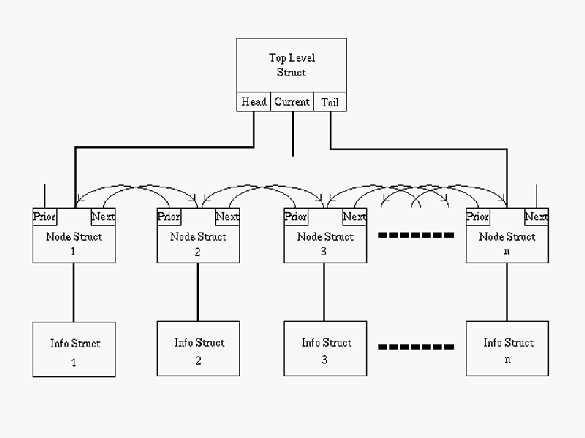
Figure 1. Layout of Doubly Linked List in memory. The arrows indicate to what the Prior and Next pointers point. The Current pointer can point to any Node Struct, so it is open-ended.
In order to fulfill the first requirement, I decided to strictly adhere to the ANSI C standard, and, with the possible exception of how one sets up one's data and uses the DLL's input/output functions, there should be no endian (byte order) problems. The second requirement was met with the creation of a top-level structure. There is only one of these structures per linked list. It keeps track of the node pointers, the size of the applications data in bytes, how many nodes are in the list, whether or not the list has been modified since it was created or loaded into memory, where searching starts from, and what direction a search proceeds in. Figure 1 illustrates how the top-level structure is integrated into the DLL.
typedef struct list
{
Node *head;
Node *tail;
Node *current;
Node *saved;
size_t infosize;
unsigned long listsize;
DLL_Boolean modified;
DLL_SrchOrigin search_origin;
DLL_SrchDir search_dir;
} List;
This and the next typedef structure remain hidden from the application program. The node pointers mentioned above are defined in the next structure, which includes the pointers to the application's data and the pointers to the next and prior nodes. One of these structures is created for each node in the list.
typedef struct node
{
Info *info;
struct node *next;
struct node *prior;
} Node;
The last definition is a dummy typedef of the
user's data. It is defined as type void so
that the DLL's functions will be able to handle any of C's or an
application's data types.
typedef void Info;As you can see, if the two structures mentioned above are hidden from the application, all of the ugly innards of how the linked list operates will by default be hidden from the application. Thus, we have an abstract data type.
The interface itself follows logically. The first argument of all the DLL's API functions is a pointer of type List. This pointer can easily be changed to different lists, thereby accommodating the instantiation requirement of the DLL.
The API's 25 functions are broken down into seven function groups: three initialization, three status, four data modification, six pointer manipulation, six search, two input/output and one miscellaneous. The initialization group handles the creation, initialization and destruction of the DLL. The status group returns various types of information about the DLL. The pointer manipulation group allows the arbitrary repositioning of the current pointer. The data modification group adds and deletes nodes. The search group returns node information based on keyed data fields or on absolute node position. The input/output group saves or retrieves node data to or from a disk file. The miscellaneous group currently only supports version information.
The function prototypes that follow will return two or more enum types or the boolean type. Some functions have a void return value.
typedef enum
{
DLL_NORMAL, /* normal operation */
DLL_MEM_ERROR, /* malloc error */
DLL_ZERO_INFO, /* sizeof(Info) is zero */
DLL_NULL_LIST, /* List is NULL */
DLL_NOT_FOUND, /* Record not found */
DLL_OPEN_ERROR, /* Cannot open file */
DLL_WRITE_ERROR, /* File write error */
DLL_READ_ERROR, /* File read error */
DLL_NOT_MODIFIED, /* Unmodified list */
DLL_NULL_FUNCTION /* NULL function pointer */
} DLL_Return;
typedef enum
{
DLL_FALSE,
DLL_TRUE,
} DLL_Boolean;
What follows is a short description of all the functions in the API. It is not possible to describe all the intricacies of how the functions are called and what they each return in a short article like this. For this information, refer to the documentation and source code in the distribution.
First we need to create a list pointer.
