
The SANE Scanner Interface
SANE stands for “Scanner Access Now Easy”. It is a universal interface that enables you to acquire images from any device that produces raster images, including flatbed scanners, video and still cameras and frame grabbers. The intent of SANE is to make it possible to write image-processing applications without having to worry about peculiarities of individual devices. Looking at it from the other side, SANE makes it possible to write a device driver once and only once. That same device driver can then be used by any SANE-compliant application.
Have you ever wanted to scan an image under Linux? If so, you probably know the feeling of being faced by a bewildering number of scanner-driver packages. At the time of this writing, at least fourteen different scanner packages exist for Linux. While each individual package is usually of high quality, it is often difficult to determine which package should be used for which scanner. Furthermore, some packages come with a command-line interface, others include Tcl/Tk based graphical front ends, still others come with full-featured, graphical front ends. While variety is said to make life sweet, in this case it's more likely to cause a sizeable headache.
SANE was created to provide a solution to this dilemma. The basic idea is simple: if there was a general and well-defined application programming interface (API), it would be easy to write applications independently from scanner drivers. Thus, the author of a new scanner driver would not have to worry about writing an application for the driver. There are benefits for the application programmer as well; since SANE is universal, an application can be written independently of the devices that it will eventually control. Suppose we wanted five applications to support ten different devices. With the old approach, 5*10=50 programs would have to be written. With SANE, only 5+10=15 programs have to be written. SANE has advantages for the user too. It gives the user the liberty to choose whichever application he likes best, and that one application can be used to control all image-acquisition devices the user can access. Thus, SANE makes it possible to present the same consistent interface independent of the particular device that is in use.
Of course, SANE is not the first attempt to create such a universal interface. You may have heard of TWAIN, PINT or the Linux hand-scanner interface. The problem is that these older interfaces prove to be lacking in one way or another. For example, PINT is really a somewhat primitive kernel-level interface and the hand-scanner interface by definition is limited to hand-scanners. In contrast, SANE is general enough to support any device that acquires raster images. The closest thing to SANE is probably TWAIN. The fact that the two rhyme is not coincidental, but that's a different story. The main reason TWAIN is not SANE is that TWAIN puts the graphical user interface to control the device in the driver instead of the application. This makes it unsuitable for Linux or networked environments where the scanner driver might run on one machine and the application on another. In contrast, SANE enforces a strict separation between the actual driver and the user-interface for its controls. Indeed, the current SANE distribution includes support for network-transparent scanning.
To start using SANE, fetch the latest version of the distribution from the ftp directory ftp://ftp.mostang.com/pub/sane/.
If you want to build the graphical-user-interface programs that come with SANE, you will also need to fetch, build and install the GIMP or, at a minimum, the GTK distribution. Both GIMP and GTK are available at ftp://ftp.gimp.org/. GTK is the user-interface toolkit that originally has been developed for the GIMP, but is now being adopted by many other projects, including SANE. Note that the SANE distribution will build just fine without the GIMP/GTK libraries. However, that way none of the nice graphical-user-interface programs will be built, thus taking away much of the fun. So, unless you are building SANE for a server only, I recommend that you install at least GTK, if not GIMP.
After fetching the SANE distribution, unpack the compressed tar file and follow the instructions in the README file. The README explains how to build and install SANE. Also, take a look at the file called PROBLEMS; it contains a list of known problems and their work arounds.
Note that you don't have to own a scanner or a camera to play with SANE. The distribution includes a pseudo-driver that simulates a scanner by reading portable “anymap” (PNM) files. Also, SANE is not limited to Linux. Besides Linux for Alpha, x86 and m68k, it includes support for AIX, Digital Unix, FreeBSD, HP-UX, IRIX, NetBSD, SCO, Solaris, SunOS and even OS/2.