List *listname = NULL;
To create the top-level structure, execute the following function:
List *DLL_CreateList(List **name);After this structure is created it needs to be initialized using the next function:
DLL_Return DLL_InitializeList(List *list, size_t infosize);That's it—one instance of the DLL is ready to work with; however, there is one last function in this group that is used when we want to permanently remove the list and the top-level structure.
void DLL_DestroyList(List **name);Notice the pointer to pointer notation again; this is used so that name can be returned as a NULL pointer. The C standard function free does not set the pointer; it is passed to NULL after deallocating its memory. This can cause a possible problem if that pointer should unwittingly be reused.
I've written a template (see Listing 1) of the initialization sequence. This and the source code in the distribution should help in using the DLL.
The next function tests pointers in the top-level structure to determine if there are any nodes in a list.
DLL_Boolean DLL_IsListEmpty(List *list);
The inverse of this function, which follows, creates a new node to see if there is enough memory for a new node. If there is sufficient memory, the temporary node is freed.
DLL_Boolean DLL_IsListFull(List *list);To get the number of nodes (records) in the list use this next function.
unsigned long DLL_GetNumberOfRecords(List *list);
The process of adding new nodes to the linked list can be as easy or as complex as you desire. The following function has the ability to do an insertion sort as it adds nodes or just stick the nodes on the end. Don't let the list of arguments scare you; the function prototyping makes it look worse than it really is.
DLL_Return DLL_AddRecord(List *list, Info *info, int (*pFun)(Info *, Info *));
The first argument is a pointer to the top-level structure, which is the same in all the functions. The second argument is a pointer to the data you want to put into the linked list. The third and last argument points to an optional function that you could write, which determines the sort criteria.
It is worth reviewing how this function should be written, as it shows up again in two other functions described below. It emulates the way the C standard function strcmp returns its value. As a matter of fact, it can be just that.
int compare(Info *newnode, Info *keylist)
{
return(strcmp(newnode->key_element,
keylist->key_element));
}
Updating the current node (record) is a must in any linked list implementation, and this DLL API is no exception.
DLL_Return DLL_UpdateCurrentRecord(List *list, Info *record);We would also want to delete the current record.
DLL_Return DLL_DeleteCurrentRecord(List *list);The last function in this group deletes the entire list but not the top-level structure.
DLL_Return DLL_DeleteEntireList(List *list);
As shown above, there are four pointers in the top-level structure. We concern ourselves here with the current pointer. This pointer is where all the power in the DLL comes from and is used in many of the DLL's functions to determine what to work on.
The next two functions move the current pointer to the head or tail of the list.
DLL_Return DLL_CurrentPointerToHead(List *list); DLL_Return DLL_CurrentPointerToTail(List *list);
Often, incrementing or decrementing the pointer is necessary:
DLL_Return DLL_IncrementCurrentPointer(List *list); DLL_Return DLL_DecrementCurrentPointer(List *list);It is sometimes desirable to store the current pointer, then do something else, and then restore the pointer. We take care of this in the next two functions.
DLL_Return DLL_StoreCurrentPointer(List *list);
DLL_Return DLL_RestoreCurrentPointer(List *list);
There is little use having a linked list if you cannot find what has been stored in it. The following functions let you find your data and specify exactly how that data will be found.
DLL_Return DLL_FindRecord(List *list, Info *record,
Info *match, int (*pFun)(Info *, Info *));
The first argument, as usual, is the pointer to the linked list. The second is a pointer to the returned data. The third is a pointer to the matching criteria, and the last argument is a pointer to the compare function that was previously described in the data modification group. This compare function can be constructed differently, but the idea is the same.
Now life gets a little difficult. The above function needs to know how to look for the data in the linked list. Does it look down from the head pointer, up from the tail pointer, or up or down from the current pointer? My solution to this problem was to use a state table.