After installing SANE, you should be able to type the command
scanimage --list-devices
and get the output shown below:
device `mustek:/dev/scanner' is a Mustek MFC-06000CZ flatbed scanner device `pnm:0' is a Noname PNM file reader virtual device device `pnm:1' is a Noname PNM file reader virtual deviceAs the listing shows, in this particular case, a Mustek scanner is available under name mustek:/dev/scanner and two fake devices called pnm:0 and pnm:1 are available that can be used to read PNM files. To get list of all options for a particular device, for example pnm:0, simply type:
scanimage --device pnm:0 --helpThis will produce the help message shown in Listing 1.
The SANE package comes with a detailed man page that explains the specifics of the scanimage program. As an example, suppose we had a PPM file named input.ppm. We can use the scanimage program to “scan” that image and increase its brightness by 50% using the following command:
scanimage --device pnm --brightness 50 input.ppm > out.pnm
If you look at file out.pnm with an image viewer such as xv, you should be able to see that output.ppm is noticeably brighter.
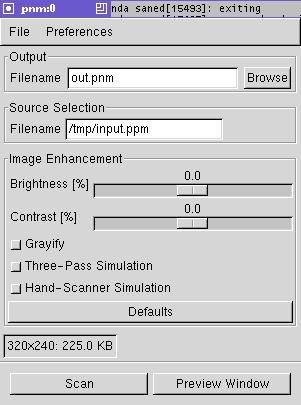
You may say: cool, but where is the graphical user interface? Assuming you had the GTK libraries installed when SANE was built, you can invoke a program called xscanimage that will present you with a dialog box containing a list of available devices. If you double-click on the “pnm:0” entry, you'll get the dialog shown in Figure 1. As you can see, the dialog includes two text-entry boxes labeled “Filename” and a slider labelled “Brightness”. If you enter “out.pnm” in the first text-entry box and “input.ppm” in the second box and move the brightness slider to 50.0, you can press the Scan button at the bottom left and get the same result as with the scanimage command line shown above. Of course, before doing the actual scanning, you could press the Preview button at the bottom right to pop up a preview window (see Figure 2). In the preview window, you can push the Acquire<\!s>Preview button to obtain a low-resolution preview of the final image. For example, by moving the brightness slider around, you can see how the brightness of the image is affected. After moving the slider, you'll need to press the Acquire Preview button to get an updated preview.
When scanning an image with a real scanner or camera, you'll usually want to enhance it in various ways, such as making it appear sharper. The nice thing about the xscanimage program is that it can also be run as a GIMP extension. To do this, simply create a symlink from the GIMP plug-ins directory to the xscanimage binary. Assuming the SANE installation defaults, you could do this with the following command:
ln -s /usr/local/bin/xscanimage ~/.gimp/plug-ins
After making this link, xscanimage will attach itself to the GIMP's “Xtns” menu the next time you start it. This makes it possible to invoke, for example, the PNM pseudo-device by selecting “Xtns->Acquire Image->pnm:0”. When invoked in this manner, pressing the Scan button will put the newly scanned image inside a GIMP window (instead of saving it to disk). Now, the usual GIMP image-manipulation functions can be used to enhance the acquired image before saving it.
Figure 3. Mustek Dialog Window for xscanimage
The PNM pseudo-device may be fun, but what does a real scanner interface look like? Figure 3 shows the xscanimage dialog as it appears for Mustek flatbed scanners. The figure also demonstrates another feature of xscanimage: tool tips (also known as “balloon help”). Tool tips make it easier for new users to get acquainted with the capabilities of their scanner or camera. In the figure, the mouse points to the Scan<\!s>Source menu and, as a result, the help information for that menu is shown in the yellow box below the mouse pointer. Tool tips are handy for new users, but after a while, they tend to get in your way. Thus, xscanimage allows advanced users to turn off the tool tips using the Preferences sub-menu.
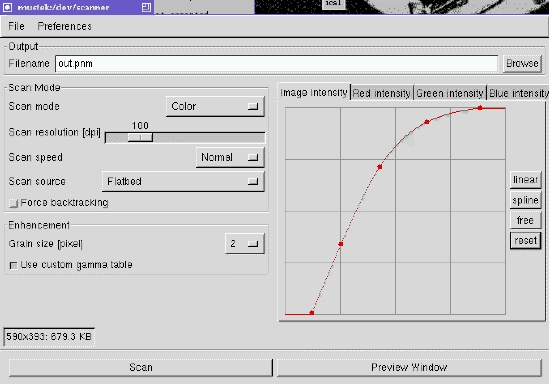
As you can see, the Mustek dialog looks quite different from the PNM pseudo-device interface. This is because the underlying devices have different capabilities. In fact, the device dialog depends not only on the selected device, but also on the mode of the device. For example, when turning on the “Use custom gamma table” option near the bottom of the dialog, the interface changes, and the result is shown in Figure 4. As you can see, the right half of the dialog now contains a graph editor that allows the user to modify the intensity, red, green or blue gamma table. In other words, xscanimage displays precisely the options that are active or meaningful for a given scan mode, greatly reducing the likelihood of confusing the user.
Figure 4. Mustek Dialog With Gamma Table Editor
Looking at the image-intensity gamma table in the right half of the figure, you can probably imagine that it would be rather annoying to define the gamma tables each time you started xscanimage. Once the ideal tables have been found, it would be nice if it were possible to save them. For this purpose, xscanimage allows saving the current device settings through an entry in the Preferences sub-menu. Once saved, whenever xscanimage is started, it automatically restores the last saved option values for that device.
Now that you have seen how to use some of the programs that come with the SANE distribution, it is time to tell you what else is included. At the time of this writing, the package includes drivers for the following devices:
Connectix QuickCam (color and monochrome)
Some Epson SCSI scanners
Hewlett-Packard ScanJet SCSI scanners
Microtek SCSI scanners
Mustek SCSI flatbed scanners (both one-pass and three-pass scanners are supported)
PINT devices: PINT is a Unix-kernel interface for NetBSD, OpenBSD and SunOS. SANE's PINT driver provides access to any scanner for which there is PINT support
Most UMAX SCSI scanners
Support for many other scanners and cameras is planned and some of them should be ready by the time you read this article. For the latest information, please visit the web page listed in the Resources.
Available applications are the command-line scanimage, the graphical xscanimage (either stand-alone or as a GIMP extension) and xcam, a graphical user interface suitable for cameras which produce a continuous stream of images (such as the Connectix QuickCam).
In addition, there are SANE API bindings for Python and Java API and a network daemon called saned that provides network-transparent access to remote devices. Assuming you have the appropriate permissions, this makes it possible to control a camera running in the U.S. from a machine running in Europe—all courtesy of SANE and the Internet.
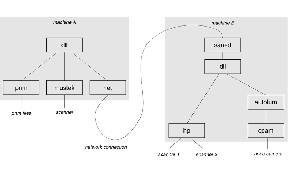
When building a SANE application, it must be linked against the shared library called libsane.so. In reality, libsane.so is just a symlink to one of the SANE drivers. Since every SANE driver exports the exact same interface, you can change the libsane.so symlink at any time and effectively change which driver the application is using. While this is useful in the sense that it allows upgrading to a different driver without having to relink all the applications, it would not be very convenient if you had to change a symlink whenever you wished to switch the scanning device. For this reason, SANE supports two pseudo-drivers called dll and net. They are pseudo-drivers because rather than talking to physical devices, they talk to other SANE drivers, as illustrated in Figure 5.
For machine A, the libsane.so symlink points to the dll pseudo-driver (called libsane-dll.so). That pseudo-driver uses dynamically linked libraries (dll) to access other SANE drivers. In the example, dll is configured to use the pnm, mustek and net drivers. The net driver is again a pseudo-driver; it provides access to remote scanners by connecting to the SANE daemon (saned) running on machine B. Machine B in turn uses dll again to provide access to a variety of other drivers. As you might imagine, the exact configuration is entirely up to the system administrator(s) of machines A and B. It is fairly typical to have libsane.so be a symlink to the dll pseudo-driver, but there is no reason it couldn't point to the net pseudo-driver or just the mustek driver. Of course, in the latter case the implication would be that applications could access the mustek driver only—but that's perfectly reasonable for certain environments.