There are two more typedef enumerations needed, relating to the state table, one to set the origin of the search and the other to set its direction.
typedef enum
{
DLL_ORIGIN_DEFAULT, /* Use current origin
* setting */
DLL_HEAD, /* Set origin to head pointer */
DLL_CURRENT, /* Set origin to current pointer */
DLL_TAIL /* Set origin to tail pointer */
} DLL_SrchOrigin;
typedef enum
{
DLL_DIRECTION_DEFAULT, /* Use current direction
* setting */
DLL_DOWN, /* Set direction to down */
DLL_UP, /* Set direction to up */
} DLL_SrchDir;
The state table defaults at initialization to DLL_HEAD and DLL_DOWN. The DLL_FindRecord function uses these values if not changed. To change the operation of this function, use the next two functions shown. If no change is desired in either of these two functions, use DLL_ORIGIN_DEFAULT or DLL_DIRECTION_DEFAULT. The first function sets the table to new values:
DLL_Return DLL_SetSearchModes(List *list,
DLL_SrchOrigin origin, DLL_SrchDir dir);
The second function returns a pointer of a copy of the state table
to the following structure:
typedef struct search_modes
{
DLL_SrchOrigin search_origin;
DLL_SrchDir search_dir;
} DLL_SearchModes;
The purpose of this function is to check how a succeeding search
will be conducted by interrogating the state table.
DLL_Return DLL_GetSearchModes(List *list);Last in this group are three functions that return data relative to the location of the current pointer. They are not affected by the state table.
DLL_Return DLL_GetCurrentRecord(List *list,
Info *record);
DLL_Return DLL_GetPriorRecord(List *list,
Info *record);
DLL_Return DLL_GetNextRecord(List *list,
Info *record);
Generally, input and output functions would not be considered a part of a linked list implementation; however, they do make life a bit easier when using ADTs. Without these functions one would have to set the current pointer to the head or tail of the list and then make repeated calls to one of the DLL_Get functions mentioned above. If sorting during this process were needed, the task would be even more tedious.
Writing to or reading from a disk tends to be very platform specific. I have striven to make the next two functions as generic as possible; they open files in binary mode and write or read the Info structure from beginning to end. Depending on how you enter data in the Info structure will determine if there will be any endian problems.
To save a list, determine the full path to the file, then pass its pointer to the next function. There are no sorting options with this function, because the list is presumably sorted in memory and will be saved in that order.
DLL_Return DLL_SaveList(List *list,
const char *path);
When loading a file from disk, you have the option of sorting the list as it comes into memory. Passing a NULL loads the file as it exists on the disk and loads it faster than if the list is sorted.
DLL_Return DLL_LoadList(List *list, const char *path, int (*pFun)(Info *, Info *));
This last group has only one function in that it returns version information, so a program can determine if it is linking to a different version and check for any incompatibilities.
char *DLL_Version(void);
The short answer is it is used for just about any type of data storage where you don't know how much data is to be stored. One example that I've been working with is 3D graphics data where there could be an unknown number of objects in a scene. I've written bar code scanning software that uses this DLL to keep track of all the hand-held terminals that are in use. I also worked on a database conversion program that reads data into one linked list, allowing you to edit it; it then converts the data to another linked list and writes it out again.
I'll mainly concentrate on compiling the Linux version; however, there are two Makefiles for DOS: one that compiles using the DJGPP GNU compiler and the other for the MS6.0 compiler. All three Makefiles are included in the distribution. If anyone is interested, there is also a slightly modified version of the DLL that compiles on Big Blues 4690 OS (FlexOS) using the Metaware C compiler (this OS is used in point-of-sale systems).
First, we need to use tar to extract the files into the directory where you want it to reside.
tar -xvzf linklist.1.0.0.tar.gz -C /your/path
The tar file will create a directory named linklist and put everything in it. Next, use cd to move to the linklist directory and type one of the following, assuming you're using the GNU compiler:
makecreates a shared library, or
make staticcreates a static library.
To install the library in the /usr/local/lib directory, enter either make install or make install-static.
That's all there is to it. You're now ready to write some code.
Carl J. Nobile currently writes point of sale software and is the administrator of an AIX Unix system for Genovese Drug Stores in New York. At home he is working on a program that can be used to design geodesic homes using ideas from Buckminster Fuller's Synergetics. He can be reached electronically at cnobile@suffolk.lib.ny.us.


{kind=link}