Figure 5. Possible SANE Hierarchy
This approach is very flexible, but it raises an interesting question: how do we name devices in such an environment? The answer is that every real driver has its own device name space. For example, the Mustek and HP drivers use the path for the Unix special device that controls the device, such as /dev/scanner. With pseudo-drivers, things get a bit more interesting. Since dll must guarantee that each device name is unique, it simply prefixes the name of each subordinate device with the name of the subordinate driver, separated by a colon. Thus, on machine A, the mustek scanner would be called mustek:/dev/scanner. The net pseudo-driver does something similar: it prefixes the remote device name with the remote host name (again using a colon as a separator). For example, HP scanner 1 on machine B would appear on machine A under the name net:B.domain.com:hp:/dev/scanner1. While this doesn't make for the world's prettiest names, the information contained in the names is actually quite useful. In essence, much like a Unix path name, the device names convey the path through the SANE hierarchy that leads to a particular device. For example, if you know that machine B is down, it's pretty obvious that net:B.domain.com:hp:/dev/scanner1 will be down as well. If someone feels strongly about these names, it is possible for an application to let a user or system administrator define aliases that are more concise. For example, an application could let a user rename the above device to “HP Scanner 1”, which may be easier for beginners.
By definition, SANE is only as good as the programs that use it. This means the more applications and the more devices that use SANE, the merrier. The SANE distribution comes with a detailed document that explains the SANE API; however, the interface is quite simple. The six main functions are listed below:
handle <- sane_open(device-name) allows you to open a SANE device by name (e.g., pnm:0).
sane_close(handle) allows you to close a SANE device by name.
sane_get_option_descriptor(handle, option-number) is used to query the controls available to the device (such as the brightness control in the PNM pseudo-device driver).
sane_control_option(handle, option-number, action, value) is used to get or set the value of an option. For example, it can be used to set the value of the brightness option to 50 percent. In addition, some options support an auto-mode where the driver picks a reasonable value. For such options, sane_control_option() can also be used to turn auto-mode on or off.
sane_start(handle) is used to start the acquisition of an image.
bytes-read <- sane_read(handle, buffer, buffer-size) is used to read the actual image data until the entire image has been acquired.
The SANE API is simple by design. The goal was to make it possible to accomplish a simple task in a small amount of time while still providing enough functionality to enable sophisticated drivers and applications. The simplicity is best evidenced by the fact that it took just two evening sessions to convert the hpscanpbm program into a SANE driver for HP scanners. On the other end of the spectrum, the Mustek driver and xscanimage are fairly complicated programs and SANE had no problems accommodating them.
What's our position with respect to commercial SANE drivers or applications? In the spirit of the GNU Public License, it is preferrable to have the source for SANE programs available. However, it is permissible to write a dynamically loaded, commercial SANE driver on Linux and other platforms that support dynamic loading. (Drivers are always dynamically loaded, so this doesn't cause any extra work.) By the same token, it is also proper to write a commercial application that links with the libsane.so shared library. The basic ideas supporting this position are:
Healthy competition between commercial and free programs is an asset, not a liability.
The more wide-spread use SANE finds, the better for the Linux/Unix community.
In the immediate future, the plan is to add support for many more devices. For example, Agfa and Plustek scanner and Nikon filmscanner drivers are planned, and there is hope that drivers for some of the more popular digital cameras will materialize soon as well. To get the ultimate in network connectivity, there are also plans to implement a scanner application in Java, making it possible to control your scanner from your favorite Java-enabled web browser.
In the long term, it would be interesting to generalize SANE to embrace other multimedia devices including audio sources or video tape recorders.
In other words, SANE has just started, and there are many exciting projects to come. If you're interested in pursuing some of these by all means get in touch with other developers through the SANE mailing list (see Resources).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}